 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Audio Prototyping: a prototype system for unified sound retrieval and procedural generation
May 30, 2026Sound design workflows frequently oscillate between time-consuming library searches and the complexity of procedural synthesis, with practitioners typically relying on disconnected tools to address each challenge separately. This paper introduces Quality Audio Prototyping (QuAP), a working prototype that unifies content-based audio retrieval and procedural sound generation within a single interface, reducing the procedural distance between a narrative concept and its sonic realisation. QuAP integrates a similarity-based retrieval engine with real-time procedural audio models, complemented by a rule-based assistant that provides perceptually informed parameter guidance, offering definitions and recommendations derived from empirical optimisation rather than requiring prior synthesis knowledge. Preliminary evaluation confirms the viability of this approach: subjective assessment demonstrated statistically significant quality improvements in five of six embedded synthesis models, and an encoder ablation study established the preferred retrieval architecture on a sound effect dataset. A user evaluation with 16 practitioners confirmed the tool's workflow utility, with all participants agreeing that the parameter assistant preserved creative agency while lowering the barrier to procedural interaction.
An investigation of AI integration in sound designer workflows and experiences
May 26, 2026Artificial intelligence is increasingly being integrated into professional audio production workflows, yet a gap persists between the tools developers produce and the requirements of practising sound designers. This paper investigates this gap through a mixed-methods study comprising a survey of 76 practitioners and follow-up semi-structured interviews with 20 industry professionals. Results were analysed using descriptive statistical analysis and thematic analysis to identify patterns across both datasets. Five themes emerged from our analysis: Context, Workflow, Potential, Risks, and Right Use. Our work indicates that current AI tools perform adequately in fast-consumption media contexts but lack the narrative sophistication required for high-end sound design (films, immersive experiences etc). Practitioners demonstrate a preference for assistive, task-specific applications, particularly in audio restoration and library management, over end-to-end generative systems. This work contributes to the on-going discussion on the use of AI and AI-enhanced tools in the creative industries. We report on the current status of the field from the point of view of sound designers and creative audio practitioners, and offer a set of recommendation for sound technologist and developers based on our findings to guide the development of more informed AI tools for sound design.
Learning Control of Neural Sound Effects Synthesis from Physically Inspired Models
Mar 11, 2025



Sound effects model design commonly uses digital signal processing techniques with full control ability, but it is difficult to achieve realism within a limited number of parameters. Recently, neural sound effects synthesis methods have emerged as a promising approach for generating high-quality and realistic sounds, but the process of synthesizing the desired sound poses difficulties in terms of control. This paper presents a real-time neural synthesis model guided by a physically inspired model, enabling the generation of high-quality sounds while inheriting the control interface of the physically inspired model. We showcase the superior performance of our model in terms of sound quality and control.
Heterogeneous bimodal attention fusion for speech emotion recognition
Mar 09, 2025Multi-modal emotion recognition in conversations is a challenging problem due to the complex and complementary interactions between different modalities. Audio and textual cues are particularly important for understanding emotions from a human perspective. Most existing studies focus on exploring interactions between audio and text modalities at the same representation level. However, a critical issue is often overlooked: the heterogeneous modality gap between low-level audio representations and high-level text representations. To address this problem, we propose a novel framework called Heterogeneous Bimodal Attention Fusion (HBAF) for multi-level multi-modal interaction in conversational emotion recognition. The proposed method comprises three key modules: the uni-modal representation module, the multi-modal fusion module, and the inter-modal contrastive learning module. The uni-modal representation module incorporates contextual content into low-level audio representations to bridge the heterogeneous multi-modal gap, enabling more effective fusion. The multi-modal fusion module uses dynamic bimodal attention and a dynamic gating mechanism to filter incorrect cross-modal relationships and fully exploit both intra-modal and inter-modal interactions. Finally, the inter-modal contrastive learning module captures complex absolute and relative interactions between audio and text modalities. Experiments on the MELD and IEMOCAP datasets demonstrate that the proposed HBAF method outperforms existing state-of-the-art baselines.
Visual-based spatial audio generation system for multi-speaker environments
Feb 13, 2025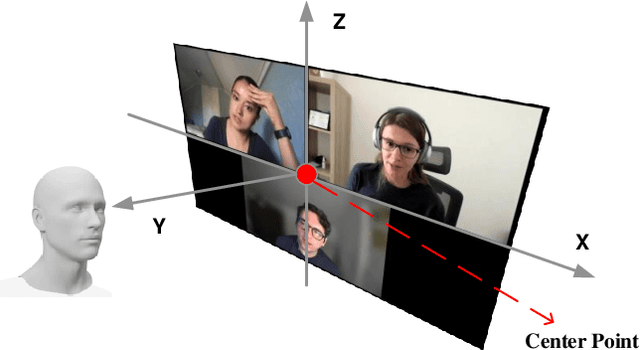



