 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization Trade-offs in Asynchronous Federated Learning: A Stochastic Networks Approach
Mar 27, 2026Synchronous federated learning scales poorly due to the straggler effect. Asynchronous algorithms increase the update throughput by processing updates upon arrival, but they introduce two fundamental challenges: gradient staleness, which degrades convergence, and bias toward faster clients under heterogeneous data distributions. Although algorithms such as AsyncSGD and Generalized AsyncSGD mitigate this bias via client-side task queues, most existing analyses neglect the underlying queueing dynamics and lack closed-form characterizations of the update throughput and gradient staleness. To close this gap, we develop a stochastic queueing-network framework for Generalized AsyncSGD that jointly models random computation times at the clients and the central server, as well as random uplink and downlink communication delays. Leveraging product-form network theory, we derive a closed-form expression for the update throughput, alongside closed-form upper bounds for both the communication round complexity and the expected wall-clock time required to reach an $ε$-stationary point. These results formally characterize the trade-off between gradient staleness and wall-clock convergence speed. We further extend the framework to quantify energy consumption under stochastic timing, revealing an additional trade-off between convergence speed and energy efficiency. Building on these analytical results, we propose gradient-based optimization strategies to jointly optimize routing and concurrency. Experiments on EMNIST demonstrate reductions of 29%--46% in convergence time and 36%--49% in energy consumption compared to AsyncSGD.
$K-$means with learned metrics
Mar 15, 2026We study the Fréchet {\it k-}means of a metric measure space when both the measure and the distance are unknown and have to be estimated. We prove a general result that states that the {\it k-}means are continuous with respect to the measured Gromov-Hausdorff topology. In this situation, we also prove a stability result for the Voronoi clusters they determine. We do not assume uniqueness of the set of {\it k-}means, but when it is unique, the results are stronger. {This framework provides a unified approach to proving consistency for a wide range of metric learning procedures. As concrete applications, we obtain new consistency results for several important estimators that were previously unestablished, even when $k=1$. These include {\it k-}means based on: (i) Isomap and Fermat geodesic distances on manifolds, (ii) difussion distances, (iii) Wasserstein distances computed with respect to learned ground metrics. Finally, we consider applications beyond the statistical inference paradigm like (iv) first passage percolation and (v) discrete approximations of length spaces.}
