 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Know What You Meant: Learning Human Objectives by estimating Their Choice Set
Paper and Code
Nov 11, 2020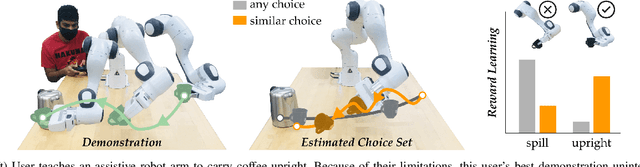
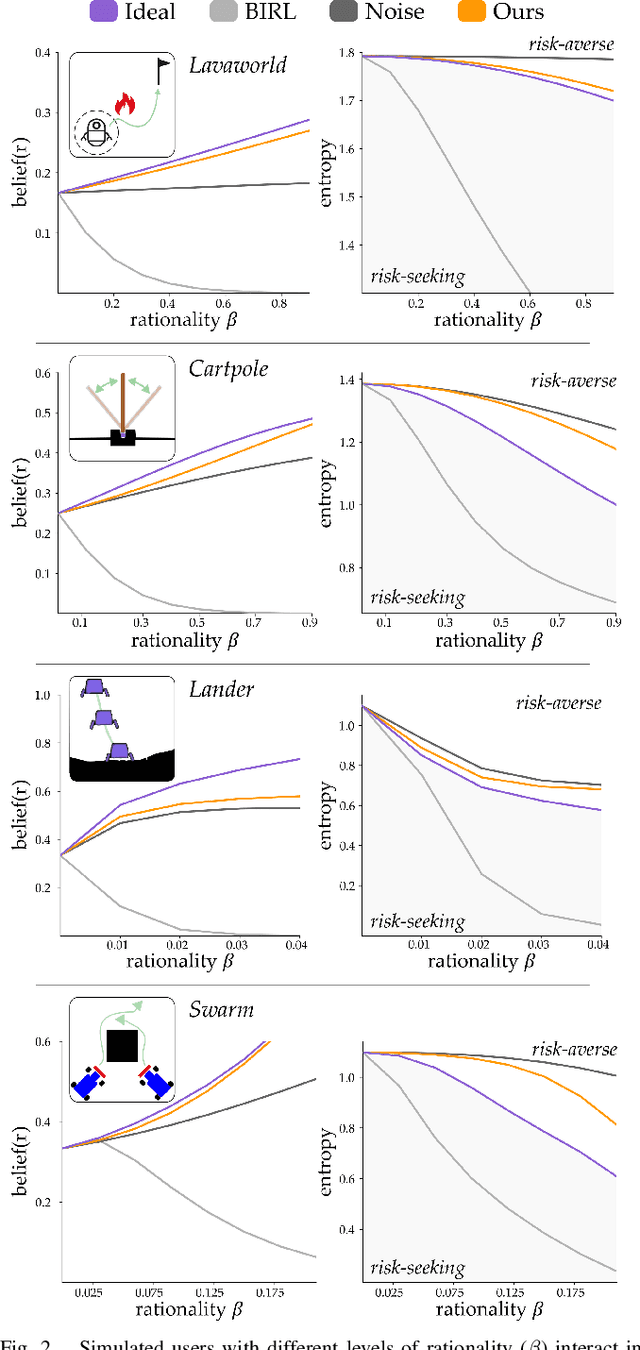
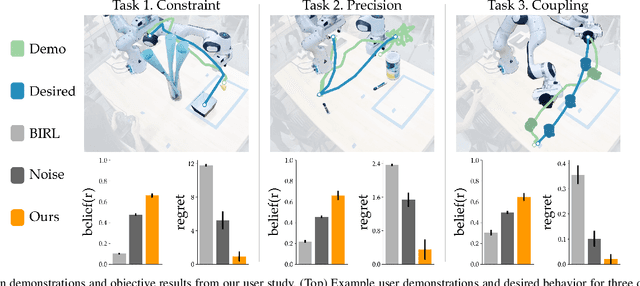

Assistive robots have the potential to help people perform everyday tasks. However, these robots first need to learn what it is their user wants them to do. Teaching assistive robots is hard for inexperienced users, elderly users, and users living with physical disabilities, since often these individuals are unable to teleoperate the robot along their desired behavior. We know that inclusive learners should give human teachers credit for what they cannot demonstrate. But today's robots do the opposite: they assume every user is capable of providing any demonstration. As a result, these robots learn to mimic the demonstrated behavior, even when that behavior isn't what the human really meant! We propose an alternate approach to reward learning: robots that reason about the user's demonstrations in the context of similar or simpler alternatives. Unlike prior works -- which err towards overestimating the human's capabilities -- here we err towards underestimating what the human can input (i.e., their choice set). Our theoretical analysis proves that underestimating the human's choice set is risk-averse, with better worst-case performance than overestimating. We formalize three properties to generate similar and simpler alternatives: across simulations and a user study, our algorithm better enables robots to extrapolate the human's objective. See our user study here: https://youtu.be/RgbH2YULVRo