 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIAST: A Multimodal Piano Dataset with Audio, Symbolic and Text
Nov 04, 2024



While piano music has become a significant area of study in Music Information Retrieval (MIR), there is a notable lack of datasets for piano solo music with text labels. To address this gap, we present PIAST (PIano dataset with Audio, Symbolic, and Text), a piano music dataset. Utilizing a piano-specific taxonomy of semantic tags, we collected 9,673 tracks from YouTube and added human annotations for 2,023 tracks by music experts, resulting in two subsets: PIAST-YT and PIAST-AT. Both include audio, text, tag annotations, and transcribed MIDI utilizing state-of-the-art piano transcription and beat tracking models. Among many possible tasks with the multi-modal dataset, we conduct music tagging and retrieval using both audio and MIDI data and report baseline performances to demonstrate its potential as a valuable resource for MIR research.
Adversarial Multi-Task Learning for Disentangling Timbre and Pitch in Singing Voice Synthesis
Jun 23, 2022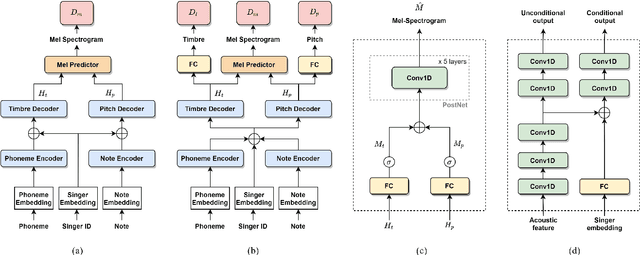
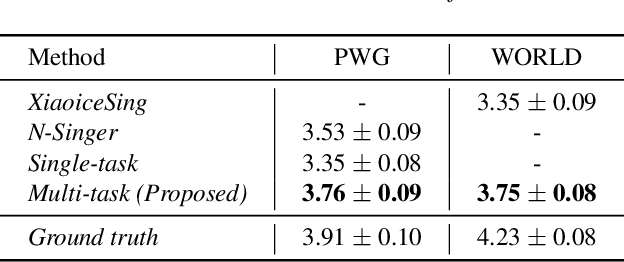
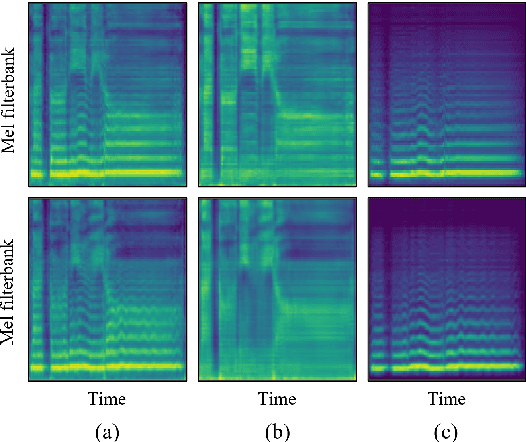
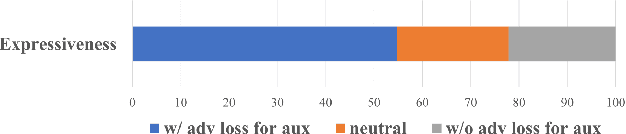
Recently, deep learning-based generative models have been introduced to generate singing voices. One approach is to predict the parametric vocoder features consisting of explicit speech parameters. This approach has the advantage that the meaning of each feature is explicitly distinguished. Another approach is to predict mel-spectrograms for a neural vocoder. However, parametric vocoders have limitations of voice quality and the mel-spectrogram features are difficult to model because the timbre and pitch information are entangled. In this study, we propose a singing voice synthesis model with multi-task learning to use both approaches -- acoustic features for a parametric vocoder and mel-spectrograms for a neural vocoder. By using the parametric vocoder features as auxiliary features, the proposed model can efficiently disentangle and control the timbre and pitch components of the mel-spectrogram. Moreover, a generative adversarial network framework is applied to improve the quality of singing voices in a multi-singer model. Experimental results demonstrate that our proposed model can generate more natural singing voices than the single-task models, while performing better than the conventional parametric vocoder-based model.