Probabilistic Insights for Efficient Exploration Strategies in Reinforcement Learning
Mar 05, 2025
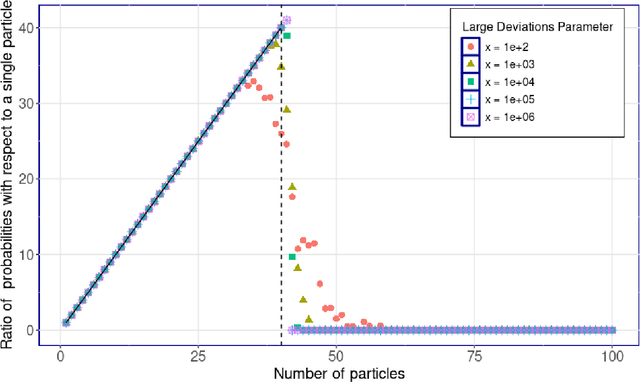
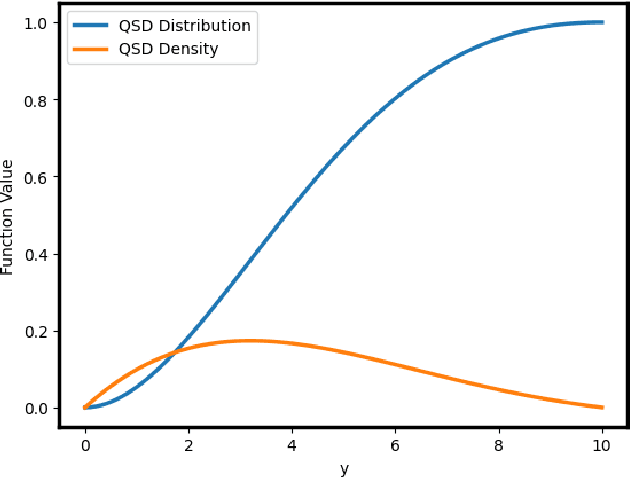
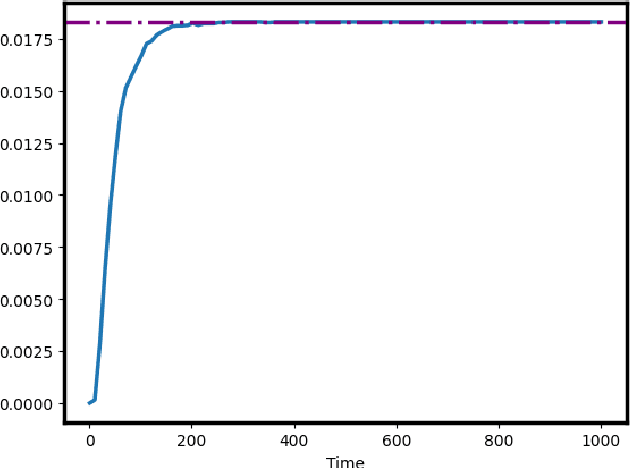
We investigate efficient exploration strategies of environments with unknown stochastic dynamics and sparse rewards. Specifically, we analyze first the impact of parallel simulations on the probability of reaching rare states within a finite time budget. Using simplified models based on random walks and L\'evy processes, we provide analytical results that demonstrate a phase transition in reaching probabilities as a function of the number of parallel simulations. We identify an optimal number of parallel simulations that balances exploration diversity and time allocation. Additionally, we analyze a restarting mechanism that exponentially enhances the probability of success by redirecting efforts toward more promising regions of the state space. Our findings contribute to a more qualitative and quantitative theory of some exploration schemes in reinforcement learning, offering insights into developing more efficient strategies for environments characterized by rare events.
Optimizing Asynchronous Federated Learning: A Delicate Trade-Off Between Model-Parameter Staleness and Update Frequency
Feb 12, 2025



Synchronous federated learning (FL) scales poorly with the number of clients due to the straggler effect. Algorithms like FedAsync and GeneralizedFedAsync address this limitation by enabling asynchronous communication between clients and the central server. In this work, we rely on stochastic modeling to better understand the impact of design choices in asynchronous FL algorithms, such as the concurrency level and routing probabilities, and we leverage this knowledge to optimize loss. We characterize in particular a fundamental trade-off for optimizing asynchronous FL: minimizing gradient estimation errors by avoiding model parameter staleness, while also speeding up the system by increasing the throughput of model updates. Our two main contributions can be summarized as follows. First, we prove a discrete variant of Little's law to derive a closed-form expression for relative delay, a metric that quantifies staleness. This allows us to efficiently minimize the average loss per model update, which has been the gold standard in literature to date. Second, we observe that naively optimizing this metric leads us to slow down the system drastically by overemphazing staleness at the detriment of throughput. This motivates us to introduce an alternative metric that also takes system speed into account, for which we derive a tractable upper-bound that can be minimized numerically. Extensive numerical results show that these optimizations enhance accuracy by 10% to 30%.
