 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlackwell's Approachability with Time-Dependent Outcome Functions and Dot Products. Application to the Big Match
Mar 09, 2023Blackwell's approachability is a very general sequential decision framework where a Decision Maker obtains vector-valued outcomes, and aims at the convergence of the average outcome to a given "target" set. Blackwell gave a sufficient condition for the decision maker having a strategy guaranteeing such a convergence against an adversarial environment, as well as what we now call the Blackwell's algorithm, which then ensures convergence. Blackwell's approachability has since been applied to numerous problems, in online learning and game theory, in particular. We extend this framework by allowing the outcome function and the dot product to be time-dependent. We establish a general guarantee for the natural extension to this framework of Blackwell's algorithm. In the case where the target set is an orthant, we present a family of time-dependent dot products which yields different convergence speeds for each coordinate of the average outcome. We apply this framework to the Big Match (one of the most important toy examples of stochastic games) where an $\epsilon$-uniformly optimal strategy for Player I is given by Blackwell's algorithm in a well-chosen auxiliary approachability problem.
Refined approachability algorithms and application to regret minimization with global costs
Sep 15, 2020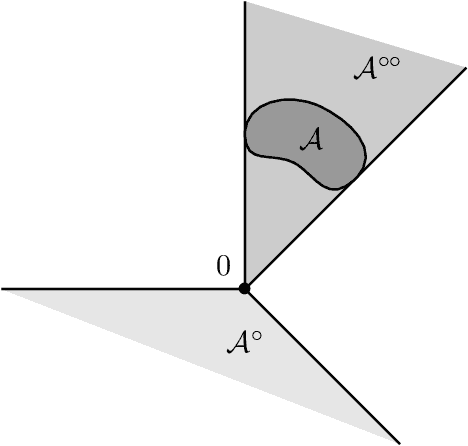
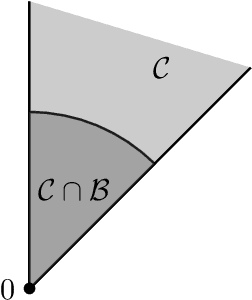
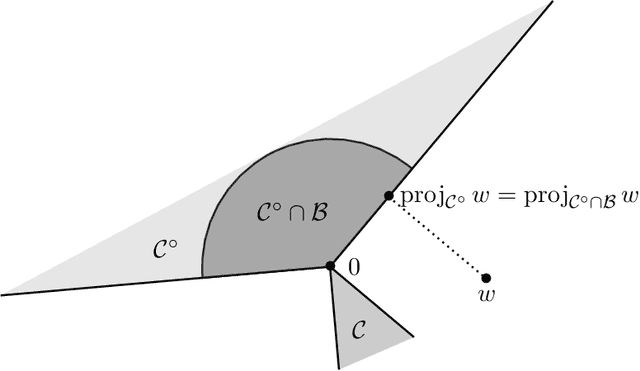
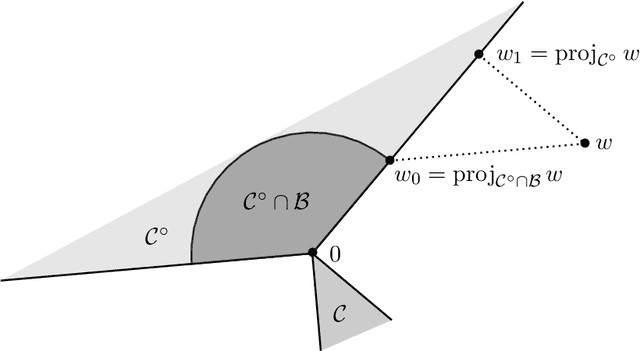
Blackwell's approachability is a framework where two players, the Decision Maker and the Environment, play a repeated game with vector-valued payoffs. The goal of the Decision Maker is to make the average payoff converge to a given set called the target. When this is indeed possible, simple algorithms which guarantee the convergence are known. This abstract tool was successfully used for the construction of optimal strategies in various repeated games, but also found several applications in online learning. By extending an approach proposed by Abernethy et al. (2011), we construct and analyze a class of Follow the Regularized Leader algorithms (FTRL) for Blackwell's approachability which are able to minimize not only the Euclidean distance to the target set (as it is often the case in the context of Blackwell's approachability) but a wide range of distance-like quantities. This flexibility enables us to apply these algorithms to minimize the exact quantity of interest in various online learning problems. In particular, for regret minimization with global costs, we obtain novel guarantees for general norm cost functions, and for the case of $\ell_p$ cost functions, we obtain the first regret bounds with explicit dependence in $p$ and the dimension $d$.
