 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniform-in-time concentration in two-layer neural networks via transportation inequalities
Mar 02, 2026We quantify, uniformly over time and with high probability, the discrepancy between the predictions of a two-layer neural network trained by stochastic gradient descent (SGD) and their mean-field limit, for quadratic loss and ridge regularization. As a key ingredient, we establish T p transportation inequalities (p $\in$ {1, 2}) for the law of the SGD parameters, with explicit constants independent of the iteration index. We then prove uniform-in-time concentration of the empirical parameter measure around its mean-field limit in the Wasserstein distance W 1 , and we translate these bounds into prediction-error estimates against a fixed test function $Φ$. We also derive analogous concentration bounds in the sliced-Wasserstein distance SW 1 , leading to dimension-free rates.
Diffusion annealed Langevin dynamics: a theoretical study
Nov 13, 2025In this work we study the diffusion annealed Langevin dynamics, a score-based diffusion process recently introduced in the theory of generative models and which is an alternative to the classical overdamped Langevin diffusion. Our goal is to provide a rigorous construction and to study the theoretical efficiency of these models for general base distribution as well as target distribution. As a matter of fact these diffusion processes are a particular case of Nelson processes i.e. diffusion processes with a given flow of time marginals. Providing existence and uniqueness of the solution to the annealed Langevin diffusion leads to proving a Poincaré inequality for the conditional distribution of $X$ knowing $X+Z=y$ uniformly in $y$, as recently observed by one of us and her coauthors. Part of this work is thus devoted to the study of such Poincaré inequalities. Additionally we show that strengthening the Poincaré inequality into a logarithmic Sobolev inequality improves the efficiency of the model.
Error estimates between SGD with momentum and underdamped Langevin diffusion
Oct 22, 2024Stochastic gradient descent with momentum is a popular variant of stochastic gradient descent, which has recently been reported to have a close relationship with the underdamped Langevin diffusion. In this paper, we establish a quantitative error estimate between them in the 1-Wasserstein and total variation distances.
Central Limit Theorem for Bayesian Neural Network trained with Variational Inference
Jun 10, 2024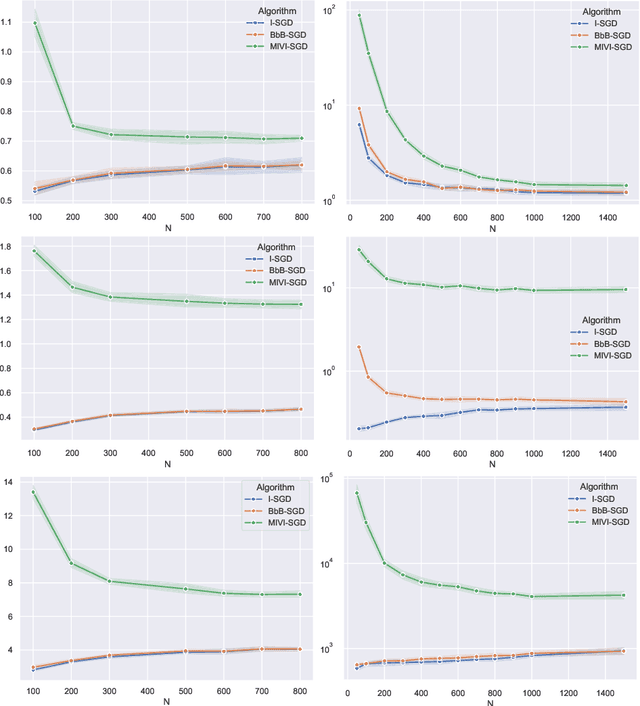
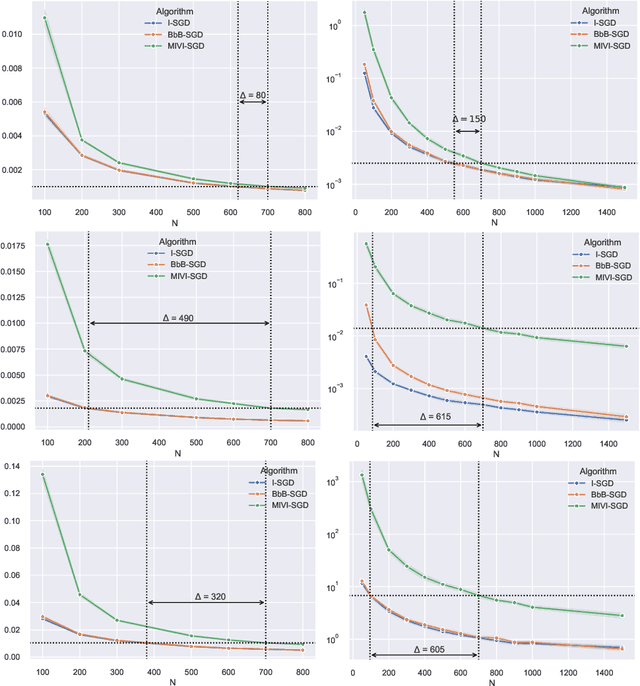
In this paper, we rigorously derive Central Limit Theorems (CLT) for Bayesian two-layerneural networks in the infinite-width limit and trained by variational inference on a regression task. The different networks are trained via different maximization schemes of the regularized evidence lower bound: (i) the idealized case with exact estimation of a multiple Gaussian integral from the reparametrization trick, (ii) a minibatch scheme using Monte Carlo sampling, commonly known as Bayes-by-Backprop, and (iii) a computationally cheaper algorithm named Minimal VI. The latter was recently introduced by leveraging the information obtained at the level of the mean-field limit. Laws of large numbers are already rigorously proven for the three schemes that admits the same asymptotic limit. By deriving CLT, this work shows that the idealized and Bayes-by-Backprop schemes have similar fluctuation behavior, that is different from the Minimal VI one. Numerical experiments then illustrate that the Minimal VI scheme is still more efficient, in spite of bigger variances, thanks to its important gain in computational complexity.
