 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Fair Aggregation of Crowdsourced Noisy Labels using Demographic Parity Constraints
Jan 30, 2026As acquiring reliable ground-truth labels is usually costly, or infeasible, crowdsourcing and aggregation of noisy human annotations is the typical resort. Aggregating subjective labels, though, may amplify individual biases, particularly regarding sensitive features, raising fairness concerns. Nonetheless, fairness in crowdsourced aggregation remains largely unexplored, with no existing convergence guarantees and only limited post-processing approaches for enforcing $\varepsilon$-fairness under demographic parity. We address this gap by analyzing the fairness s of crowdsourced aggregation methods within the $\varepsilon$-fairness framework, for Majority Vote and Optimal Bayesian aggregation. In the small-crowd regime, we derive an upper bound on the fairness gap of Majority Vote in terms of the fairness gaps of the individual annotators. We further show that the fairness gap of the aggregated consensus converges exponentially fast to that of the ground-truth under interpretable conditions. Since ground-truth itself may still be unfair, we generalize a state-of-the-art multiclass fairness post-processing algorithm from the continuous to the discrete setting, which enforces strict demographic parity constraints to any aggregation rule. Experiments on synthetic and real datasets demonstrate the effectiveness of our approach and corroborate the theoretical insights.
Cascaded Transfer: Learning Many Tasks under Budget Constraints
Jan 29, 2026Many-Task Learning refers to the setting where a large number of related tasks need to be learned, the exact relationships between tasks are not known. We introduce the Cascaded Transfer Learning, a novel many-task transfer learning paradigm where information (e.g. model parameters) cascades hierarchically through tasks that are learned by individual models of the same class, while respecting given budget constraints. The cascade is organized as a rooted tree that specifies the order in which tasks are learned and refined. We design a cascaded transfer mechanism deployed over a minimum spanning tree structure that connects the tasks according to a suitable distance measure, and allocates the available training budget along its branches. Experiments on synthetic and real many-task settings show that the resulting method enables more accurate and cost effective adaptation across large task collections compared to alternative approaches.
Uncovering Social Network Activity Using Joint User and Topic Interaction
Jun 15, 2025The emergence of online social platforms, such as social networks and social media, has drastically affected the way people apprehend the information flows to which they are exposed. In such platforms, various information cascades spreading among users is the main force creating complex dynamics of opinion formation, each user being characterized by their own behavior adoption mechanism. Moreover, the spread of multiple pieces of information or beliefs in a networked population is rarely uncorrelated. In this paper, we introduce the Mixture of Interacting Cascades (MIC), a model of marked multidimensional Hawkes processes with the capacity to model jointly non-trivial interaction between cascades and users. We emphasize on the interplay between information cascades and user activity, and use a mixture of temporal point processes to build a coupled user/cascade point process model. Experiments on synthetic and real data highlight the benefits of this approach and demonstrate that MIC achieves superior performance to existing methods in modeling the spread of information cascades. Finally, we demonstrate how MIC can provide, through its learned parameters, insightful bi-layered visualizations of real social network activity data.