Score-Aware Policy-Gradient Methods and Performance Guarantees using Local Lyapunov Conditions: Applications to Product-Form Stochastic Networks and Queueing Systems
Dec 05, 2023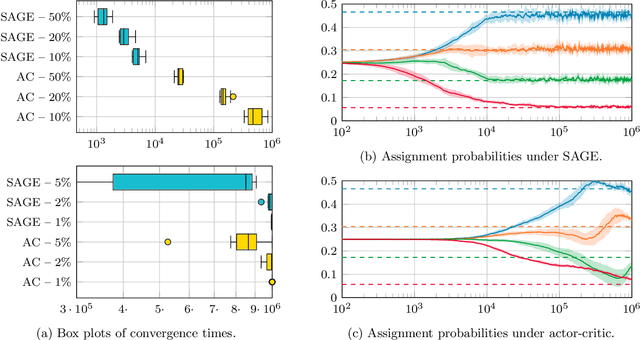
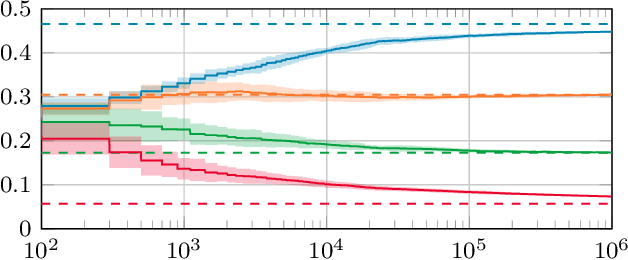
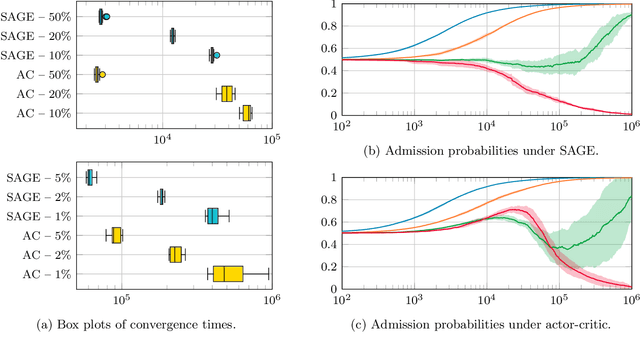
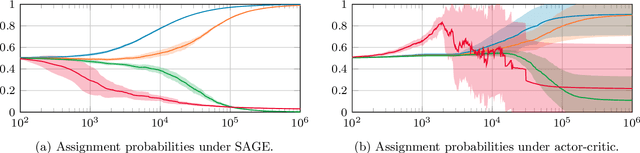
Stochastic networks and queueing systems often lead to Markov decision processes (MDPs) with large state and action spaces as well as nonconvex objective functions, which hinders the convergence of many reinforcement learning (RL) algorithms. Policy-gradient methods perform well on MDPs with large state and action spaces, but they sometimes experience slow convergence due to the high variance of the gradient estimator. In this paper, we show that some of these difficulties can be circumvented by exploiting the structure of the underlying MDP. We first introduce a new family of gradient estimators called score-aware gradient estimators (SAGEs). When the stationary distribution of the MDP belongs to an exponential family parametrized by the policy parameters, SAGEs allow us to estimate the policy gradient without relying on value-function estimation, contrary to classical policy-gradient methods like actor-critic. To demonstrate their applicability, we examine two common control problems arising in stochastic networks and queueing systems whose stationary distributions have a product-form, a special case of exponential families. As a second contribution, we show that, under appropriate assumptions, the policy under a SAGE-based policy-gradient method has a large probability of converging to an optimal policy, provided that it starts sufficiently close to it, even with a nonconvex objective function and multiple maximizers. Our key assumptions are that, locally around a maximizer, a nondegeneracy property of the Hessian of the objective function holds and a Lyapunov function exists. Finally, we conduct a numerical comparison between a SAGE-based policy-gradient method and an actor-critic algorithm. The results demonstrate that the SAGE-based method finds close-to-optimal policies more rapidly, highlighting its superior performance over the traditional actor-critic method.
