 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonte-Carlo Tree Search for Policy Optimization
Paper and Code
Dec 23, 2019
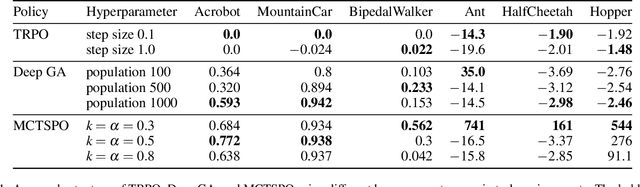
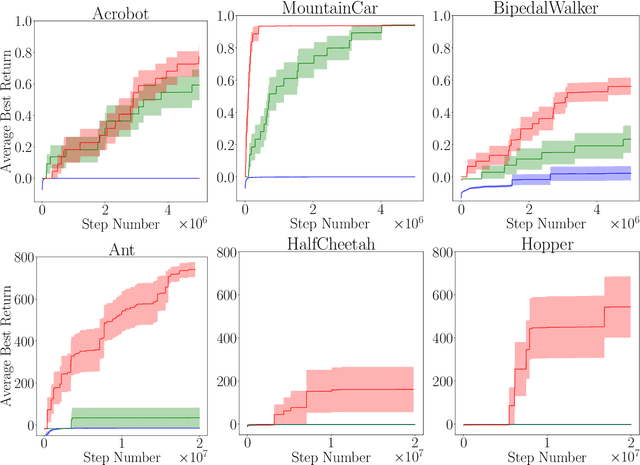
Gradient-based methods are often used for policy optimization in deep reinforcement learning, despite being vulnerable to local optima and saddle points. Although gradient-free methods (e.g., genetic algorithms or evolution strategies) help mitigate these issues, poor initialization and local optima are still concerns in highly nonconvex spaces. This paper presents a method for policy optimization based on Monte-Carlo tree search and gradient-free optimization. Our method, called Monte-Carlo tree search for policy optimization (MCTSPO), provides a better exploration-exploitation trade-off through the use of the upper confidence bound heuristic. We demonstrate improved performance on reinforcement learning tasks with deceptive or sparse reward functions compared to popular gradient-based and deep genetic algorithm baselines.