Unifying mirror descent and dual averaging
Oct 30, 2019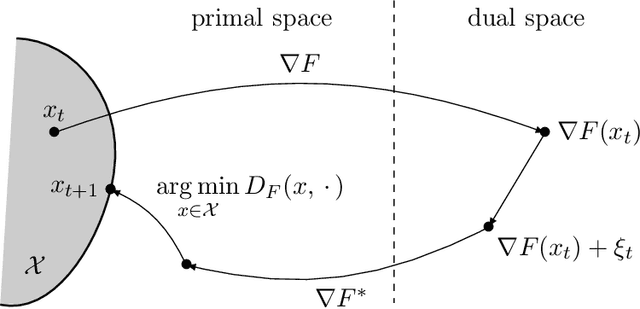
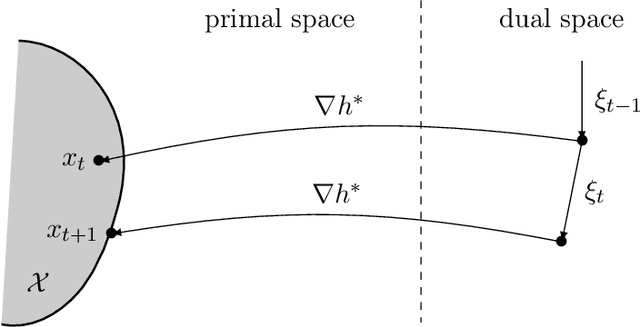
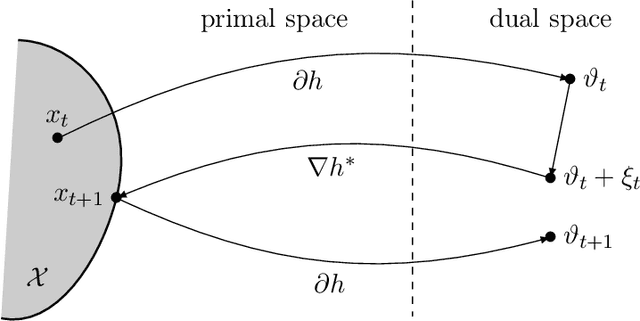
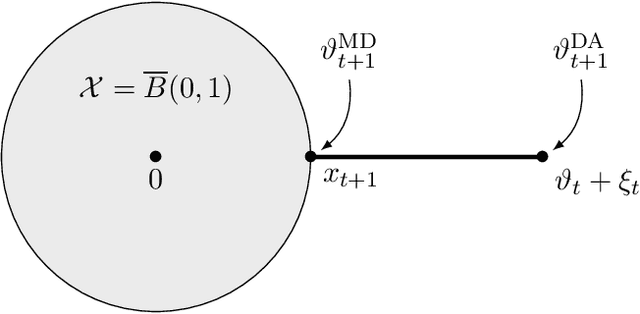
We introduce and analyse a new family of algorithms which generalizes and unifies both the mirror descent and the dual averaging algorithms. The unified analysis of the algorithms involves the introduction of a generalized Bregman divergence which utilizes subgradients instead of gradients. Our approach is general enough to encompass classical settings in convex optimization, online learning, and variational inequalities such as saddle-point problems.
Sparse Stochastic Bandits
Jun 05, 2017In the classical multi-armed bandit problem, d arms are available to the decision maker who pulls them sequentially in order to maximize his cumulative reward. Guarantees can be obtained on a relative quantity called regret, which scales linearly with d (or with sqrt(d) in the minimax sense). We here consider the sparse case of this classical problem in the sense that only a small number of arms, namely s < d, have a positive expected reward. We are able to leverage this additional assumption to provide an algorithm whose regret scales with s instead of d. Moreover, we prove that this algorithm is optimal by providing a matching lower bound - at least for a wide and pertinent range of parameters that we determine - and by evaluating its performance on simulated data.
