 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Document Coherence Modelling
Paper and Code
Mar 18, 2021
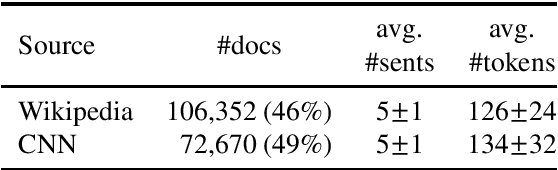

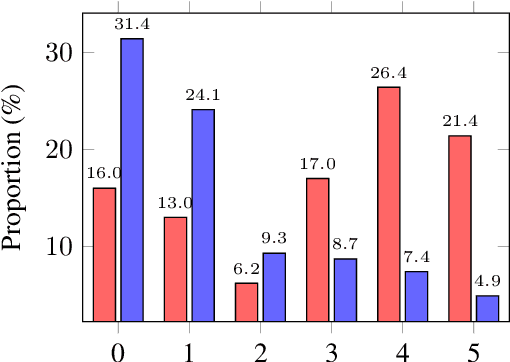
While pretrained language models ("LM") have driven impressive gains over morpho-syntactic and semantic tasks, their ability to model discourse and pragmatic phenomena is less clear. As a step towards a better understanding of their discourse modelling capabilities, we propose a sentence intrusion detection task. We examine the performance of a broad range of pretrained LMs on this detection task for English. Lacking a dataset for the task, we introduce INSteD, a novel intruder sentence detection dataset, containing 170,000+ documents constructed from English Wikipedia and CNN news articles. Our experiments show that pretrained LMs perform impressively in in-domain evaluation, but experience a substantial drop in the cross-domain setting, indicating limited generalisation capacity. Further results over a novel linguistic probe dataset show that there is substantial room for improvement, especially in the cross-domain setting.