 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental dimension reduction for efficient and accurate visual anomaly detection
Feb 27, 2026While nowadays visual anomaly detection algorithms use deep neural networks to extract salient features from images, the high dimensionality of extracted features makes it difficult to apply those algorithms to large data with 1000s of images. To address this issue, we present an incremental dimension reduction algorithm to reduce the extracted features. While our algorithm essentially computes truncated singular value decomposition of these features, other than processing all vectors at once, our algorithm groups the vectors into batches. At each batch, our algorithm updates the truncated singular values and vectors that represent all visited vectors, and reduces each batch by its own singular values and vectors so they can be stored in the memory with low overhead. After processing all batches, we re-transform these batch-wise singular vectors to the space spanned by the singular vectors of all features. We show that our algorithm can accelerate the training of state-of-the-art anomaly detection algorithm with close accuracy.
VLASE: Vehicle Localization by Aggregating Semantic Edges
Jul 06, 2018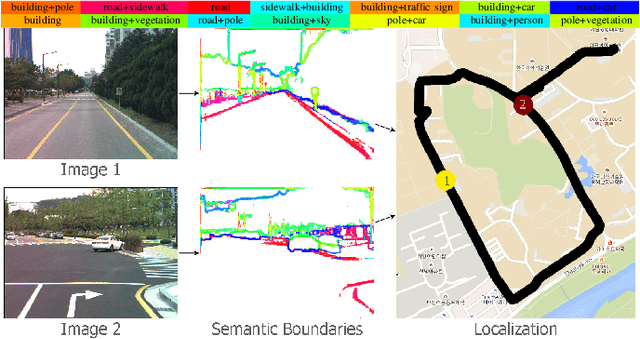
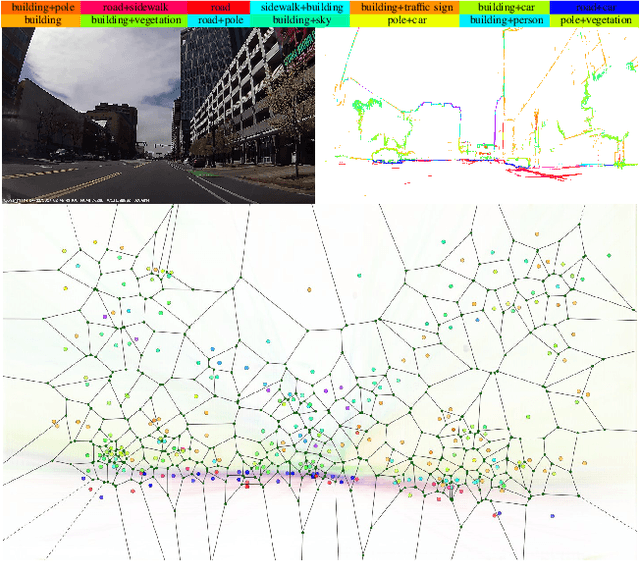
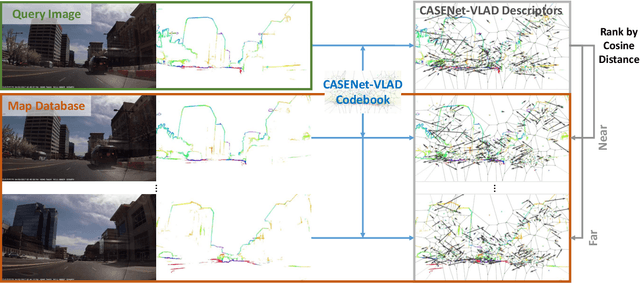
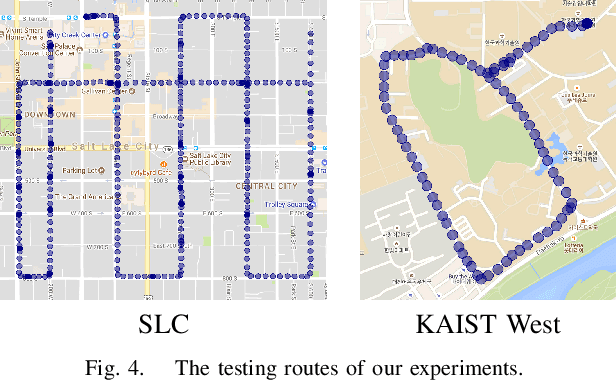
In this paper, we propose VLASE, a framework to use semantic edge features from images to achieve on-road localization. Semantic edge features denote edge contours that separate pairs of distinct objects such as building-sky, road- sidewalk, and building-ground. While prior work has shown promising results by utilizing the boundary between prominent classes such as sky and building using skylines, we generalize this approach to consider semantic edge features that arise from 19 different classes. Our localization algorithm is simple, yet very powerful. We extract semantic edge features using a recently introduced CASENet architecture and utilize VLAD framework to perform image retrieval. Our experiments show that we achieve improvement over some of the state-of-the-art localization algorithms such as SIFT-VLAD and its deep variant NetVLAD. We use ablation study to study the importance of different semantic classes and show that our unified approach achieves better performance compared to individual prominent features such as skylines.