N-Singer: A Non-Autoregressive Korean Singing Voice Synthesis System for Pronunciation Enhancement
Jun 29, 2021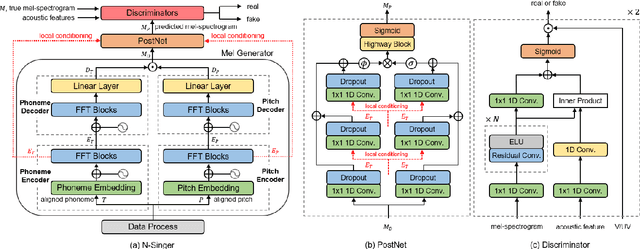
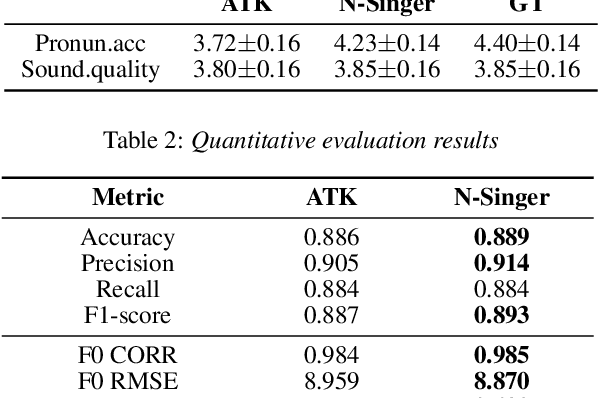
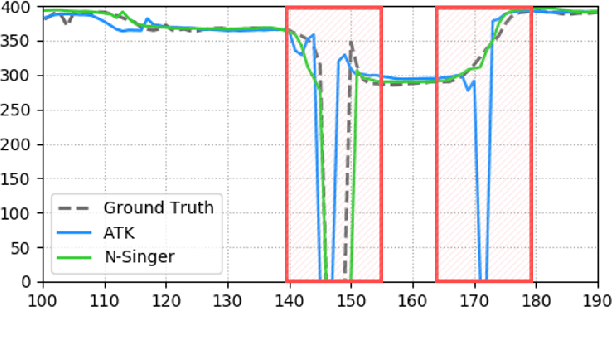
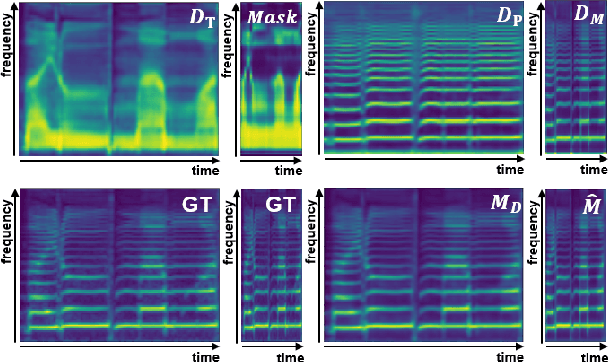
Recently, end-to-end Korean singing voice systems have been designed to generate realistic singing voices. However, these systems still suffer from a lack of robustness in terms of pronunciation accuracy. In this paper, we propose N-Singer, a non-autoregressive Korean singing voice system, to synthesize accurate and pronounced Korean singing voices in parallel. N-Singer consists of a Transformer-based mel-generator, a convolutional network-based postnet, and voicing-aware discriminators. It can contribute in the following ways. First, for accurate pronunciation, N-Singer separately models linguistic and pitch information without other acoustic features. Second, to achieve improved mel-spectrograms, N-Singer uses a combination of Transformer-based modules and convolutional network-based modules. Third, in adversarial training, voicing-aware conditional discriminators are used to capture the harmonic features of voiced segments and noise components of unvoiced segments. The experimental results prove that N-Singer can synthesize a natural singing voice in parallel with a more accurate pronunciation than the baseline model.