 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Projection onto Historical Descent Directions for Communication-Efficient Federated Learning
Nov 05, 2025Federated Learning (FL) enables decentralized model training across multiple clients while optionally preserving data privacy. However, communication efficiency remains a critical bottleneck, particularly for large-scale models. In this work, we introduce two complementary algorithms: ProjFL, designed for unbiased compressors, and ProjFL+EF, tailored for biased compressors through an Error Feedback mechanism. Both methods rely on projecting local gradients onto a shared client-server subspace spanned by historical descent directions, enabling efficient information exchange with minimal communication overhead. We establish convergence guarantees for both algorithms under strongly convex, convex, and non-convex settings. Empirical evaluations on standard FL classification benchmarks with deep neural networks show that ProjFL and ProjFL+EF achieve accuracy comparable to existing baselines while substantially reducing communication costs.
Central Limit Theorem for Bayesian Neural Network trained with Variational Inference
Jun 10, 2024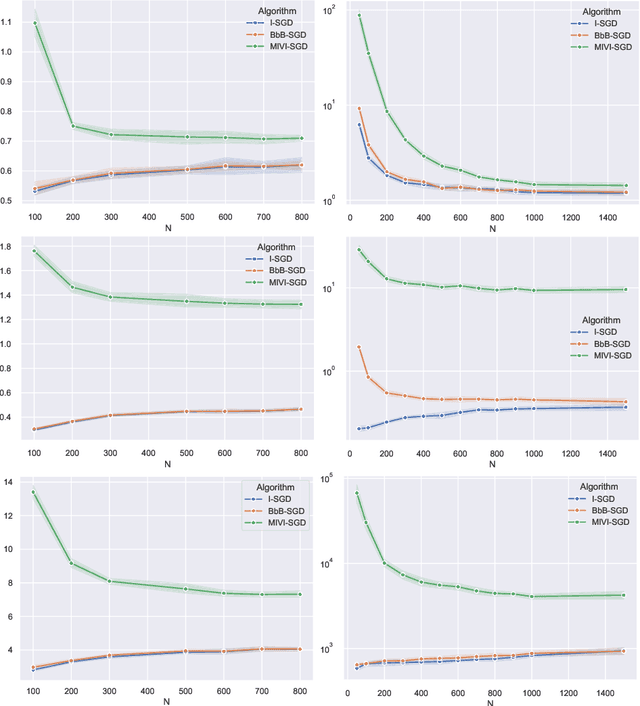
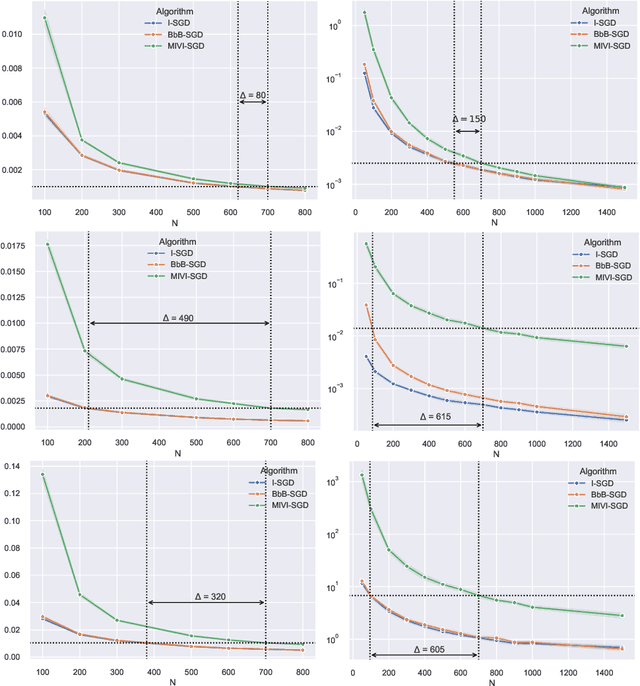
In this paper, we rigorously derive Central Limit Theorems (CLT) for Bayesian two-layerneural networks in the infinite-width limit and trained by variational inference on a regression task. The different networks are trained via different maximization schemes of the regularized evidence lower bound: (i) the idealized case with exact estimation of a multiple Gaussian integral from the reparametrization trick, (ii) a minibatch scheme using Monte Carlo sampling, commonly known as Bayes-by-Backprop, and (iii) a computationally cheaper algorithm named Minimal VI. The latter was recently introduced by leveraging the information obtained at the level of the mean-field limit. Laws of large numbers are already rigorously proven for the three schemes that admits the same asymptotic limit. By deriving CLT, this work shows that the idealized and Bayes-by-Backprop schemes have similar fluctuation behavior, that is different from the Minimal VI one. Numerical experiments then illustrate that the Minimal VI scheme is still more efficient, in spite of bigger variances, thanks to its important gain in computational complexity.
Law of Large Numbers for Bayesian two-layer Neural Network trained with Variational Inference
Jul 10, 2023We provide a rigorous analysis of training by variational inference (VI) of Bayesian neural networks in the two-layer and infinite-width case. We consider a regression problem with a regularized evidence lower bound (ELBO) which is decomposed into the expected log-likelihood of the data and the Kullback-Leibler (KL) divergence between the a priori distribution and the variational posterior. With an appropriate weighting of the KL, we prove a law of large numbers for three different training schemes: (i) the idealized case with exact estimation of a multiple Gaussian integral from the reparametrization trick, (ii) a minibatch scheme using Monte Carlo sampling, commonly known as Bayes by Backprop, and (iii) a new and computationally cheaper algorithm which we introduce as Minimal VI. An important result is that all methods converge to the same mean-field limit. Finally, we illustrate our results numerically and discuss the need for the derivation of a central limit theorem.