 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJanuary Food Benchmark (JFB): A Public Benchmark Dataset and Evaluation Suite for Multimodal Food Analysis
Aug 13, 2025



Progress in AI for automated nutritional analysis is critically hampered by the lack of standardized evaluation methodologies and high-quality, real-world benchmark datasets. To address this, we introduce three primary contributions. First, we present the January Food Benchmark (JFB), a publicly available collection of 1,000 food images with human-validated annotations. Second, we detail a comprehensive benchmarking framework, including robust metrics and a novel, application-oriented overall score designed to assess model performance holistically. Third, we provide baseline results from both general-purpose Vision-Language Models (VLMs) and our own specialized model, january/food-vision-v1. Our evaluation demonstrates that the specialized model achieves an Overall Score of 86.2, a 12.1-point improvement over the best-performing general-purpose configuration. This work offers the research community a valuable new evaluation dataset and a rigorous framework to guide and benchmark future developments in automated nutritional analysis.
A Transformer-based survival model for prediction of all-cause mortality in heart failure patients: a multi-cohort study
Mar 16, 2025



We developed and validated TRisk, a Transformer-based AI model predicting 36-month mortality in heart failure patients by analysing temporal patient journeys from UK electronic health records (EHR). Our study included 403,534 heart failure patients (ages 40-90) from 1,418 English general practices, with 1,063 practices for model derivation and 355 for external validation. TRisk was compared against the MAGGIC-EHR model across various patient subgroups. With median follow-up of 9 months, TRisk achieved a concordance index of 0.845 (95% confidence interval: [0.841, 0.849]), significantly outperforming MAGGIC-EHR's 0.728 (0.723, 0.733) for predicting 36-month all-cause mortality. TRisk showed more consistent performance across sex, age, and baseline characteristics, suggesting less bias. We successfully adapted TRisk to US hospital data through transfer learning, achieving a C-index of 0.802 (0.789, 0.816) with 21,767 patients. Explainability analyses revealed TRisk captured established risk factors while identifying underappreciated predictors like cancers and hepatic failure that were important across both cohorts. Notably, cancers maintained strong prognostic value even a decade after diagnosis. TRisk demonstrated well-calibrated mortality prediction across both healthcare systems. Our findings highlight the value of tracking longitudinal health profiles and revealed risk factors not included in previous expert-driven models.
Training an Interactive Helper
Jul 02, 2019

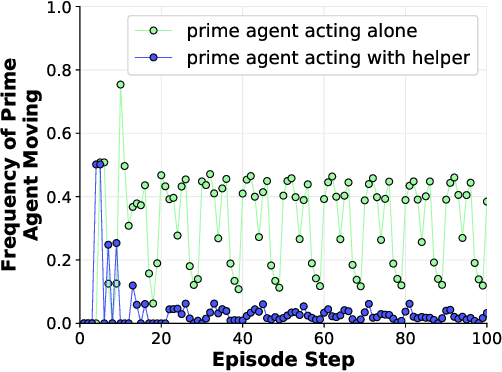
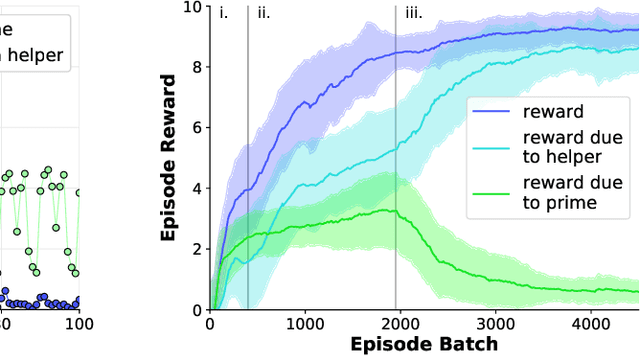
Developing agents that can quickly adapt their behavior to new tasks remains a challenge. Meta-learning has been applied to this problem, but previous methods require either specifying a reward function which can be tedious or providing demonstrations which can be inefficient. In this paper, we investigate if, and how, a "helper" agent can be trained to interactively adapt their behavior to maximize the reward of another agent, whom we call the "prime" agent, without observing their reward or receiving explicit demonstrations. To this end, we propose to meta-learn a helper agent along with a prime agent, who, during training, observes the reward function and serves as a surrogate for a human prime. We introduce a distribution of multi-agent cooperative foraging tasks, in which only the prime agent knows the objects that should be collected. We demonstrate that, from the emerged physical communication, the trained helper rapidly infers and collects the correct objects.
Learning to Interactively Learn and Assist
Jul 01, 2019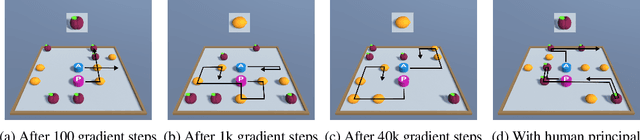

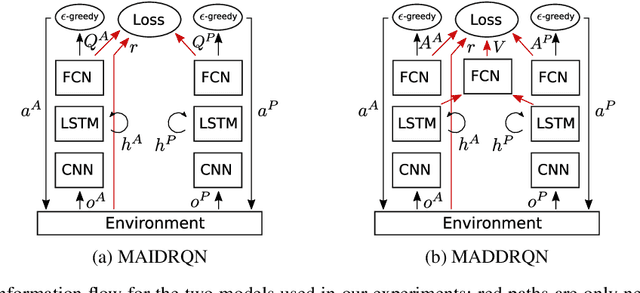

When deploying autonomous agents in the real world, we need effective ways of communicating objectives to them. Traditional skill learning has revolved around reinforcement and imitation learning, each with rigid constraints on the format of information exchanged between the human and the agent. While scalar rewards carry little information, demonstrations require significant effort to provide and may carry more information than is necessary. Furthermore, rewards and demonstrations are often defined and collected before training begins, when the human is most uncertain about what information would help the agent. In contrast, when humans communicate objectives with each other, they make use of a large vocabulary of informative behaviors, including non-verbal communication, and often communicate throughout learning, responding to observed behavior. In this way, humans communicate intent with minimal effort. In this paper, we propose such interactive learning as an alternative to reward or demonstration-driven learning. To accomplish this, we introduce a multi-agent training framework that enables an agent to learn from another agent who knows the current task. Through a series of experiments, we demonstrate the emergence of a variety of interactive learning behaviors, including information-sharing, information-seeking, and question-answering. Most importantly, we find that our approach produces an agent that is capable of learning interactively from a human user, without a set of explicit demonstrations or a reward function, and achieving significantly better performance cooperatively with a human than a human performing the task alone.
Active One-shot Learning
Feb 21, 2017



Recent advances in one-shot learning have produced models that can learn from a handful of labeled examples, for passive classification and regression tasks. This paper combines reinforcement learning with one-shot learning, allowing the model to decide, during classification, which examples are worth labeling. We introduce a classification task in which a stream of images are presented and, on each time step, a decision must be made to either predict a label or pay to receive the correct label. We present a recurrent neural network based action-value function, and demonstrate its ability to learn how and when to request labels. Through the choice of reward function, the model can achieve a higher prediction accuracy than a similar model on a purely supervised task, or trade prediction accuracy for fewer label requests.