 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIEW: Visual Imitation Learning with Waypoints
Apr 27, 2024



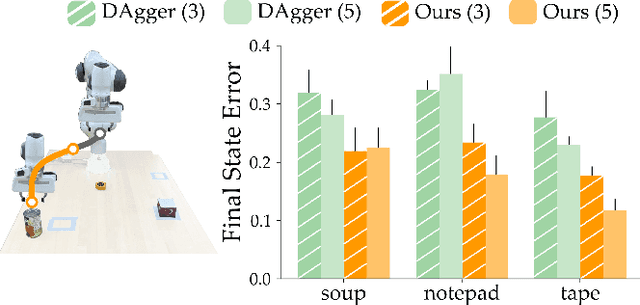
Robots can use Visual Imitation Learning (VIL) to learn everyday tasks from video demonstrations. However, translating visual observations into actionable robot policies is challenging due to the high-dimensional nature of video data. This challenge is further exacerbated by the morphological differences between humans and robots, especially when the video demonstrations feature humans performing tasks. To address these problems we introduce Visual Imitation lEarning with Waypoints (VIEW), an algorithm that significantly enhances the sample efficiency of human-to-robot VIL. VIEW achieves this efficiency using a multi-pronged approach: extracting a condensed prior trajectory that captures the demonstrator's intent, employing an agent-agnostic reward function for feedback on the robot's actions, and utilizing an exploration algorithm that efficiently samples around waypoints in the extracted trajectory. VIEW also segments the human trajectory into grasp and task phases to further accelerate learning efficiency. Through comprehensive simulations and real-world experiments, VIEW demonstrates improved performance compared to current state-of-the-art VIL methods. VIEW enables robots to learn a diverse range of manipulation tasks involving multiple objects from arbitrarily long video demonstrations. Additionally, it can learn standard manipulation tasks such as pushing or moving objects from a single video demonstration in under 30 minutes, with fewer than 20 real-world rollouts. Code and videos here: https://collab.me.vt.edu/view/
Learning to Share Autonomy from Repeated Human-Robot Interaction
May 19, 2022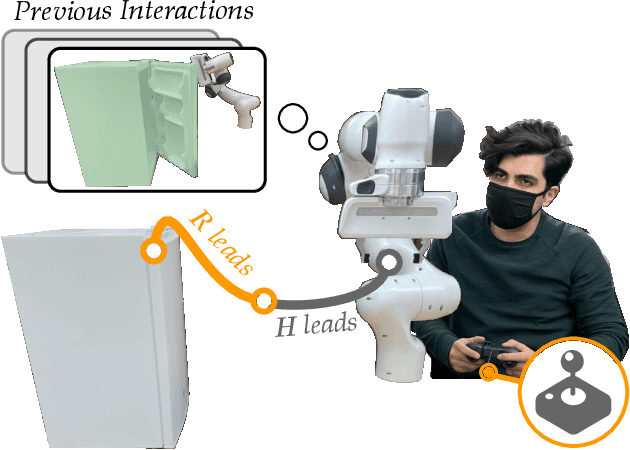


Assistive robot arms try to help their users perform everyday tasks. One way robots can provide this assistance is shared autonomy. Within shared autonomy, both the human and robot maintain control over the robot's motion: as the robot becomes confident it understands what the human wants, it intervenes to automate the task. But how does the robot know these tasks in the first place? State-of-the-art approaches to shared autonomy often rely on prior knowledge. For instance, the robot may need to know the human's potential goals beforehand. During long-term interaction these methods will inevitably break down -- sooner or later the human will attempt to perform a task that the robot does not expect. Accordingly, in this paper we formulate an alternate approach to shared autonomy that learns assistance from scratch. Our insight is that operators repeat important tasks on a daily basis (e.g., opening the fridge, making coffee). Instead of relying prior knowledge, we therefore take advantage of these repeated interactions to learn assistive policies. We formalize an algorithm that recognizes the human's task, replicates similar demonstrations, and returns control when unsure. We then combine learning with control to demonstrate that the error of our approach is uniformly ultimately bounded. We perform simulations to support this error bound, compare our approach to imitation learning baselines, and explore its capacity to assist for an increasing number of tasks. Finally, we conduct a user study with industry-standard methods and shared autonomy baselines. Our results indicate that learning shared autonomy across repeated interactions (SARI) matches existing approaches for known goals, and outperforms the baselines on tasks that were never specified beforehand.