Leveraging Graph Neural Networks to Forecast Electricity Consumption
Aug 30, 2024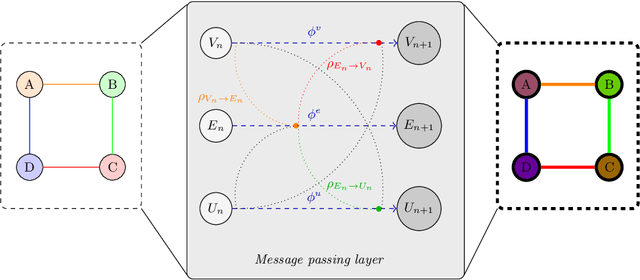
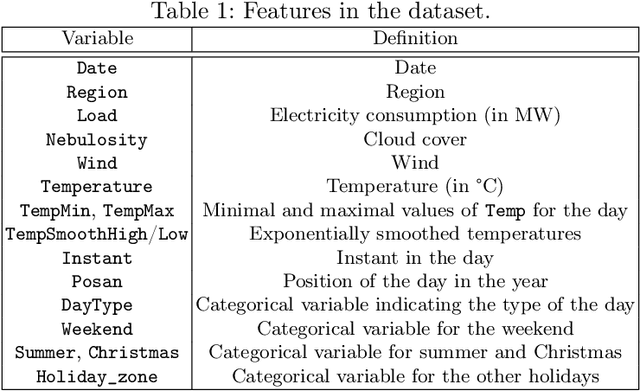
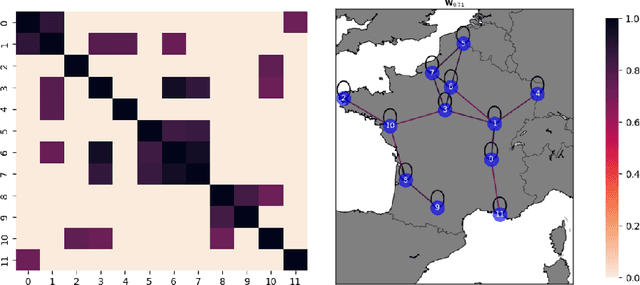
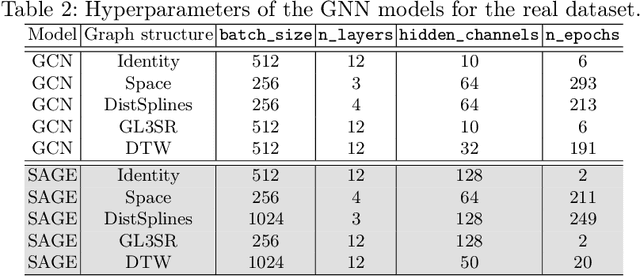
Accurate electricity demand forecasting is essential for several reasons, especially as the integration of renewable energy sources and the transition to a decentralized network paradigm introduce greater complexity and uncertainty. The proposed methodology leverages graph-based representations to effectively capture the spatial distribution and relational intricacies inherent in this decentralized network structure. This research work offers a novel approach that extends beyond the conventional Generalized Additive Model framework by considering models like Graph Convolutional Networks or Graph SAGE. These graph-based models enable the incorporation of various levels of interconnectedness and information sharing among nodes, where each node corresponds to the combined load (i.e. consumption) of a subset of consumers (e.g. the regions of a country). More specifically, we introduce a range of methods for inferring graphs tailored to consumption forecasting, along with a framework for evaluating the developed models in terms of both performance and explainability. We conduct experiments on electricity forecasting, in both a synthetic and a real framework considering the French mainland regions, and the performance and merits of our approach are discussed.
Stein Boltzmann Sampling: A Variational Approach for Global Optimization
Feb 20, 2024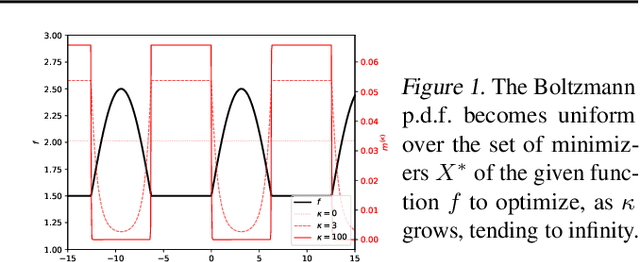
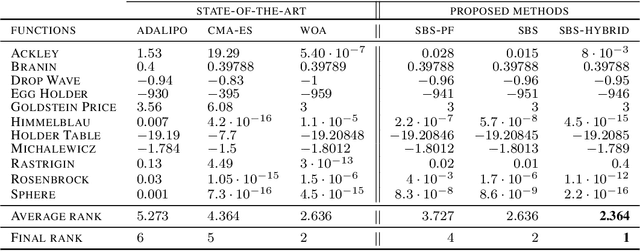
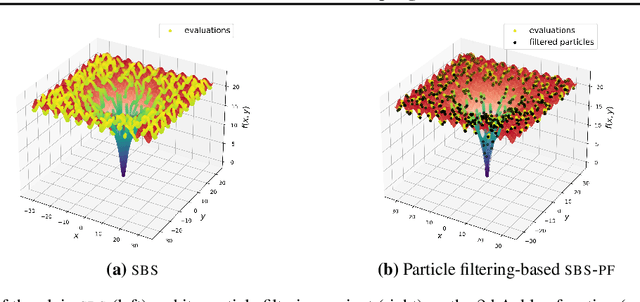
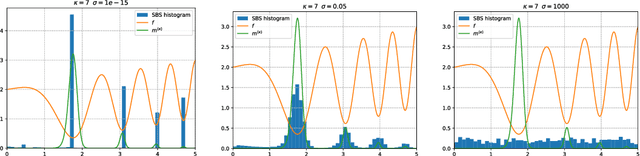
In this paper, we introduce a new flow-based method for global optimization of Lipschitz functions, called Stein Boltzmann Sampling (SBS). Our method samples from the Boltzmann distribution that becomes asymptotically uniform over the set of the minimizers of the function to be optimized. Candidate solutions are sampled via the \emph{Stein Variational Gradient Descent} algorithm. We prove the asymptotic convergence of our method, introduce two SBS variants, and provide a detailed comparison with several state-of-the-art global optimization algorithms on various benchmark functions. The design of our method, the theoretical results, and our experiments, suggest that SBS is particularly well-suited to be used as a continuation of efficient global optimization methods as it can produce better solutions while making a good use of the budget.
Collaborative non-parametric two-sample testing
Feb 08, 2024This paper addresses the multiple two-sample test problem in a graph-structured setting, which is a common scenario in fields such as Spatial Statistics and Neuroscience. Each node $v$ in fixed graph deals with a two-sample testing problem between two node-specific probability density functions (pdfs), $p_v$ and $q_v$. The goal is to identify nodes where the null hypothesis $p_v = q_v$ should be rejected, under the assumption that connected nodes would yield similar test outcomes. We propose the non-parametric collaborative two-sample testing (CTST) framework that efficiently leverages the graph structure and minimizes the assumptions over $p_v$ and $q_v$. Our methodology integrates elements from f-divergence estimation, Kernel Methods, and Multitask Learning. We use synthetic experiments and a real sensor network detecting seismic activity to demonstrate that CTST outperforms state-of-the-art non-parametric statistical tests that apply at each node independently, hence disregard the geometry of the problem.
