 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVicious Classifiers: Data Reconstruction Attack at Inference Time
Paper and Code
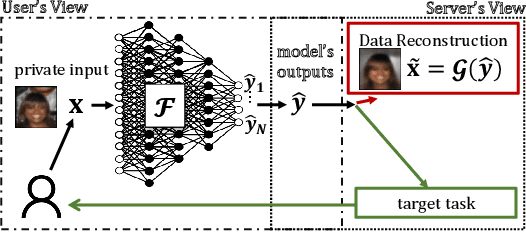
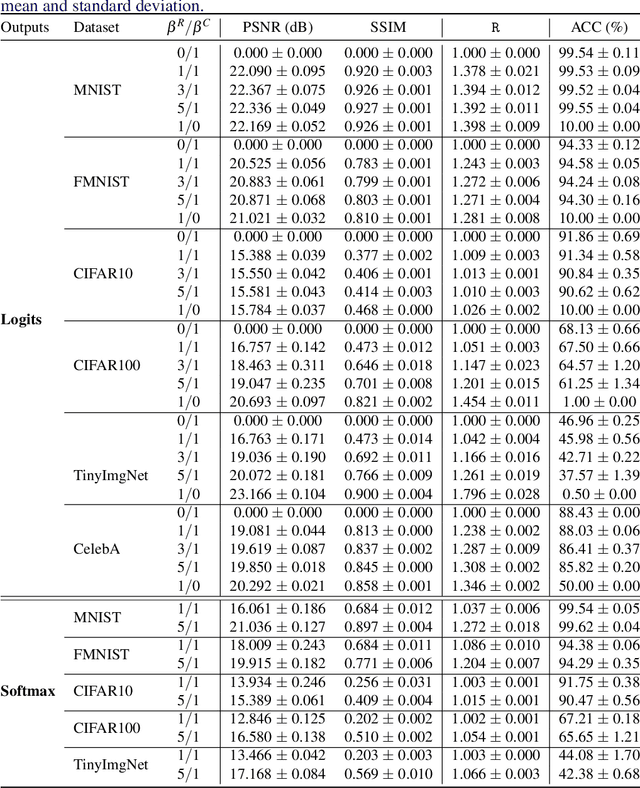
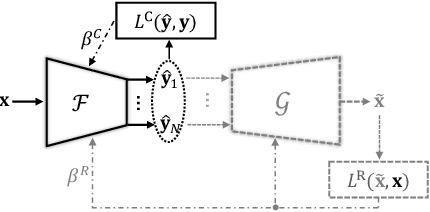
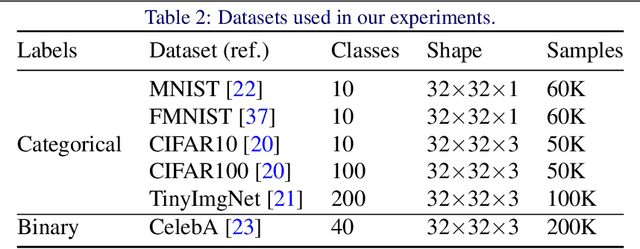
Privacy-preserving inference via edge or encrypted computing paradigms encourages users of machine learning services to confidentially run a model on their personal data for a target task and only share the model's outputs with the service provider; e.g., to activate further services. Nevertheless, despite all confidentiality efforts, we show that a ''vicious'' service provider can approximately reconstruct its users' personal data by observing only the model's outputs, while keeping the target utility of the model very close to that of a ''honest'' service provider. We show the possibility of jointly training a target model (to be run at users' side) and an attack model for data reconstruction (to be secretly used at server's side). We introduce the ''reconstruction risk'': a new measure for assessing the quality of reconstructed data that better captures the privacy risk of such attacks. Experimental results on 6 benchmark datasets show that for low-complexity data types, or for tasks with larger number of classes, a user's personal data can be approximately reconstructed from the outputs of a single target inference task. We propose a potential defense mechanism that helps to distinguish vicious vs. honest classifiers at inference time. We conclude this paper by discussing current challenges and open directions for future studies. We open-source our code and results, as a benchmark for future work.