 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Noise Reduction with Differentiable Signal Processing
Oct 17, 2023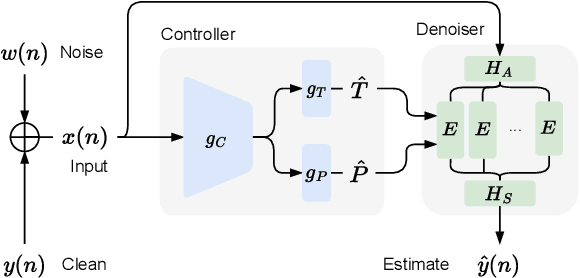

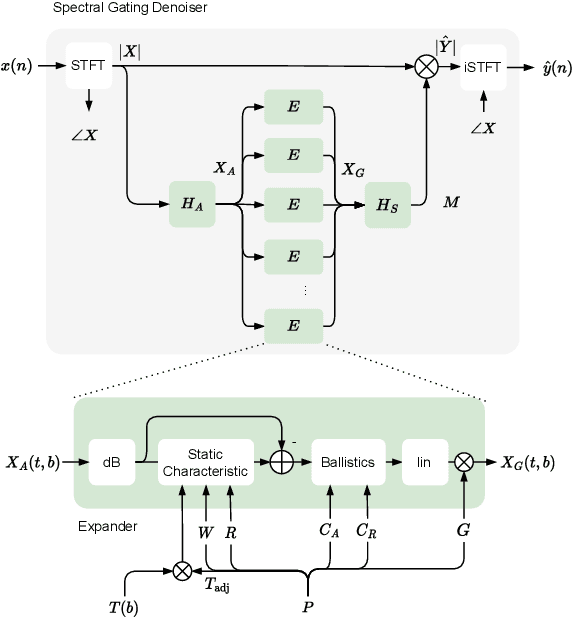

Noise reduction techniques based on deep learning have demonstrated impressive performance in enhancing the overall quality of recorded speech. While these approaches are highly performant, their application in audio engineering can be limited due to a number of factors. These include operation only on speech without support for music, lack of real-time capability, lack of interpretable control parameters, operation at lower sample rates, and a tendency to introduce artifacts. On the other hand, signal processing-based noise reduction algorithms offer fine-grained control and operation on a broad range of content, however, they often require manual operation to achieve the best results. To address the limitations of both approaches, in this work we introduce a method that leverages a signal processing-based denoiser that when combined with a neural network controller, enables fully automatic and high-fidelity noise reduction on both speech and music signals. We evaluate our proposed method with objective metrics and a perceptual listening test. Our evaluation reveals that speech enhancement models can be extended to music, however training the model to remove only stationary noise is critical. Furthermore, our proposed approach achieves performance on par with the deep learning models, while being significantly more efficient and introducing fewer artifacts in some cases. Listening examples are available online at https://tape.it/research/denoiser .
Unsupervised Construction of Human Body Models Using Principles of Organic Computing
Apr 12, 2017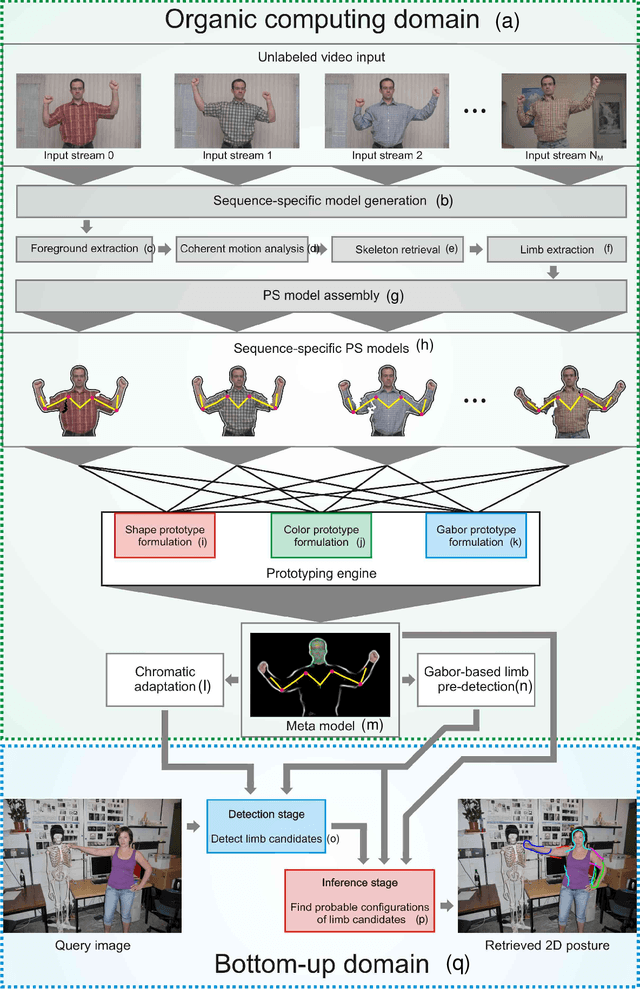

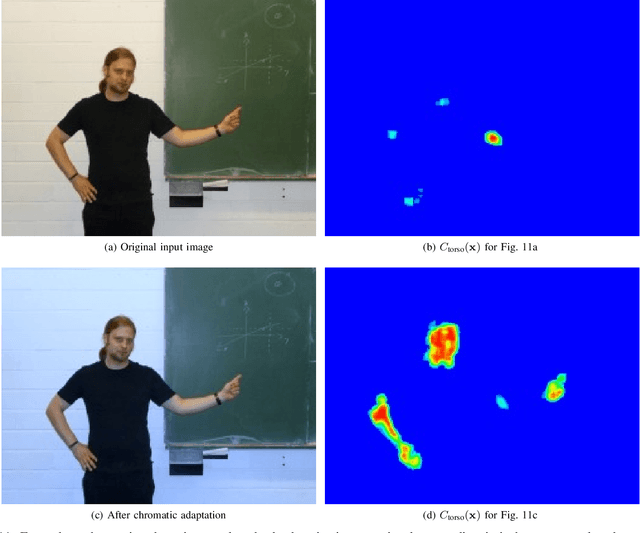

Unsupervised learning of a generalizable model of the visual appearance of humans from video data is of major importance for computing systems interacting naturally with their users and others. We propose a step towards automatic behavior understanding by integrating principles of Organic Computing into the posture estimation cycle, thereby relegating the need for human intervention while simultaneously raising the level of system autonomy. The system extracts coherent motion from moving upper bodies and autonomously decides about limbs and their possible spatial relationships. The models from many videos are integrated into meta-models, which show good generalization to different individuals, backgrounds, and attire. These models allow robust interpretation of single video frames without temporal continuity and posture mimicking by an android robot.