 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle Similarity as Feedback for Product Design
May 25, 2021
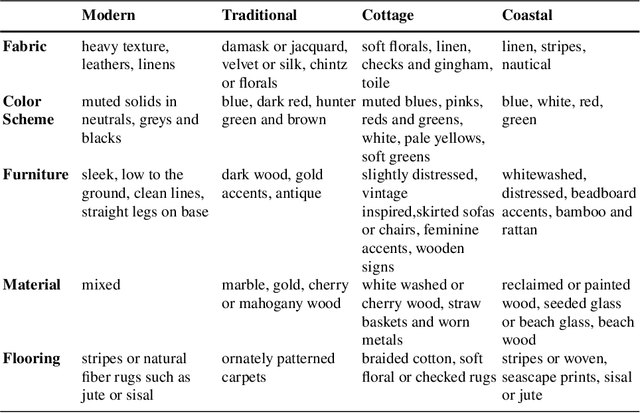


Matching and recommending products is beneficial for both customers and companies. With the rapid increase in home goods e-commerce, there is an increasing demand for quantitative methods for providing such recommendations for millions of products. This approach is facilitated largely by online stores such as Amazon and Wayfair, in which the goal is to maximize overall sales. Instead of focusing on overall sales, we take a product design perspective, by employing big-data analysis for determining the design qualities of a highly recommended product. Specifically, we focus on the visual style compatibility of such products. We build off previous work which implemented a style-based similarity metric for thousands of furniture products. Using analysis and visualization, we extract attributes of furniture products that are highly compatible style-wise. We propose a designer in-the-loop workflow that mirrors methods of displaying similar products to consumers browsing e-commerce websites. Our findings are useful when designing new products, since they provide insight regarding what furniture will be strongly compatible across multiple styles, and hence, more likely to be recommended.
* 15 pages, 9 figures, interdisciplinary book chapter on using computer vision and style similarity for industrial design
Image-Driven Furniture Style for Interactive 3D Scene Modeling
Oct 20, 2020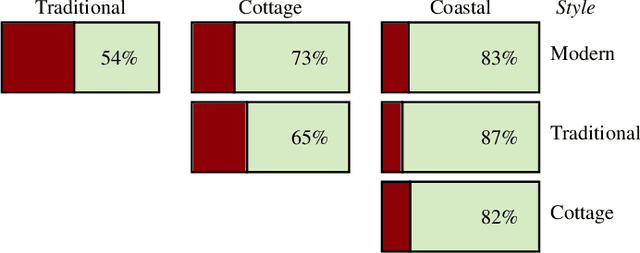

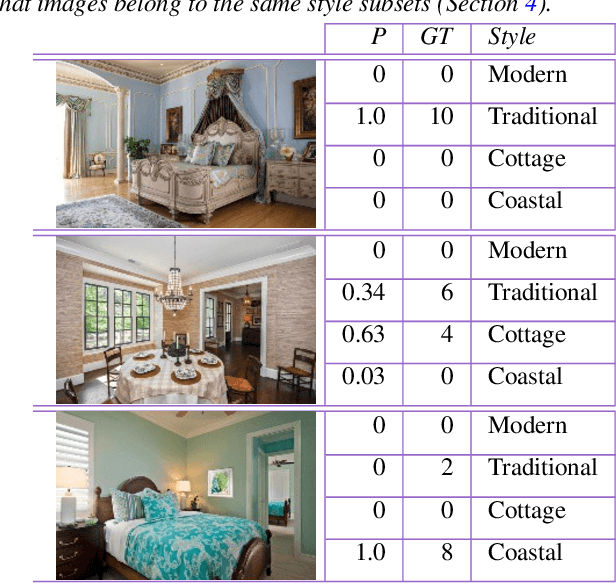
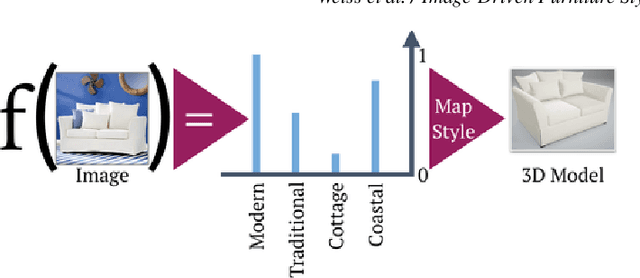
Creating realistic styled spaces is a complex task, which involves design know-how for what furniture pieces go well together. Interior style follows abstract rules involving color, geometry and other visual elements. Following such rules, users manually select similar-style items from large repositories of 3D furniture models, a process which is both laborious and time-consuming. We propose a method for fast-tracking style-similarity tasks, by learning a furniture's style-compatibility from interior scene images. Such images contain more style information than images depicting single furniture. To understand style, we train a deep learning network on a classification task. Based on image embeddings extracted from our network, we measure stylistic compatibility of furniture. We demonstrate our method with several 3D model style-compatibility results, and with an interactive system for modeling style-consistent scenes.
