 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Media Engagement and Cryptocurrency Performance
Sep 07, 2022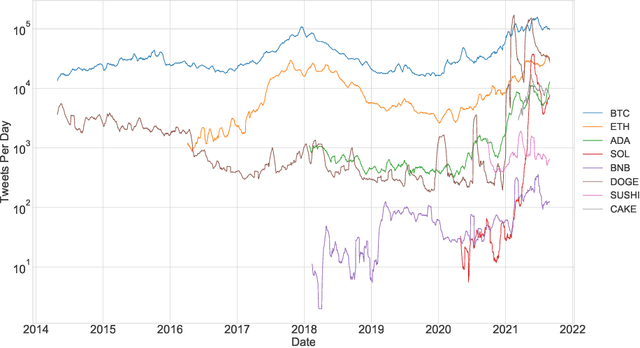
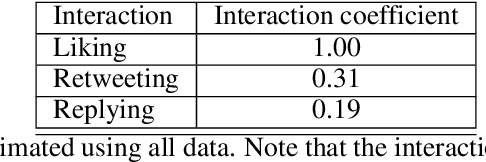
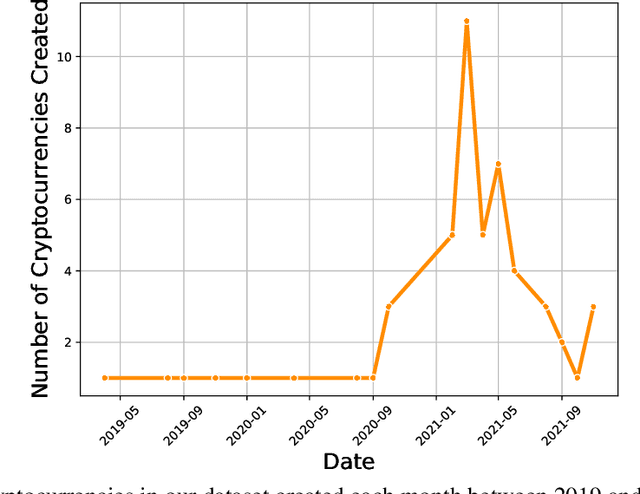
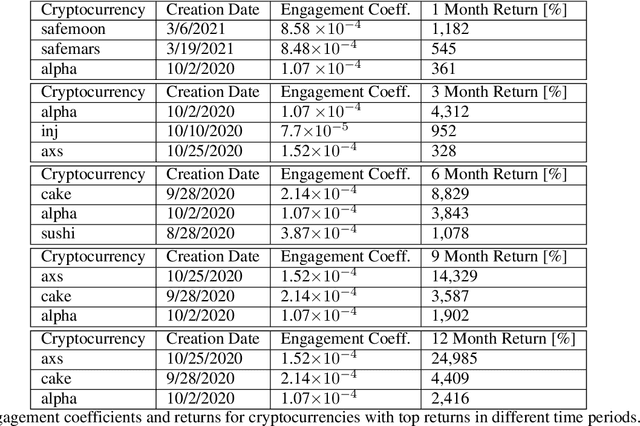
We study the problem of predicting the future performance of cryptocurrencies using social media data. We propose a new model to measure the engagement of users with topics discussed on social media based on interactions with social media posts. This model overcomes the limitations of previous volume and sentiment based approaches. We use this model to estimate engagement coefficients for 48 cryptocurrencies created between 2019 and 2021 using data from Twitter from the first month of the cryptocurrencies' existence. We find that the future returns of the cryptocurrencies are dependent on the engagement coefficients. Cryptocurrencies whose engagement coefficients are too low or too high have lower returns. Low engagement coefficients signal a lack of interest, while high engagement coefficients signal artificial activity which is likely from automated accounts known as bots. We measure the amount of bot posts for the cryptocurrencies and find that generally, cryptocurrencies with more bot posts have lower future returns. While future returns are dependent on both the bot activity and engagement coefficient, the dependence is strongest for the engagement coefficient, especially for short-term returns. We show that simple investment strategies which select cryptocurrencies with engagement coefficients exceeding a fixed threshold perform well for holding times of a few months.