In multimedia applications such as films and video games, spatial audio techniques are widely employed to enhance user experiences by simulating 3D sound: transforming mono audio into binaural formats. However, this process is often complex and labor-intensive for sound designers, requiring precise synchronization of audio with the spatial positions of visual components. To address these challenges, we propose a visual-based spatial audio generation system - an automated system that integrates face detection YOLOv8 for object detection, monocular depth estimation, and spatial audio techniques. Notably, the system operates without requiring additional binaural dataset training. The proposed system is evaluated against existing Spatial Audio generation system using objective metrics. Experimental results demonstrate that our method significantly improves spatial consistency between audio and video, enhances speech quality, and performs robustly in multi-speaker scenarios. By streamlining the audio-visual alignment process, the proposed system enables sound engineers to achieve high-quality results efficiently, making it a valuable tool for professionals in multimedia production.
6KSFx Synth Dataset
Jan 27, 2025Procedural audio, often referred to as "digital Foley", generates sound from scratch using computational processes. It represents an innovative approach to sound-effects creation. However, the development and adoption of procedural audio has been constrained by a lack of publicly available datasets and models, which hinders evaluation and optimization. To address this important gap, this paper presents a dataset of 6000 synthetic audio samples specifically designed to advance research and development in sound synthesis within 30 sound categories. By offering a description of the diverse synthesis methods used in each sound category and supporting the creation of robust evaluation frameworks, this dataset not only highlights the potential of procedural audio, but also provides a resource for researchers, audio developers, and sound designers. This contribution can accelerate the progress of procedural audio, opening up new possibilities in digital sound design.
* 7 pages, 2 tables and 1 figure
Diff-MST: Differentiable Mixing Style Transfer
Jul 11, 2024Mixing style transfer automates the generation of a multitrack mix for a given set of tracks by inferring production attributes from a reference song. However, existing systems for mixing style transfer are limited in that they often operate only on a fixed number of tracks, introduce artifacts, and produce mixes in an end-to-end fashion, without grounding in traditional audio effects, prohibiting interpretability and controllability. To overcome these challenges, we introduce Diff-MST, a framework comprising a differentiable mixing console, a transformer controller, and an audio production style loss function. By inputting raw tracks and a reference song, our model estimates control parameters for audio effects within a differentiable mixing console, producing high-quality mixes and enabling post-hoc adjustments. Moreover, our architecture supports an arbitrary number of input tracks without source labelling, enabling real-world applications. We evaluate our model's performance against robust baselines and showcase the effectiveness of our approach, architectural design, tailored audio production style loss, and innovative training methodology for the given task.
1st Place Solution to Odyssey Emotion Recognition Challenge Task1: Tackling Class Imbalance Problem
May 30, 2024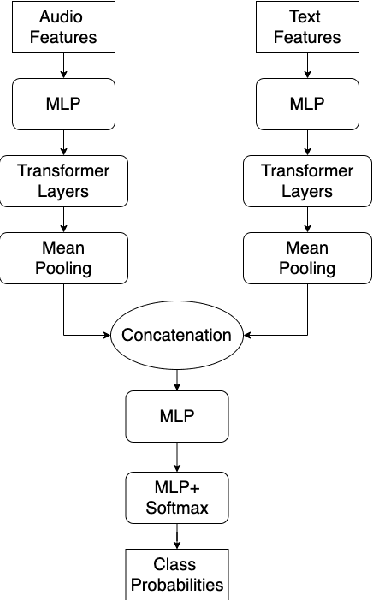