Verification of Very Low-Resolution Faces Using An Identity-Preserving Deep Face Super-Resolution Network
Mar 26, 2019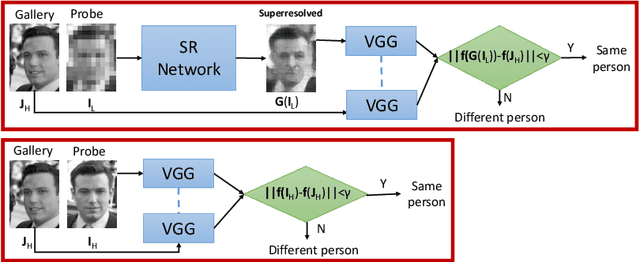
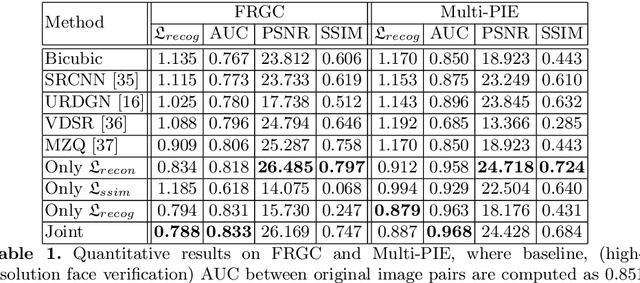
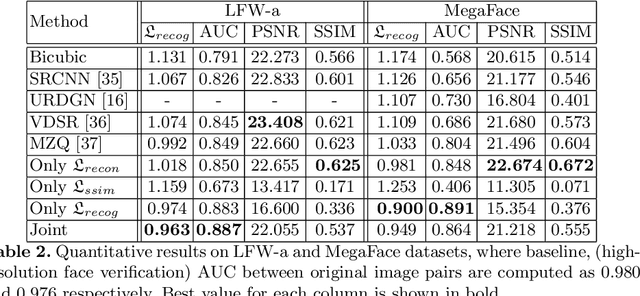
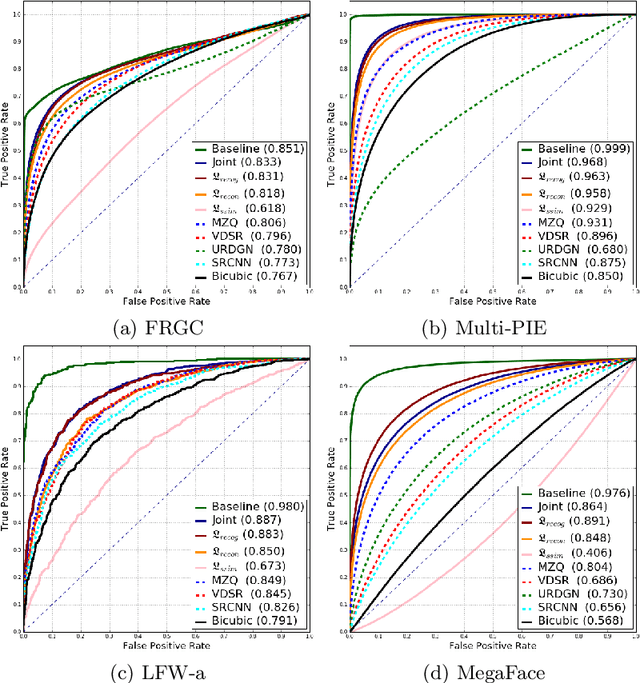
Face super-resolution methods usually aim at producing visually appealing results rather than preserving distinctive features for further face identification. In this work, we propose a deep learning method for face verification on very low-resolution face images that involves identity-preserving face super-resolution. Our framework includes a super-resolution network and a feature extraction network. We train a VGG-based deep face recognition network (Parkhi et al. 2015) to be used as feature extractor. Our super-resolution network is trained to minimize the feature distance between the high resolution ground truth image and the super-resolved image, where features are extracted using our pre-trained feature extraction network. We carry out experiments on FRGC, Multi-PIE, LFW-a, and MegaFace datasets to evaluate our method in controlled and uncontrolled settings. The results show that the presented method outperforms conventional super-resolution methods in low-resolution face verification.