Localization-Aware Active Learning for Object Detection
Jan 16, 2018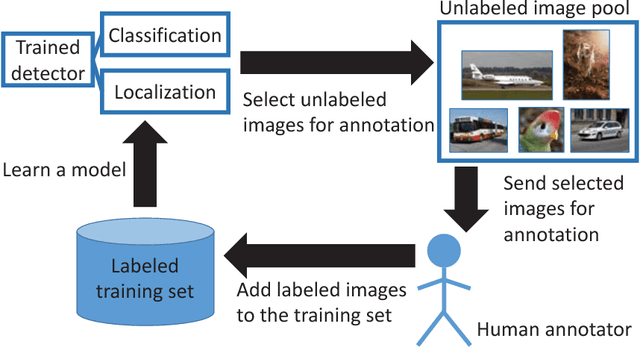


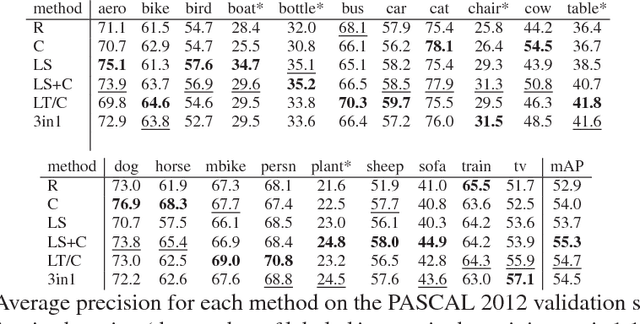
Active learning - a class of algorithms that iteratively searches for the most informative samples to include in a training dataset - has been shown to be effective at annotating data for image classification. However, the use of active learning for object detection is still largely unexplored as determining informativeness of an object-location hypothesis is more difficult. In this paper, we address this issue and present two metrics for measuring the informativeness of an object hypothesis, which allow us to leverage active learning to reduce the amount of annotated data needed to achieve a target object detection performance. Our first metric measures 'localization tightness' of an object hypothesis, which is based on the overlapping ratio between the region proposal and the final prediction. Our second metric measures 'localization stability' of an object hypothesis, which is based on the variation of predicted object locations when input images are corrupted by noise. Our experimental results show that by augmenting a conventional active-learning algorithm designed for classification with the proposed metrics, the amount of labeled training data required can be reduced up to 25%. Moreover, on PASCAL 2007 and 2012 datasets our localization-stability method has an average relative improvement of 96.5% and 81.9% over the baseline method using classification only.
Detecting and Grouping Identical Objects for Region Proposal and Classification
Jul 23, 2017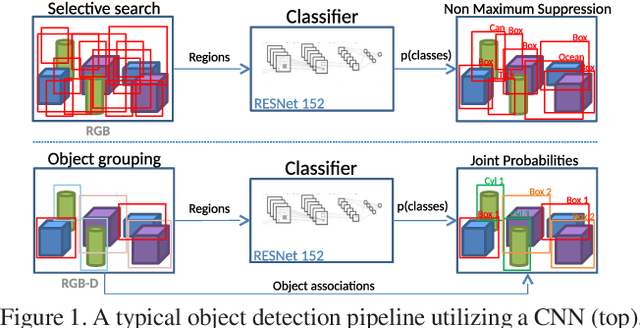

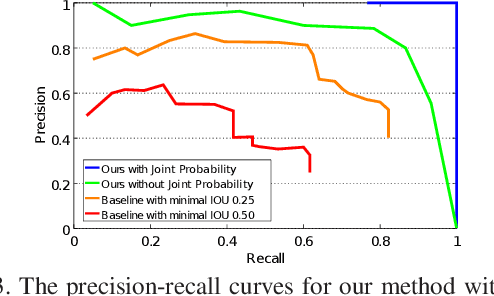
Often multiple instances of an object occur in the same scene, for example in a warehouse. Unsupervised multi-instance object discovery algorithms are able to detect and identify such objects. We use such an algorithm to provide object proposals to a convolutional neural network (CNN) based classifier. This results in fewer regions to evaluate, compared to traditional region proposal algorithms. Additionally, it enables using the joint probability of multiple instances of an object, resulting in improved classification accuracy. The proposed technique can also split a single class into multiple sub-classes corresponding to the different object types, enabling hierarchical classification.