UniForCE: The Unimodality Forest Method for Clustering and Estimation of the Number of Clusters
Dec 18, 2023Estimating the number of clusters k while clustering the data is a challenging task. An incorrect cluster assumption indicates that the number of clusters k gets wrongly estimated. Consequently, the model fitting becomes less important. In this work, we focus on the concept of unimodality and propose a flexible cluster definition called locally unimodal cluster. A locally unimodal cluster extends for as long as unimodality is locally preserved across pairs of subclusters of the data. Then, we propose the UniForCE method for locally unimodal clustering. The method starts with an initial overclustering of the data and relies on the unimodality graph that connects subclusters forming unimodal pairs. Such pairs are identified using an appropriate statistical test. UniForCE identifies maximal locally unimodal clusters by computing a spanning forest in the unimodality graph. Experimental results on both real and synthetic datasets illustrate that the proposed methodology is particularly flexible and robust in discovering regular and highly complex cluster shapes. Most importantly, it automatically provides an adequate estimation of the number of clusters.
Online non-parametric likelihood-ratio estimation by Pearson-divergence functional minimization
Nov 03, 2023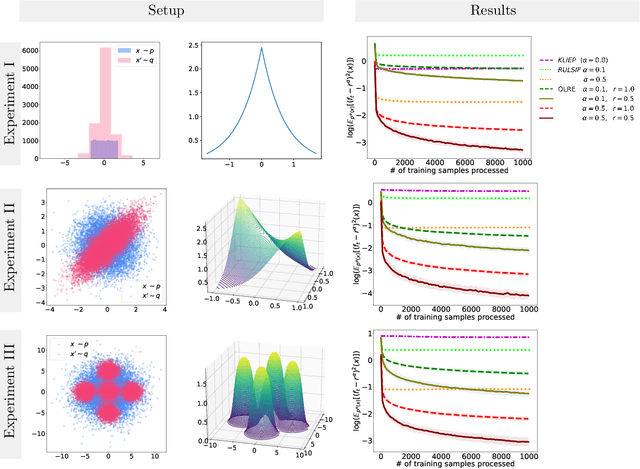
Quantifying the difference between two probability density functions, $p$ and $q$, using available data, is a fundamental problem in Statistics and Machine Learning. A usual approach for addressing this problem is the likelihood-ratio estimation (LRE) between $p$ and $q$, which -- to our best knowledge -- has been investigated mainly for the offline case. This paper contributes by introducing a new framework for online non-parametric LRE (OLRE) for the setting where pairs of iid observations $(x_t \sim p, x'_t \sim q)$ are observed over time. The non-parametric nature of our approach has the advantage of being agnostic to the forms of $p$ and $q$. Moreover, we capitalize on the recent advances in Kernel Methods and functional minimization to develop an estimator that can be efficiently updated online. We provide theoretical guarantees for the performance of the OLRE method along with empirical validation in synthetic experiments.
A framework for paired-sample hypothesis testing for high-dimensional data
Sep 28, 2023The standard paired-sample testing approach in the multidimensional setting applies multiple univariate tests on the individual features, followed by p-value adjustments. Such an approach suffers when the data carry numerous features. A number of studies have shown that classification accuracy can be seen as a proxy for two-sample testing. However, neither theoretical foundations nor practical recipes have been proposed so far on how this strategy could be extended to multidimensional paired-sample testing. In this work, we put forward the idea that scoring functions can be produced by the decision rules defined by the perpendicular bisecting hyperplanes of the line segments connecting each pair of instances. Then, the optimal scoring function can be obtained by the pseudomedian of those rules, which we estimate by extending naturally the Hodges-Lehmann estimator. We accordingly propose a framework of a two-step testing procedure. First, we estimate the bisecting hyperplanes for each pair of instances and an aggregated rule derived through the Hodges-Lehmann estimator. The paired samples are scored by this aggregated rule to produce a unidimensional representation. Second, we perform a Wilcoxon signed-rank test on the obtained representation. Our experiments indicate that our approach has substantial performance gains in testing accuracy compared to the traditional multivariate and multiple testing, while at the same time estimates each feature's contribution to the final result.
Online Centralized Non-parametric Change-point Detection via Graph-based Likelihood-ratio Estimation
Jan 12, 2023Consider each node of a graph to be generating a data stream that is synchronized and observed at near real-time. At a change-point $\tau$, a change occurs at a subset of nodes $C$, which affects the probability distribution of their associated node streams. In this paper, we propose a novel kernel-based method to both detect $\tau$ and localize $C$, based on the direct estimation of the likelihood-ratio between the post-change and the pre-change distributions of the node streams. Our main working hypothesis is the smoothness of the likelihood-ratio estimates over the graph, i.e connected nodes are expected to have similar likelihood-ratios. The quality of the proposed method is demonstrated on extensive experiments on synthetic scenarios.