Choosing the parameter of the Fermat distance: navigating geometry and noise
Nov 30, 2023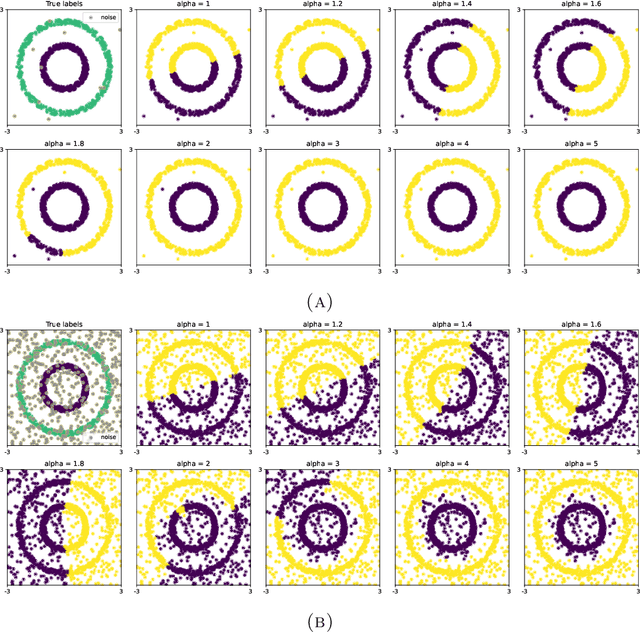
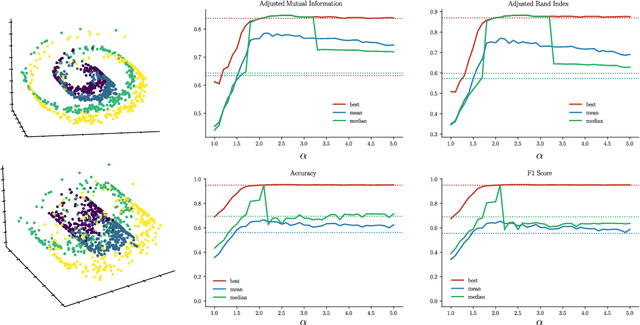
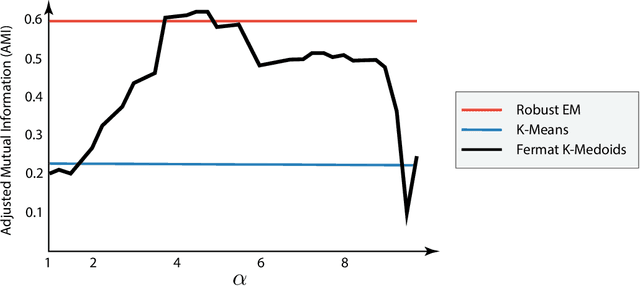
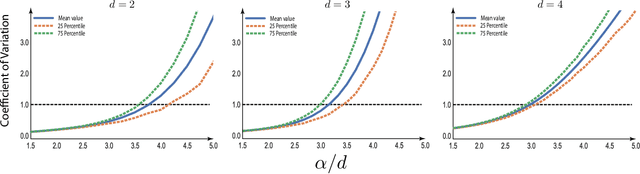
The Fermat distance has been recently established as a useful tool for machine learning tasks when a natural distance is not directly available to the practitioner or to improve the results given by Euclidean distances by exploding the geometrical and statistical properties of the dataset. This distance depends on a parameter $\alpha$ that greatly impacts the performance of subsequent tasks. Ideally, the value of $\alpha$ should be large enough to navigate the geometric intricacies inherent to the problem. At the same, it should remain restrained enough to sidestep any deleterious ramifications stemming from noise during the process of distance estimation. We study both theoretically and through simulations how to select this parameter.
FEMDA: a unified framework for discriminant analysis
Nov 13, 2023



Although linear and quadratic discriminant analysis are widely recognized classical methods, they can encounter significant challenges when dealing with non-Gaussian distributions or contaminated datasets. This is primarily due to their reliance on the Gaussian assumption, which lacks robustness. We first explain and review the classical methods to address this limitation and then present a novel approach that overcomes these issues. In this new approach, the model considered is an arbitrary Elliptically Symmetrical (ES) distribution per cluster with its own arbitrary scale parameter. This flexible model allows for potentially diverse and independent samples that may not follow identical distributions. By deriving a new decision rule, we demonstrate that maximum-likelihood parameter estimation and classification are simple, efficient, and robust compared to state-of-the-art methods.
