 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Evaluation of Predictive Fairness
Paper and Code
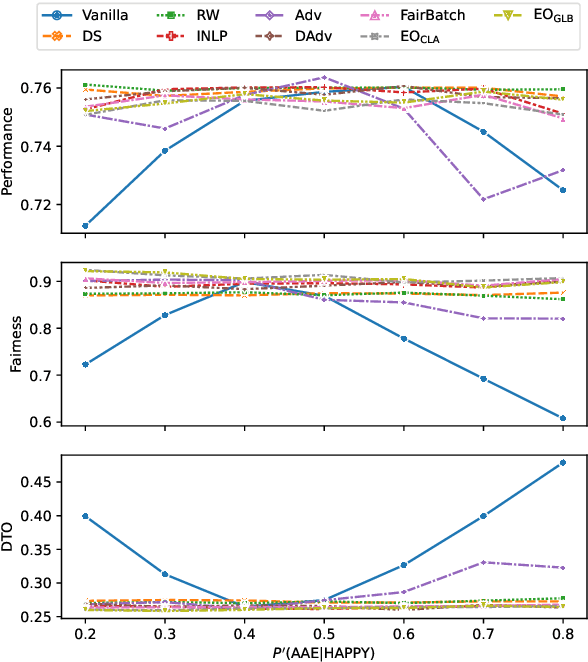
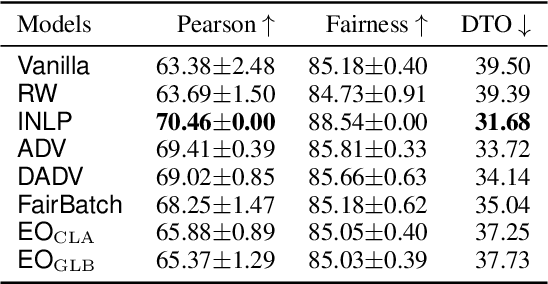
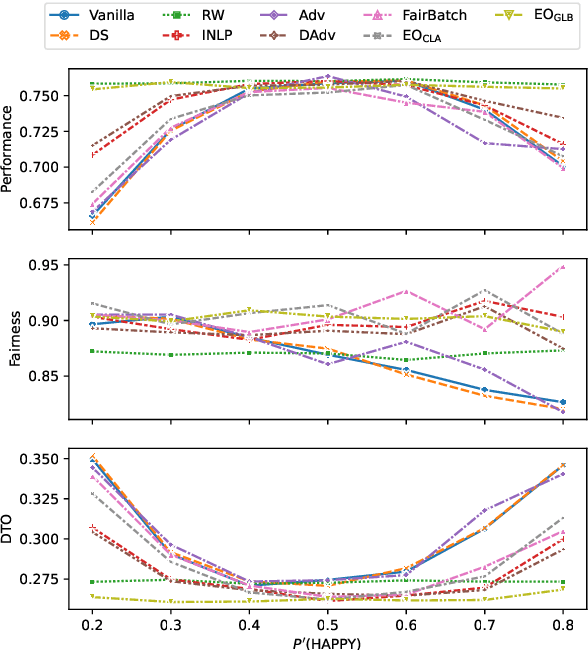
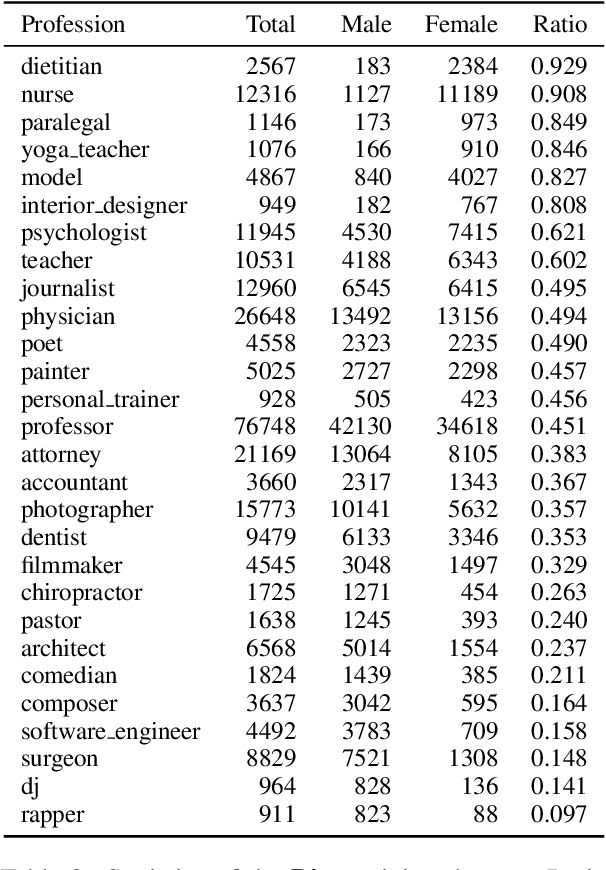
Mitigating bias in training on biased datasets is an important open problem. Several techniques have been proposed, however the typical evaluation regime is very limited, considering very narrow data conditions. For instance, the effect of target class imbalance and stereotyping is under-studied. To address this gap, we examine the performance of various debiasing methods across multiple tasks, spanning binary classification (Twitter sentiment), multi-class classification (profession prediction), and regression (valence prediction). Through extensive experimentation, we find that data conditions have a strong influence on relative model performance, and that general conclusions cannot be drawn about method efficacy when evaluating only on standard datasets, as is current practice in fairness research.