Joint 3D Reconstruction of a Static Scene and Moving Objects
Feb 13, 2018
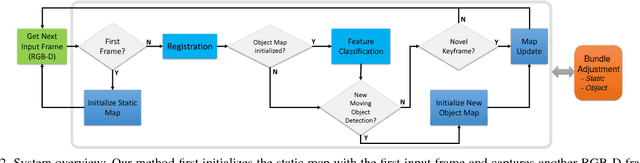
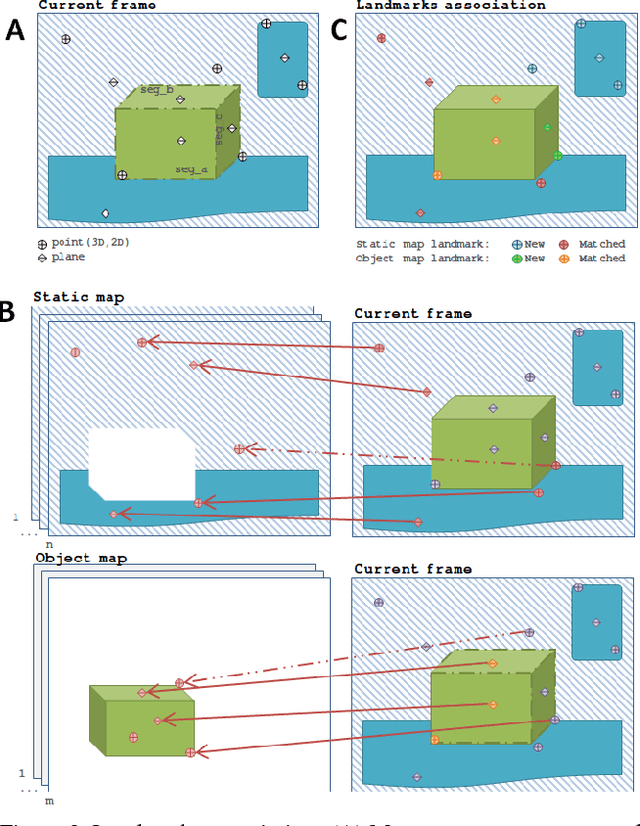

We present a technique for simultaneous 3D reconstruction of static regions and rigidly moving objects in a scene. An RGB-D frame is represented as a collection of features, which are points and planes. We classify the features into static and dynamic regions and grow separate maps, static and object maps, for each of them. To robustly classify the features in each frame, we fuse multiple RANSAC-based registration results obtained by registering different groups of the features to different maps, including (1) all the features to the static map, (2) all the features to each object map, and (3) subsets of the features, each forming a segment, to each object map. This multi-group registration approach is designed to overcome the following challenges: scenes can be dominated by static regions, making object tracking more difficult; and moving object might have larger pose variation between frames compared to the static regions. We show qualitative results from indoor scenes with objects in various shapes. The technique enables on-the-fly object model generation to be used for robotic manipulation.