Symphony of experts: orchestration with adversarial insights in reinforcement learning
Oct 25, 2023
Structured reinforcement learning leverages policies with advantageous properties to reach better performance, particularly in scenarios where exploration poses challenges. We explore this field through the concept of orchestration, where a (small) set of expert policies guides decision-making; the modeling thereof constitutes our first contribution. We then establish value-functions regret bounds for orchestration in the tabular setting by transferring regret-bound results from adversarial settings. We generalize and extend the analysis of natural policy gradient in Agarwal et al. [2021, Section 5.3] to arbitrary adversarial aggregation strategies. We also extend it to the case of estimated advantage functions, providing insights into sample complexity both in expectation and high probability. A key point of our approach lies in its arguably more transparent proofs compared to existing methods. Finally, we present simulations for a stochastic matching toy model.
FEMDA: Une méthode de classification robuste et flexible
Jul 04, 2023



Linear and Quadratic Discriminant Analysis (LDA and QDA) are well-known classical methods but can heavily suffer from non-Gaussian distributions and/or contaminated datasets, mainly because of the underlying Gaussian assumption that is not robust. This paper studies the robustness to scale changes in the data of a new discriminant analysis technique where each data point is drawn by its own arbitrary Elliptically Symmetrical (ES) distribution and its own arbitrary scale parameter. Such a model allows for possibly very heterogeneous, independent but non-identically distributed samples. The new decision rule derived is simple, fast, and robust to scale changes in the data compared to other state-of-the-art method
Clustering for directed graphs using parametrized random walk diffusion kernels
Oct 01, 2022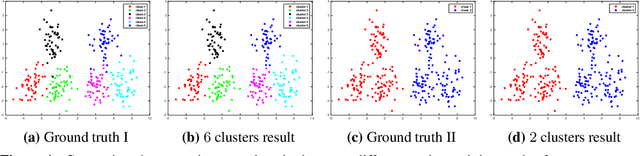
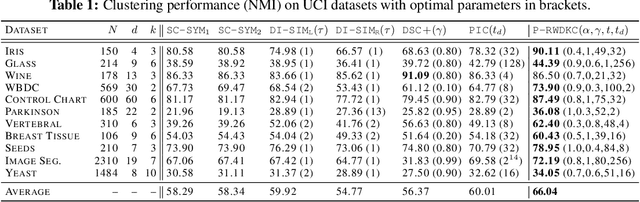

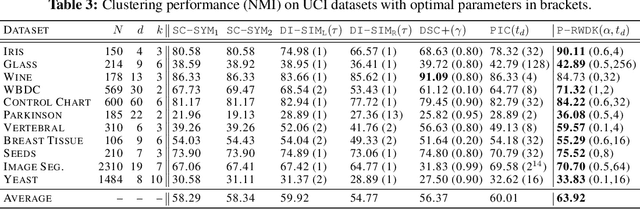
Clustering based on the random walk operator has been proven effective for undirected graphs, but its generalization to directed graphs (digraphs) is much more challenging. Although the random walk operator is well-defined for digraphs, in most cases such graphs are not strongly connected, and hence the associated random walks are not irreducible, which is a crucial property for clustering that exists naturally in the undirected setting. To remedy this, the usual workaround is to either naively symmetrize the adjacency matrix or to replace the natural random walk operator by the teleporting random walk operator, but this can lead to the loss of valuable information carried by edge directionality. In this paper, we introduce a new clustering framework, the Parametrized Random Walk Diffusion Kernel Clustering (P-RWDKC), which is suitable for handling both directed and undirected graphs. Our framework is based on the diffusion geometry and the generalized spectral clustering framework. Accordingly, we propose an algorithm that automatically reveals the cluster structure at a given scale, by considering the random walk dynamics associated with a parametrized kernel operator, and by estimating its critical diffusion time. Experiments on $K$-NN graphs constructed from real-world datasets and real-world graphs show that our clustering approach performs well in all tested cases, and outperforms existing approaches in most of them.