 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN-Singer: A Non-Autoregressive Korean Singing Voice Synthesis System for Pronunciation Enhancement
Paper and Code
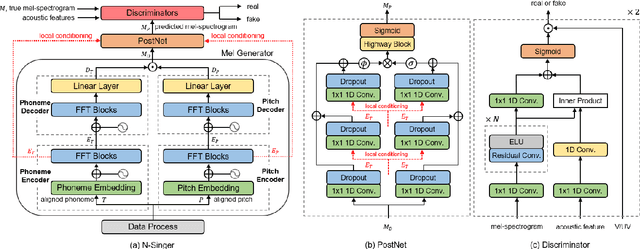
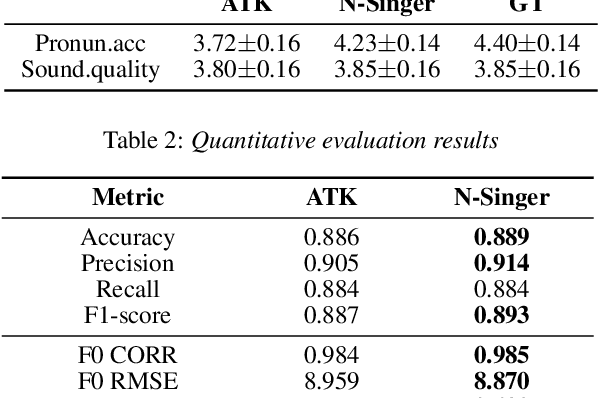
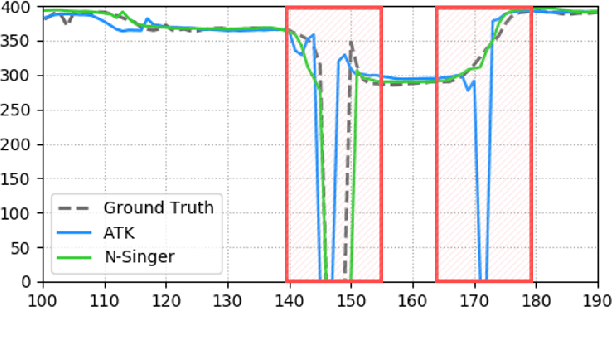
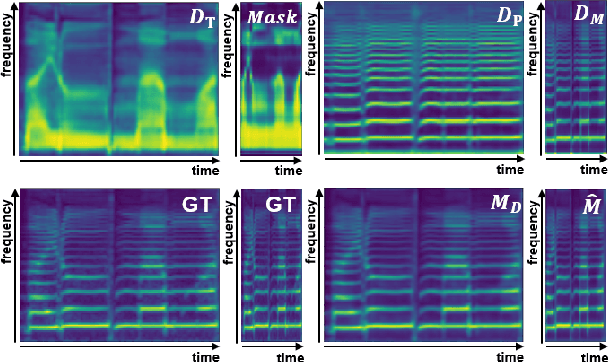
Recently, end-to-end Korean singing voice systems have been designed to generate realistic singing voices. However, these systems still suffer from a lack of robustness in terms of pronunciation accuracy. In this paper, we propose N-Singer, a non-autoregressive Korean singing voice system, to synthesize accurate and pronounced Korean singing voices in parallel. N-Singer consists of a Transformer-based mel-generator, a convolutional network-based postnet, and voicing-aware discriminators. It can contribute in the following ways. First, for accurate pronunciation, N-Singer separately models linguistic and pitch information without other acoustic features. Second, to achieve improved mel-spectrograms, N-Singer uses a combination of Transformer-based modules and convolutional network-based modules. Third, in adversarial training, voicing-aware conditional discriminators are used to capture the harmonic features of voiced segments and noise components of unvoiced segments. The experimental results prove that N-Singer can synthesize a natural singing voice in parallel with a more accurate pronunciation than the baseline model.