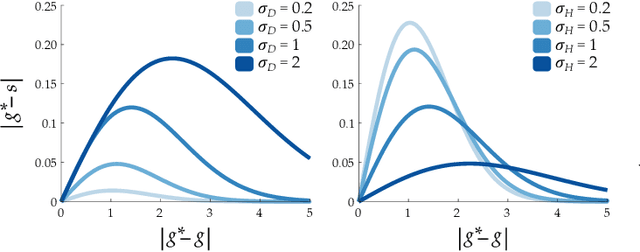
Communicating Robot Conventions through Shared Autonomy
Mar 03, 2022

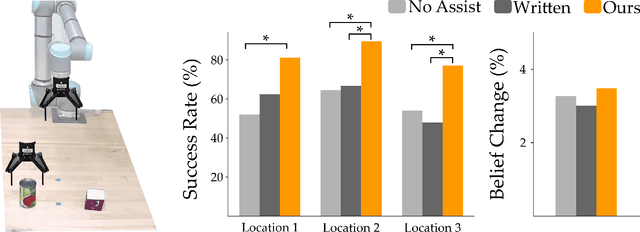
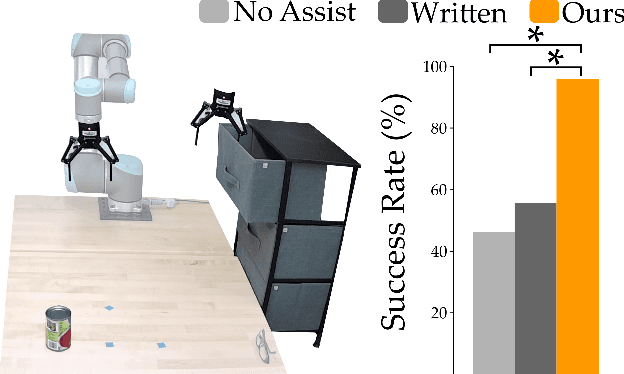
When humans control robot arms these robots often need to infer the human's desired task. Prior research on assistive teleoperation and shared autonomy explores how robots can determine the desired task based on the human's joystick inputs. In order to perform this inference the robot relies on an internal mapping between joystick inputs and discrete tasks: e.g., pressing the joystick left indicates that the human wants a plate, while pressing the joystick right indicates a cup. This approach works well after the human understands how the robot interprets their inputs -- but inexperienced users still have to learn these mappings through trial and error! Here we recognize that the robot's mapping between tasks and inputs is a convention. There are multiple, equally efficient conventions that the robot could use: rather than passively waiting for the human, we introduce a shared autonomy approach where the robot actively reveals its chosen convention. Across repeated interactions the robot intervenes and exaggerates the arm's motion to demonstrate more efficient inputs while also assisting for the current task. We compare this approach to a state-of-the-art baseline -- where users must identify the convention by themselves -- as well as written instructions. Our user study results indicate that modifying the robot's behavior to reveal its convention outperforms the baselines and reduces the amount of time that humans spend controlling the robot. See videos of our user study here: https://youtu.be/jROTVOp469I
Learning to Share Autonomy Across Repeated Interaction
Jul 20, 2021

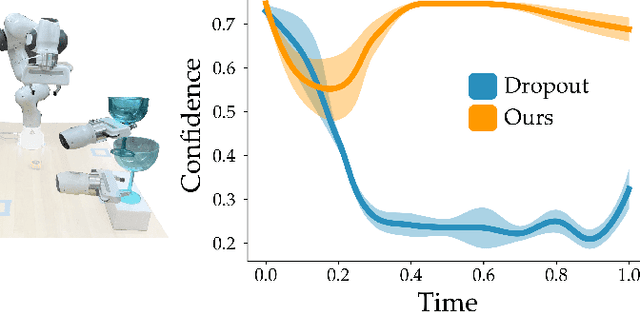
Wheelchair-mounted robotic arms (and other assistive robots) should help their users perform everyday tasks. One way robots can provide this assistance is shared autonomy. Within shared autonomy, both the human and robot maintain control over the robot's motion: as the robot becomes confident it understands what the human wants, it increasingly intervenes to automate the task. But how does the robot know what tasks the human may want to perform in the first place? Today's shared autonomy approaches often rely on prior knowledge: for example, the robot must know the set of possible human goals a priori. In the long-term, however, this prior knowledge will inevitably break down -- sooner or later the human will reach for a goal that the robot did not expect. In this paper we propose