Law of Large Numbers for Bayesian two-layer Neural Network trained with Variational Inference
Jul 10, 2023



We provide a rigorous analysis of training by variational inference (VI) of Bayesian neural networks in the two-layer and infinite-width case. We consider a regression problem with a regularized evidence lower bound (ELBO) which is decomposed into the expected log-likelihood of the data and the Kullback-Leibler (KL) divergence between the a priori distribution and the variational posterior. With an appropriate weighting of the KL, we prove a law of large numbers for three different training schemes: (i) the idealized case with exact estimation of a multiple Gaussian integral from the reparametrization trick, (ii) a minibatch scheme using Monte Carlo sampling, commonly known as Bayes by Backprop, and (iii) a new and computationally cheaper algorithm which we introduce as Minimal VI. An important result is that all methods converge to the same mean-field limit. Finally, we illustrate our results numerically and discuss the need for the derivation of a central limit theorem.
Fixed-kinetic Neural Hamiltonian Flows for enhanced interpretability and reduced complexity
Feb 03, 2023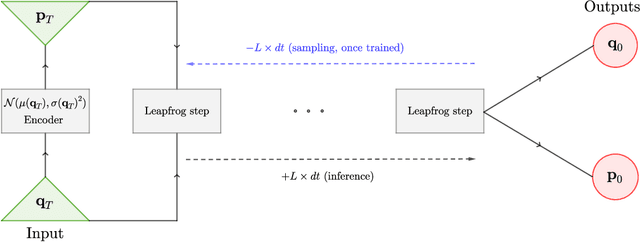
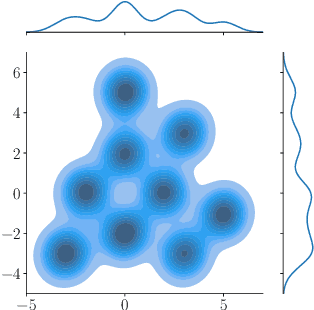
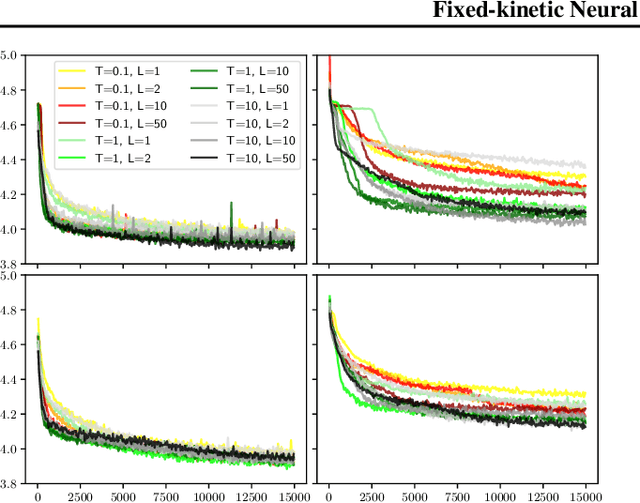
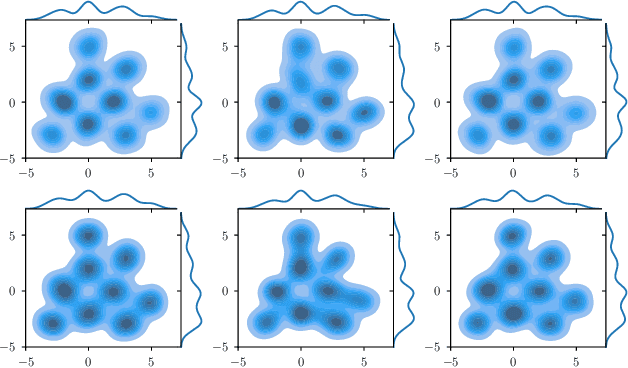
Normalizing Flows (NF) are Generative models which are particularly robust and allow for exact sampling of the learned distribution. They however require the design of an invertible mapping, whose Jacobian determinant has to be computable. Recently introduced, Neural Hamiltonian Flows (NHF) are based on Hamiltonian dynamics-based Flows, which are continuous, volume-preserving and invertible and thus make for natural candidates for robust NF architectures. In particular, their similarity to classical Mechanics could lead to easier interpretability of the learned mapping. However, despite being Physics-inspired architectures, the originally introduced NHF architecture still poses a challenge to interpretability. For this reason, in this work, we introduce a fixed kinetic energy version of the NHF model. Inspired by physics, our approach improves interpretability and requires less parameters than previously proposed architectures. We then study the robustness of the NHF architectures to the choice of hyperparameters. We analyze the impact of the number of leapfrog steps, the integration time and the number of neurons per hidden layer, as well as the choice of prior distribution, on sampling a multimodal 2D mixture. The NHF architecture is robust to these choices, especially the fixed-kinetic energy model. Finally, we adapt NHF to the context of Bayesian inference and illustrate our method on sampling the posterior distribution of two cosmological parameters knowing type Ia supernovae observations.