Speech emotion recognition is a challenging classification task with natural emotional speech, especially when the distribution of emotion types is imbalanced in the training and test data. In this case, it is more difficult for a model to learn to separate minority classes, resulting in those sometimes being ignored or frequently misclassified. Previous work has utilised class weighted loss for training, but problems remain as it sometimes causes over-fitting for minor classes or under-fitting for major classes. This paper presents the system developed by a multi-site team for the participation in the Odyssey 2024 Emotion Recognition Challenge Track-1. The challenge data has the aforementioned properties and therefore the presented systems aimed to tackle these issues, by introducing focal loss in optimisation when applying class weighted loss. Specifically, the focal loss is further weighted by prior-based class weights. Experimental results show that combining these two approaches brings better overall performance, by sacrificing performance on major classes. The system further employs a majority voting strategy to combine the outputs of an ensemble of 7 models. The models are trained independently, using different acoustic features and loss functions - with the aim to have different properties for different data. Hence these models show different performance preferences on major classes and minor classes. The ensemble system output obtained the best performance in the challenge, ranking top-1 among 68 submissions. It also outperformed all single models in our set. On the Odyssey 2024 Emotion Recognition Challenge Task-1 data the system obtained a Macro-F1 score of 35.69% and an accuracy of 37.32%.
deep learning of segment-level feature representation for speech emotion recognition in conversations
Feb 05, 2023

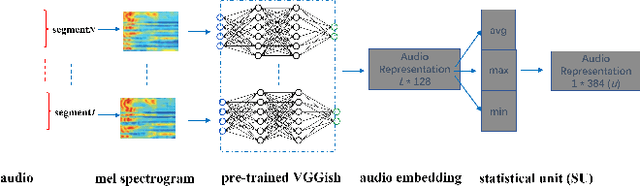

Accurately detecting emotions in conversation is a necessary yet challenging task due to the complexity of emotions and dynamics in dialogues. The emotional state of a speaker can be influenced by many different factors, such as interlocutor stimulus, dialogue scene, and topic. In this work, we propose a conversational speech emotion recognition method to deal with capturing attentive contextual dependency and speaker-sensitive interactions. First, we use a pretrained VGGish model to extract segment-based audio representation in individual utterances. Second, an attentive bi-directional gated recurrent unit (GRU) models contextual-sensitive information and explores intra- and inter-speaker dependencies jointly in a dynamic manner. The experiments conducted on the standard conversational dataset MELD demonstrate the effectiveness of the proposed method when compared against state-of the-art methods.
cross-modal fusion techniques for utterance-level emotion recognition from text and speech
Feb 05, 2023



Multimodal emotion recognition (MER) is a fundamental complex research problem due to the uncertainty of human emotional expression and the heterogeneity gap between different modalities. Audio and text modalities are particularly important for a human participant in understanding emotions. Although many successful attempts have been designed multimodal representations for MER, there still exist multiple challenges to be addressed: 1) bridging the heterogeneity gap between multimodal features and model inter- and intra-modal interactions of multiple modalities; 2) effectively and efficiently modelling the contextual dynamics in the conversation sequence. In this paper, we propose Cross-Modal RoBERTa (CM-RoBERTa) model for emotion detection from spoken audio and corresponding transcripts. As the core unit of the CM-RoBERTa, parallel self- and cross- attention is designed to dynamically capture inter- and intra-modal interactions of audio and text. Specially, the mid-level fusion and residual module are employed to model long-term contextual dependencies and learn modality-specific patterns. We evaluate the approach on the MELD dataset and the experimental results show the proposed approach achieves the state-of-art performance on the dataset.