 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf Rewarding Self Improving
May 12, 2025

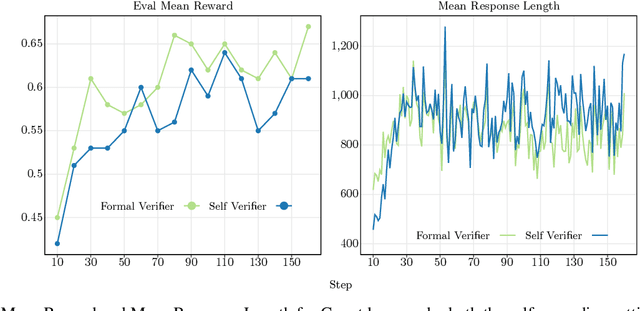
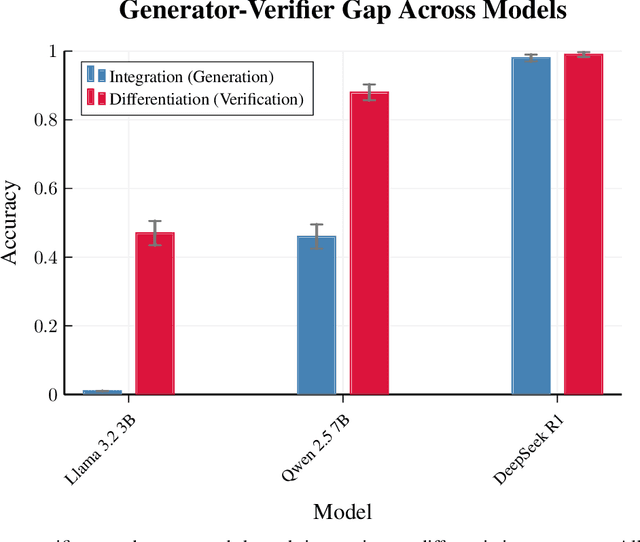
We demonstrate that large language models can effectively self-improve through self-judging without requiring reference solutions, leveraging the inherent asymmetry between generating and verifying solutions. Our experiments on Countdown puzzles and MIT Integration Bee problems show that models can provide reliable reward signals without ground truth answers, enabling reinforcement learning in domains previously not possible. By implementing self-judging, we achieve significant performance gains maintaining alignment with formal verification. When combined with synthetic question generation, we establish a complete self-improvement loop where models generate practice problems, solve them, and evaluate their own performance-achieving an 8% improvement with Qwen 2.5 7B over baseline and surpassing GPT-4o performance on integration tasks. Our findings demonstrate that LLM judges can provide effective reward signals for training models, unlocking many reinforcement learning environments previously limited by the difficulty of creating programmatic rewards. This suggests a potential paradigm shift toward AI systems that continuously improve through self-directed learning rather than human-guided training, potentially accelerating progress in domains with scarce training data or complex evaluation requirements.
LLMs for Engineering: Teaching Models to Design High Powered Rockets
Apr 29, 2025Large Language Models (LLMs) have transformed software engineering, but their application to physical engineering domains remains underexplored. This paper evaluates LLMs' capabilities in high-powered rocketry design through RocketBench, a benchmark connecting LLMs to high-fidelity rocket simulations. We test models on two increasingly complex design tasks: target altitude optimization and precision landing challenges. Our findings reveal that while state-of-the-art LLMs demonstrate strong baseline engineering knowledge, they struggle to iterate on their designs when given simulation results and ultimately plateau below human performance levels. However, when enhanced with reinforcement learning (RL), we show that a 7B parameter model outperforms both SoTA foundation models and human experts. This research demonstrates that RL-trained LLMs can serve as effective tools for complex engineering optimization, potentially transforming engineering domains beyond software development.
REL: Working out is all you need
Dec 05, 2024



Recent developments, particularly OpenAI's O1 model, have demonstrated the remarkable potential of Large Language Models (LLMs) for complex reasoning tasks. Through analysis of O1's outputs and provided sample Chain-of-Thought (CoT) demonstrations, we observe that it approaches problem-solving in a distinctly human-like manner, systematically brainstorming ideas, testing hypotheses, verifying results, and planning comprehensive solutions. These sophisticated reasoning capabilities remain notably absent in other state-of-the-art language models. In this paper, we hypothesize that this performance gap stems from the limited availability of high-quality reasoning process data in current training sets. We demonstrate that by constructing a specialized dataset focused on explicit problem-solving workflows ("worked solutions"), we can elicit substantially improved planning capabilities from existing models. Additionally, we propose the Reasoning Enhancement Loop (REL), a method for generating synthetic worked solutions.
MoDEM: Mixture of Domain Expert Models
Oct 09, 2024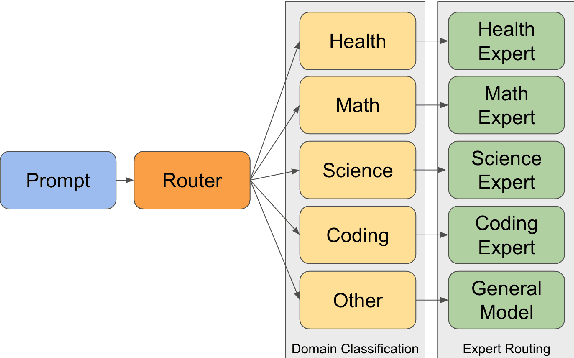

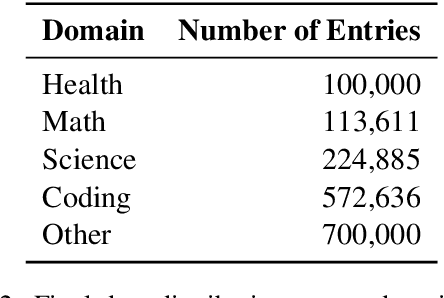
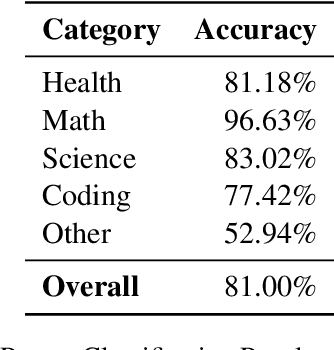
We propose a novel approach to enhancing the performance and efficiency of large language models (LLMs) by combining domain prompt routing with domain-specialized models. We introduce a system that utilizes a BERT-based router to direct incoming prompts to the most appropriate domain expert model. These expert models are specifically tuned for domains such as health, mathematics and science. Our research demonstrates that this approach can significantly outperform general-purpose models of comparable size, leading to a superior performance-to-cost ratio across various benchmarks. The implications of this study suggest a potential paradigm shift in LLM development and deployment. Rather than focusing solely on creating increasingly large, general-purpose models, the future of AI may lie in developing ecosystems of smaller, highly specialized models coupled with sophisticated routing systems. This approach could lead to more efficient resource utilization, reduced computational costs, and superior overall performance.