 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoLA: Motion Generation and Editing with Latent Diffusion Enhanced by Adversarial Training
Paper and Code
Jun 04, 2024
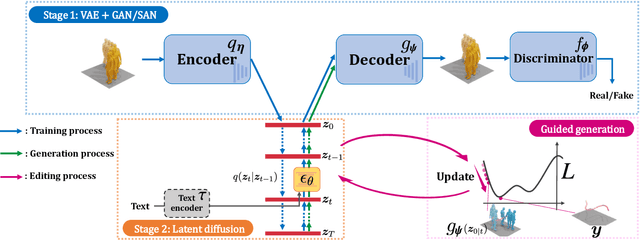
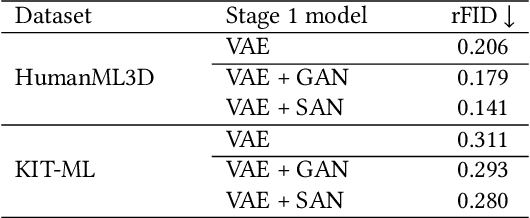
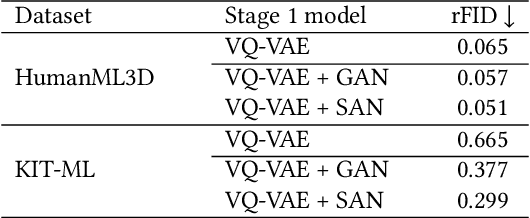
In motion generation, controllability as well as generation quality and speed is becoming more and more important. There are various motion editing tasks, such as in-betweening, upper body editing, and path-following, but existing methods perform motion editing with a data-space diffusion model, which is slow in inference compared to a latent diffusion model. In this paper, we propose MoLA, which provides fast and high-quality motion generation and also can deal with multiple editing tasks in a single framework. For high-quality and fast generation, we employ a variational autoencoder and latent diffusion model, and improve the performance with adversarial training. In addition, we apply a training-free guided generation framework to achieve various editing tasks with motion control inputs. We quantitatively show the effectiveness of adversarial learning in text-to-motion generation, and demonstrate the applicability of our editing framework to multiple editing tasks in the motion domain.