 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning for Fair Representations
Paper and Code
Sep 22, 2021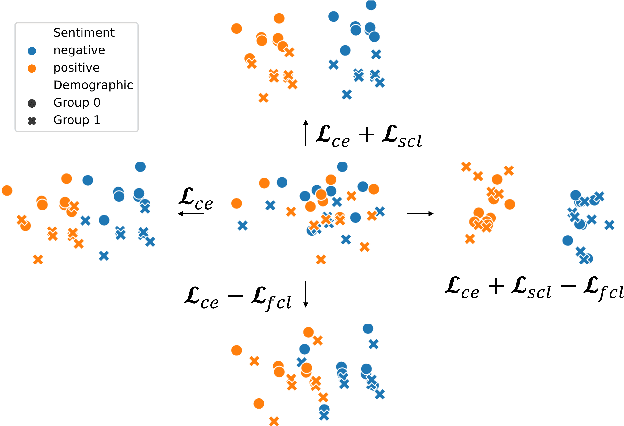
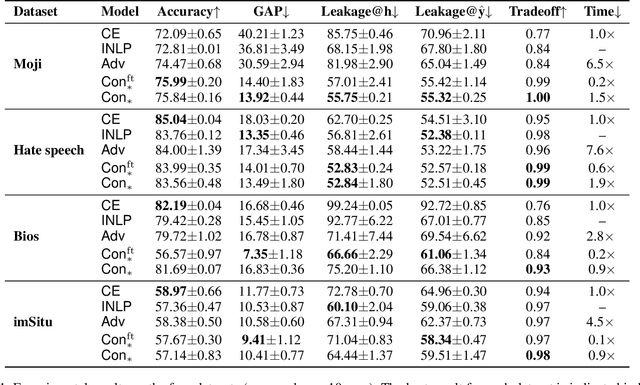
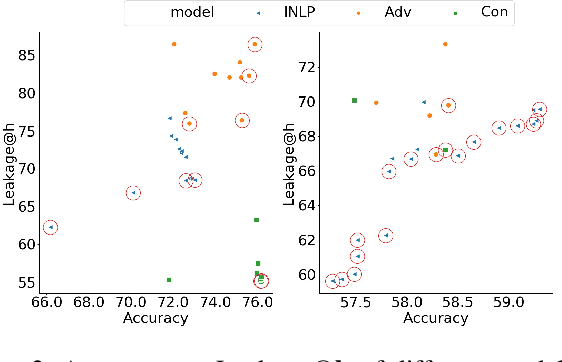
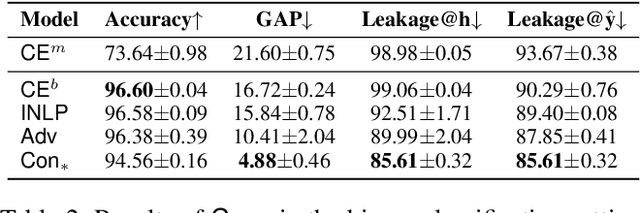
Trained classification models can unintentionally lead to biased representations and predictions, which can reinforce societal preconceptions and stereotypes. Existing debiasing methods for classification models, such as adversarial training, are often expensive to train and difficult to optimise. In this paper, we propose a method for mitigating bias in classifier training by incorporating contrastive learning, in which instances sharing the same class label are encouraged to have similar representations, while instances sharing a protected attribute are forced further apart. In such a way our method learns representations which capture the task label in focused regions, while ensuring the protected attribute has diverse spread, and thus has limited impact on prediction and thereby results in fairer models. Extensive experimental results across four tasks in NLP and computer vision show (a) that our proposed method can achieve fairer representations and realises bias reductions compared with competitive baselines; and (b) that it can do so without sacrificing main task performance; (c) that it sets a new state-of-the-art performance in one task despite reducing the bias. Finally, our method is conceptually simple and agnostic to network architectures, and incurs minimal additional compute cost.