* This paper has been accepted and presented in 3DV-2017 conference held at Qingdao, China. Video experiments: https://youtu.be/goflUxzG2VI
3D Object Discovery and Modeling Using Single RGB-D Images Containing Multiple Object Instances
Oct 17, 2017
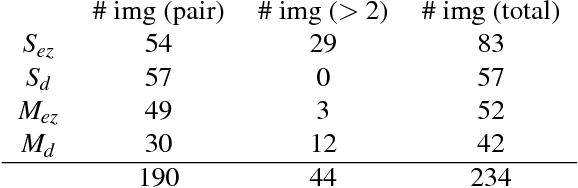
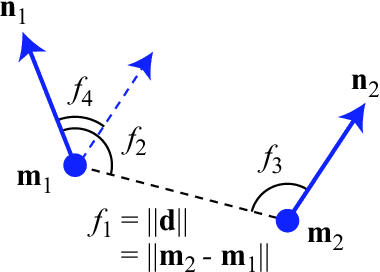
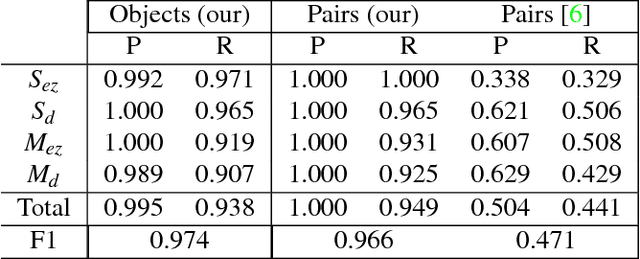
Unsupervised object modeling is important in robotics, especially for handling a large set of objects. We present a method for unsupervised 3D object discovery, reconstruction, and localization that exploits multiple instances of an identical object contained in a single RGB-D image. The proposed method does not rely on segmentation, scene knowledge, or user input, and thus is easily scalable. Our method aims to find recurrent patterns in a single RGB-D image by utilizing appearance and geometry of the salient regions. We extract keypoints and match them in pairs based on their descriptors. We then generate triplets of the keypoints matching with each other using several geometric criteria to minimize false matches. The relative poses of the matched triplets are computed and clustered to discover sets of triplet pairs with similar relative poses. Triplets belonging to the same set are likely to belong to the same object and are used to construct an initial object model. Detection of remaining instances with the initial object model using RANSAC allows to further expand and refine the model. The automatically generated object models are both compact and descriptive. We show quantitative and qualitative results on RGB-D images with various objects including some from the Amazon Picking Challenge. We also demonstrate the use of our method in an object picking scenario with a robotic arm.
Detecting and Grouping Identical Objects for Region Proposal and Classification
Jul 23, 2017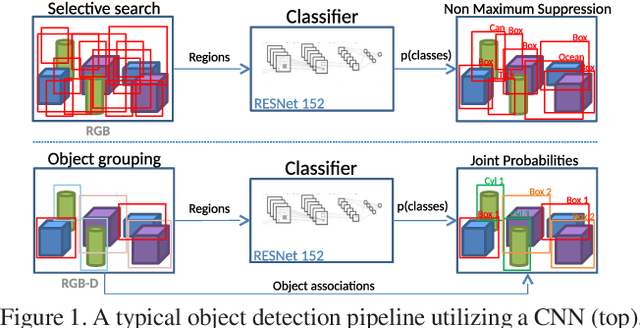

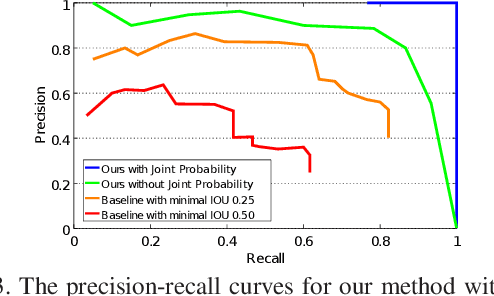
Often multiple instances of an object occur in the same scene, for example in a warehouse. Unsupervised multi-instance object discovery algorithms are able to detect and identify such objects. We use such an algorithm to provide object proposals to a convolutional neural network (CNN) based classifier. This results in fewer regions to evaluate, compared to traditional region proposal algorithms. Additionally, it enables using the joint probability of multiple instances of an object, resulting in improved classification accuracy. The proposed technique can also split a single class into multiple sub-classes corresponding to the different object types, enabling hierarchical classification.