Attention-Based Multimodal Fusion for Video Description
Mar 09, 2017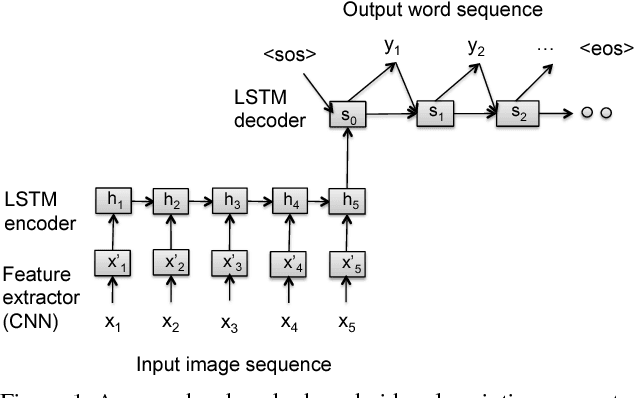
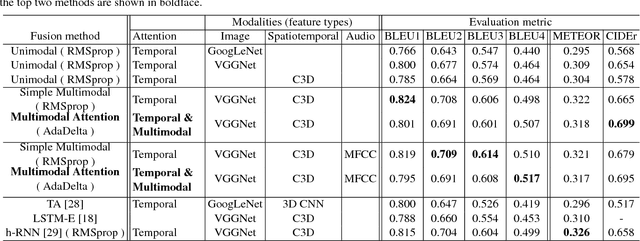
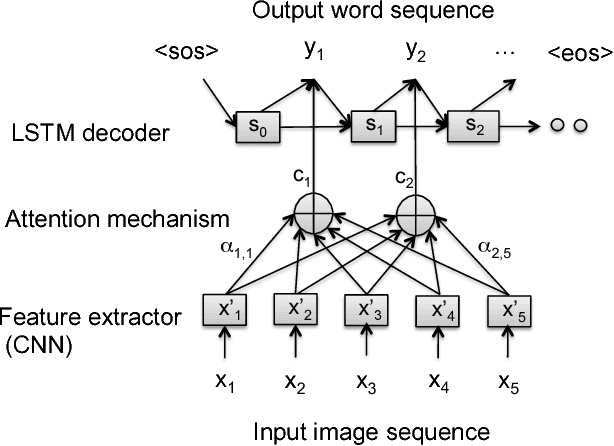
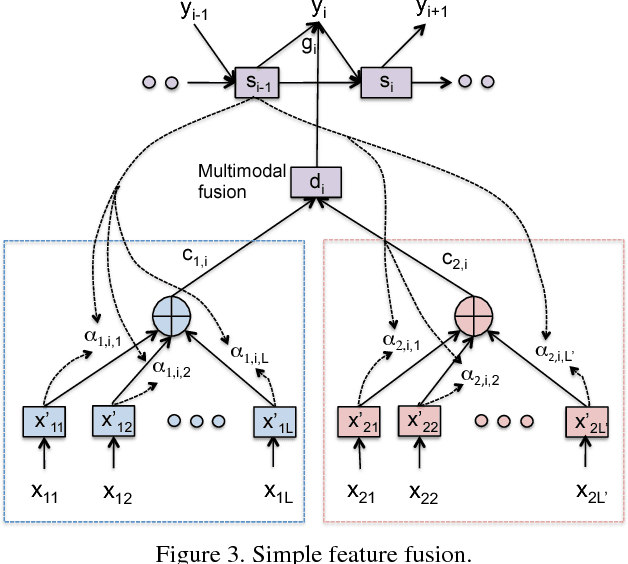
Currently successful methods for video description are based on encoder-decoder sentence generation using recur-rent neural networks (RNNs). Recent work has shown the advantage of integrating temporal and/or spatial attention mechanisms into these models, in which the decoder net-work predicts each word in the description by selectively giving more weight to encoded features from specific time frames (temporal attention) or to features from specific spatial regions (spatial attention). In this paper, we propose to expand the attention model to selectively attend not just to specific times or spatial regions, but to specific modalities of input such as image features, motion features, and audio features. Our new modality-dependent attention mechanism, which we call multimodal attention, provides a natural way to fuse multimodal information for video description. We evaluate our method on the Youtube2Text dataset, achieving results that are competitive with current state of the art. More importantly, we demonstrate that our model incorporating multimodal attention as well as temporal attention significantly outperforms the model that uses temporal attention alone.