 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Based Multimodal Fusion for Video Description
Mar 09, 2017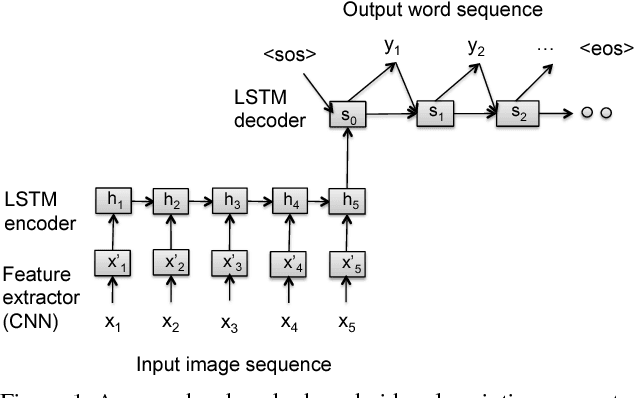
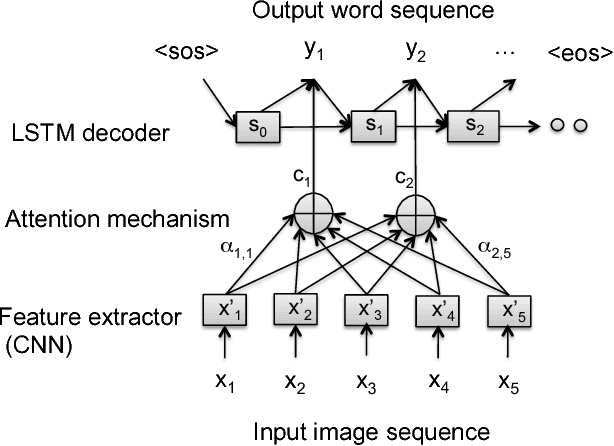
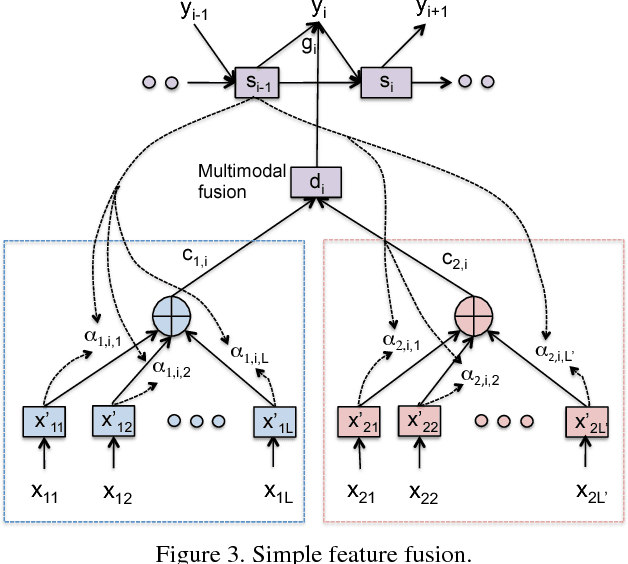
Currently successful methods for video description are based on encoder-decoder sentence generation using recur-rent neural networks (RNNs). Recent work has shown the advantage of integrating temporal and/or spatial attention mechanisms into these models, in which the decoder net-work predicts each word in the description by selectively giving more weight to encoded features from specific time frames (temporal attention) or to features from specific spatial regions (spatial attention). In this paper, we propose to expand the attention model to selectively attend not just to specific times or spatial regions, but to specific modalities of input such as image features, motion features, and audio features. Our new modality-dependent attention mechanism, which we call multimodal attention, provides a natural way to fuse multimodal information for video description. We evaluate our method on the Youtube2Text dataset, achieving results that are competitive with current state of the art. More importantly, we demonstrate that our model incorporating multimodal attention as well as temporal attention significantly outperforms the model that uses temporal attention alone.