a learning approach to shared autonomy that takes advantage of repeated interactions. Learning to assist humans would be impossible if they performed completely different tasks at every interaction: but our insight is that users living with physical disabilities repeat important tasks on a daily basis (e.g., opening the fridge, making coffee, and having dinner). We introduce an algorithm that exploits these repeated interactions to recognize the human's task, replicate similar demonstrations, and return control when unsure. As the human repeatedly works with this robot, our approach continually learns to assist tasks that were never specified beforehand: these tasks include both discrete goals (e.g., reaching a cup) and continuous skills (e.g., opening a drawer). Across simulations and an in-person user study, we demonstrate that robots leveraging our approach match existing shared autonomy methods for known goals, and outperform imitation learning baselines on new tasks. See videos here: https://youtu.be/NazeLVbQ2og
Here's What I've Learned: Asking Questions that Reveal Reward Learning
Jul 02, 2021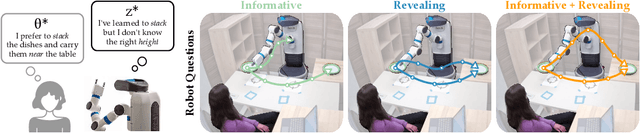

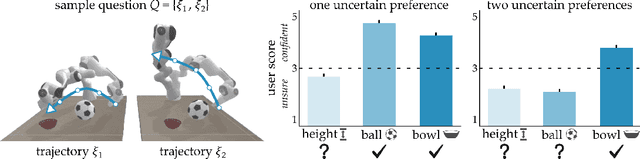
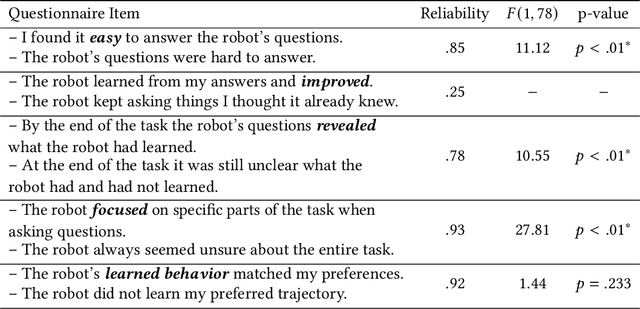
Robots can learn from humans by asking questions. In these questions the robot demonstrates a few different behaviors and asks the human for their favorite. But how should robots choose which questions to ask? Today's robots optimize for informative questions that actively probe the human's preferences as efficiently as possible. But while informative questions make sense from the robot's perspective, human onlookers often find them arbitrary and misleading. In this paper we formalize active preference-based learning from the human's perspective. We hypothesize that -- from the human's point-of-view -- the robot's questions reveal what the robot has and has not learned. Our insight enables robots to use questions to make their learning process transparent to the human operator. We develop and test a model that robots can leverage to relate the questions they ask to the information these questions reveal. We then introduce a trade-off between informative and revealing questions that considers both human and robot perspectives: a robot that optimizes for this trade-off actively gathers information from the human while simultaneously keeping the human up to date with what it has learned. We evaluate our approach across simulations, online surveys, and in-person user studies. Videos of our user studies and results are available here: https://youtu.be/tC6y_jHN7Vw.