Gains and Losses are Fundamentally Different in Regret Minimization: The Sparse Case
Nov 26, 2015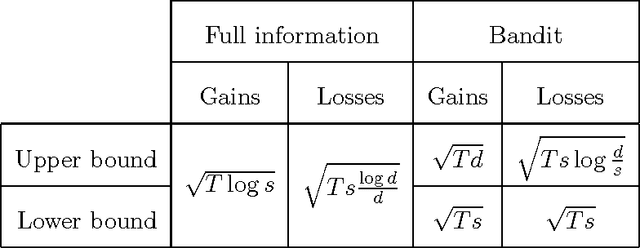
We demonstrate that, in the classical non-stochastic regret minimization problem with $d$ decisions, gains and losses to be respectively maximized or minimized are fundamentally different. Indeed, by considering the additional sparsity assumption (at each stage, at most $s$ decisions incur a nonzero outcome), we derive optimal regret bounds of different orders. Specifically, with gains, we obtain an optimal regret guarantee after $T$ stages of order $\sqrt{T\log s}$, so the classical dependency in the dimension is replaced by the sparsity size. With losses, we provide matching upper and lower bounds of order $\sqrt{Ts\log(d)/d}$, which is decreasing in $d$. Eventually, we also study the bandit setting, and obtain an upper bound of order $\sqrt{Ts\log (d/s)}$ when outcomes are losses. This bound is proven to be optimal up to the logarithmic factor $\sqrt{\log(d/s)}$.
A continuous-time approach to online optimization
Feb 27, 2014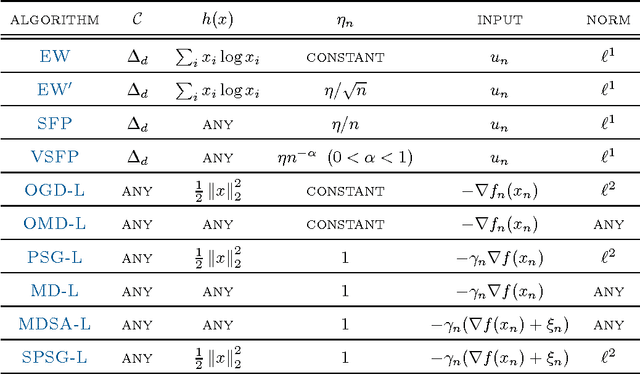
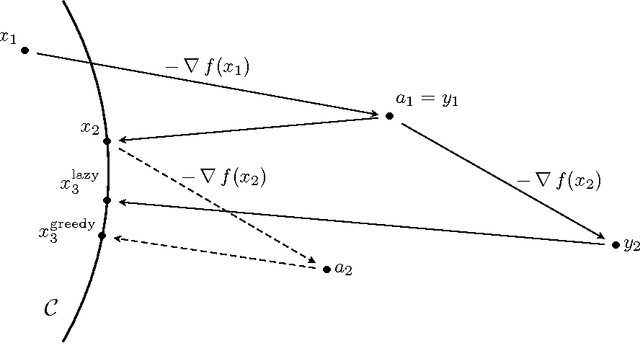
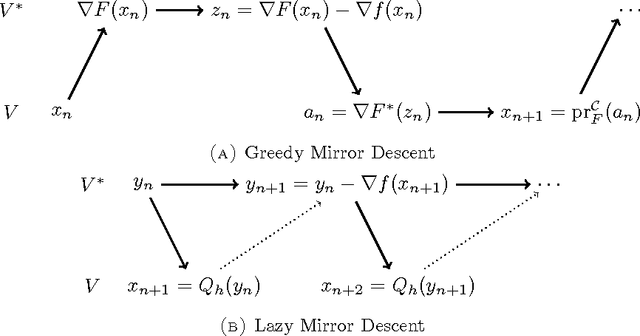
We consider a family of learning strategies for online optimization problems that evolve in continuous time and we show that they lead to no regret. From a more traditional, discrete-time viewpoint, this continuous-time approach allows us to derive the no-regret properties of a large class of discrete-time algorithms including as special cases the exponential weight algorithm, online mirror descent, smooth fictitious play and vanishingly smooth fictitious play. In so doing, we obtain a unified view of many classical regret bounds, and we show that they can be decomposed into a term stemming from continuous-time considerations and a term which measures the disparity between discrete and continuous time. As a result, we obtain a general class of infinite horizon learning strategies that guarantee an $\mathcal{O}(n^{-1/2})$ regret bound without having to resort to a doubling trick.