 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGains and Losses are Fundamentally Different in Regret Minimization: The Sparse Case
Paper and Code
Nov 26, 2015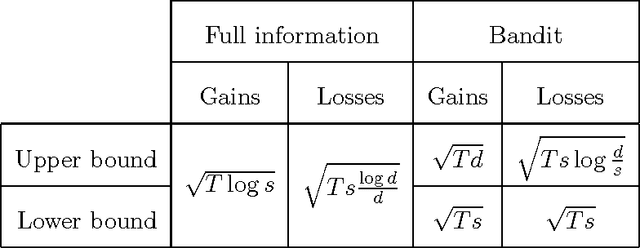
We demonstrate that, in the classical non-stochastic regret minimization problem with $d$ decisions, gains and losses to be respectively maximized or minimized are fundamentally different. Indeed, by considering the additional sparsity assumption (at each stage, at most $s$ decisions incur a nonzero outcome), we derive optimal regret bounds of different orders. Specifically, with gains, we obtain an optimal regret guarantee after $T$ stages of order $\sqrt{T\log s}$, so the classical dependency in the dimension is replaced by the sparsity size. With losses, we provide matching upper and lower bounds of order $\sqrt{Ts\log(d)/d}$, which is decreasing in $d$. Eventually, we also study the bandit setting, and obtain an upper bound of order $\sqrt{Ts\log (d/s)}$ when outcomes are losses. This bound is proven to be optimal up to the logarithmic factor $\sqrt{\log(d/s)}$.