I Know What You Meant: Learning Human Objectives by estimating Their Choice Set
Nov 11, 2020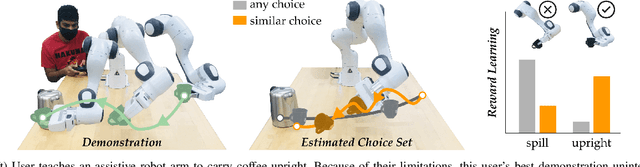
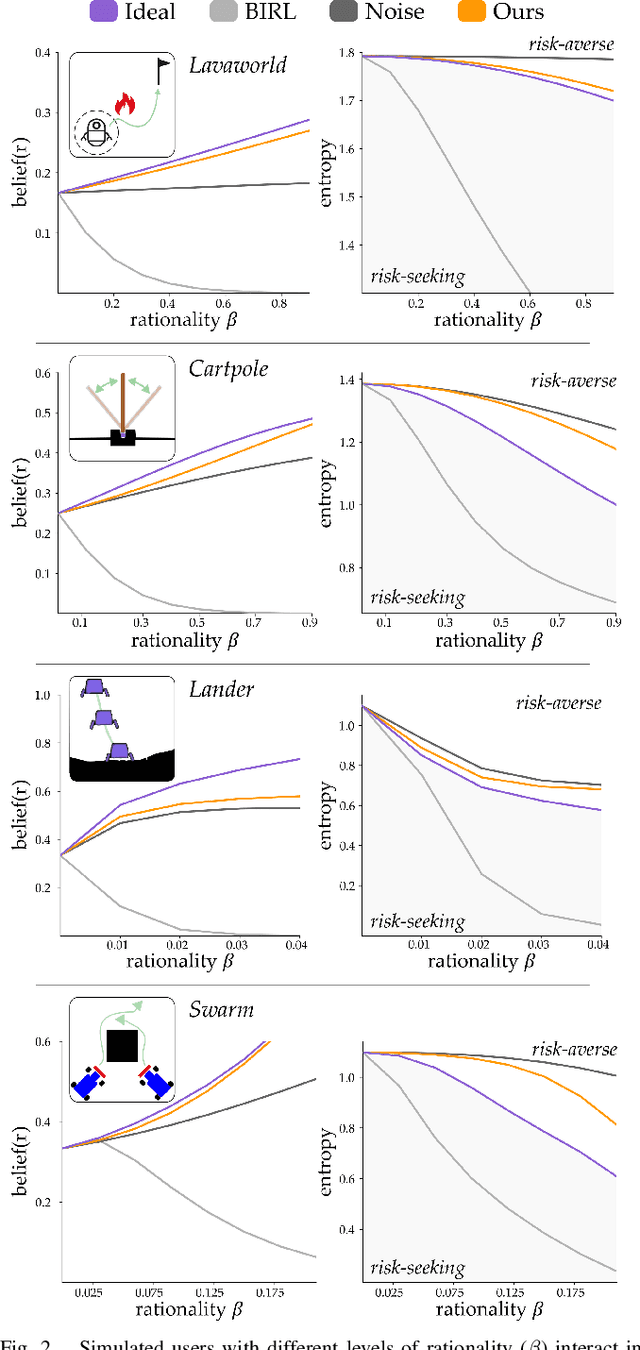
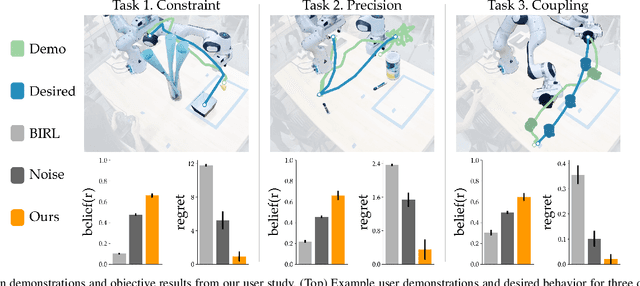

Assistive robots have the potential to help people perform everyday tasks. However, these robots first need to learn what it is their user wants them to do. Teaching assistive robots is hard for inexperienced users, elderly users, and users living with physical disabilities, since often these individuals are unable to teleoperate the robot along their desired behavior. We know that inclusive learners should give human teachers credit for what they cannot demonstrate. But today's robots do the opposite: they assume every user is capable of providing any demonstration. As a result, these robots learn to mimic the demonstrated behavior, even when that behavior isn't what the human really meant! We propose an alternate approach to reward learning: robots that reason about the user's demonstrations in the context of similar or simpler alternatives. Unlike prior works -- which err towards overestimating the human's capabilities -- here we err towards underestimating what the human can input (i.e., their choice set). Our theoretical analysis proves that underestimating the human's choice set is risk-averse, with better worst-case performance than overestimating. We formalize three properties to generate similar and simpler alternatives: across simulations and a user study, our algorithm better enables robots to extrapolate the human's objective. See our user study here: https://youtu.be/RgbH2YULVRo