 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Universe: Learning to Optimize Cosmic Initial Conditions with Non-Differentiable Structure Formation Models
Feb 18, 2025Making the most of next-generation galaxy clustering surveys requires overcoming challenges in complex, non-linear modelling to access the significant amount of information at smaller cosmological scales. Field-level inference has provided a unique opportunity beyond summary statistics to use all of the information of the galaxy distribution. However, addressing current challenges often necessitates numerical modelling that incorporates non-differentiable components, hindering the use of efficient gradient-based inference methods. In this paper, we introduce Learning the Universe by Learning to Optimize (LULO), a gradient-free framework for reconstructing the 3D cosmic initial conditions. Our approach advances deep learning to train an optimization algorithm capable of fitting state-of-the-art non-differentiable simulators to data at the field level. Importantly, the neural optimizer solely acts as a search engine in an iterative scheme, always maintaining full physics simulations in the loop, ensuring scalability and reliability. We demonstrate the method by accurately reconstructing initial conditions from $M_{200\mathrm{c}}$ halos identified in a dark matter-only $N$-body simulation with a spherical overdensity algorithm. The derived dark matter and halo overdensity fields exhibit $\geq80\%$ cross-correlation with the ground truth into the non-linear regime $k \sim 1h$ Mpc$^{-1}$. Additional cosmological tests reveal accurate recovery of the power spectra, bispectra, halo mass function, and velocities. With this work, we demonstrate a promising path forward to non-linear field-level inference surpassing the requirement of a differentiable physics model.
Fixed-kinetic Neural Hamiltonian Flows for enhanced interpretability and reduced complexity
Feb 03, 2023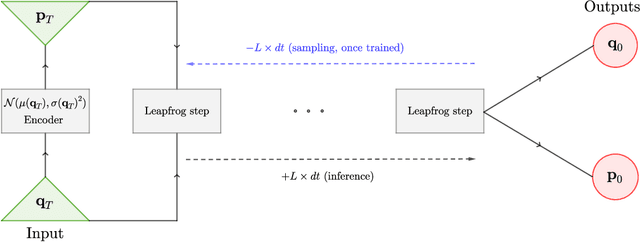
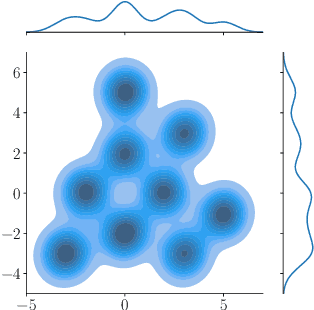
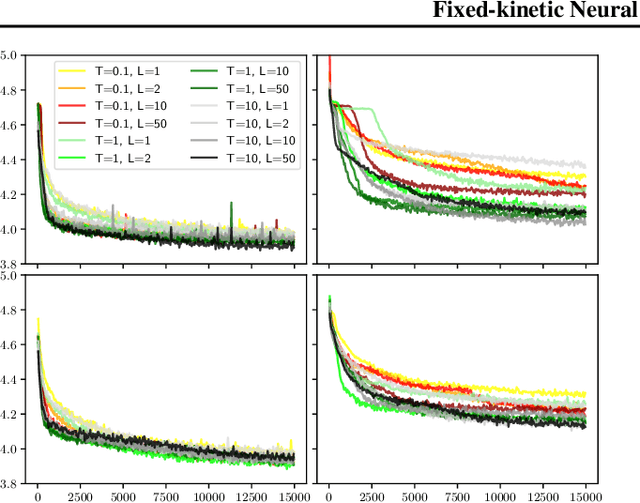
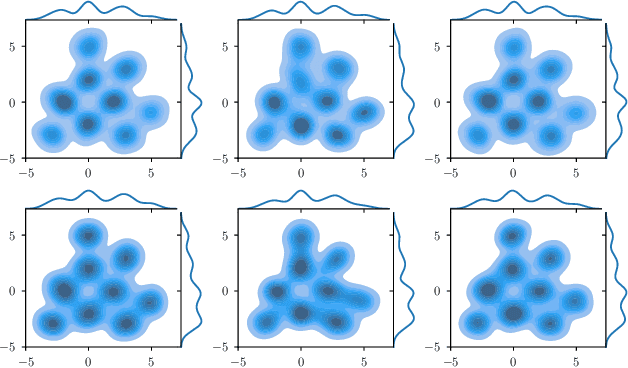
Normalizing Flows (NF) are Generative models which are particularly robust and allow for exact sampling of the learned distribution. They however require the design of an invertible mapping, whose Jacobian determinant has to be computable. Recently introduced, Neural Hamiltonian Flows (NHF) are based on Hamiltonian dynamics-based Flows, which are continuous, volume-preserving and invertible and thus make for natural candidates for robust NF architectures. In particular, their similarity to classical Mechanics could lead to easier interpretability of the learned mapping. However, despite being Physics-inspired architectures, the originally introduced NHF architecture still poses a challenge to interpretability. For this reason, in this work, we introduce a fixed kinetic energy version of the NHF model. Inspired by physics, our approach improves interpretability and requires less parameters than previously proposed architectures. We then study the robustness of the NHF architectures to the choice of hyperparameters. We analyze the impact of the number of leapfrog steps, the integration time and the number of neurons per hidden layer, as well as the choice of prior distribution, on sampling a multimodal 2D mixture. The NHF architecture is robust to these choices, especially the fixed-kinetic energy model. Finally, we adapt NHF to the context of Bayesian inference and illustrate our method on sampling the posterior distribution of two cosmological parameters knowing type Ia supernovae observations.