Optimal Dispatch in Emergency Service System via Reinforcement Learning
Oct 15, 2020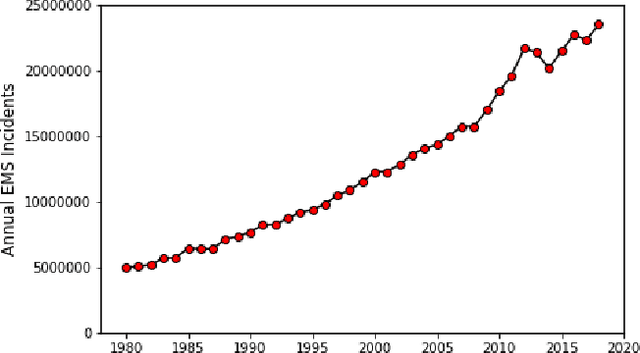
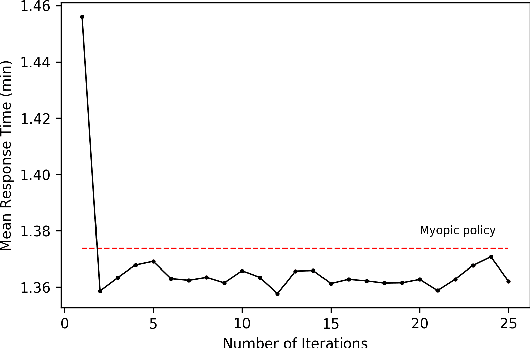
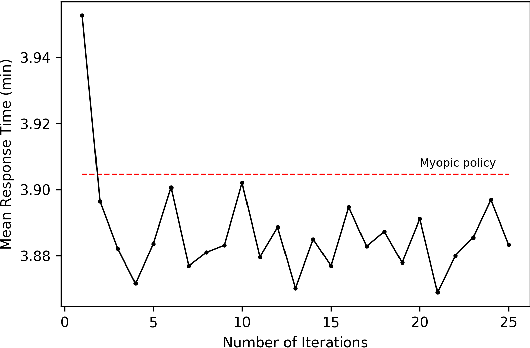
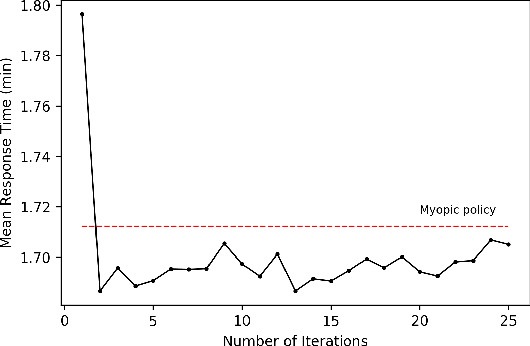
In the United States, medical responses by fire departments over the last four decades increased by 367%. This had made it critical to decision makers in emergency response departments that existing resources are efficiently used. In this paper, we model the ambulance dispatch problem as an average-cost Markov decision process and present a policy iteration approach to find an optimal dispatch policy. We then propose an alternative formulation using post-decision states that is shown to be mathematically equivalent to the original model, but with a much smaller state space. We present a temporal difference learning approach to the dispatch problem based on the post-decision states. In our numerical experiments, we show that our obtained temporal-difference policy outperforms the benchmark myopic policy. Our findings suggest that emergency response departments can improve their performance with minimal to no cost.
Leaders, Followers, and Community Detectio
Jun 29, 2018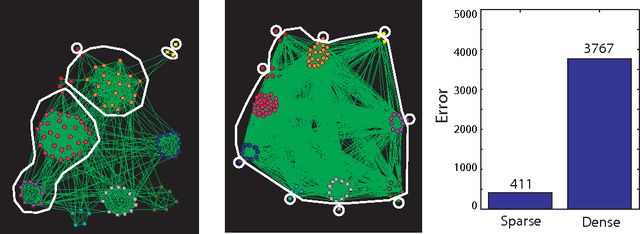
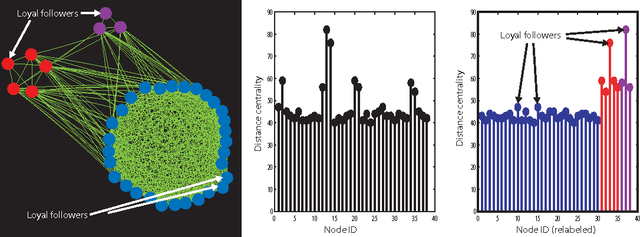
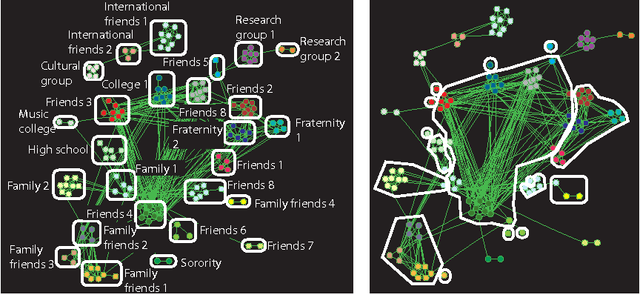
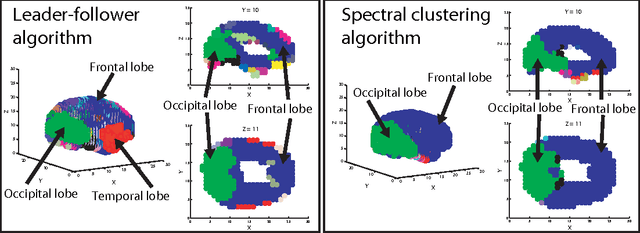
Communities in social networks or graphs are sets of well-connected, overlapping vertices. The effectiveness of a community detection algorithm is determined by accuracy in finding the ground-truth communities and ability to scale with the size of the data. In this work, we provide three contributions. First, we show that a popular measure of accuracy known as the F1 score, which is between 0 and 1, with 1 being perfect detection, has an information lower bound is 0.5. We provide a trivial algorithm that produces communities with an F1 score of 0.5 for any graph! Somewhat surprisingly, we find that popular algorithms such as modularity optimization, BigClam and CESNA have F1 scores less than 0.5 for the popular IMDB graph. To rectify this, as the second contribution we propose a generative model for community formation, the sequential community graph, which is motivated by the formation of social networks. Third, motivated by our generative model, we propose the leader-follower algorithm (LFA). We prove that it recovers all communities for sequential community graphs by establishing a structural result that sequential community graphs are chordal. For a large number of popular social networks, it recovers communities with a much higher F1 score than other popular algorithms. For the IMDB graph, it obtains an F1 score of 0.81. We also propose a modification to the LFA called the fast leader-follower algorithm (FLFA) which in addition to being highly accurate, is also fast, with a scaling that is almost linear in the network size.
Rumors in a Network: Who's the Culprit?
Oct 29, 2010
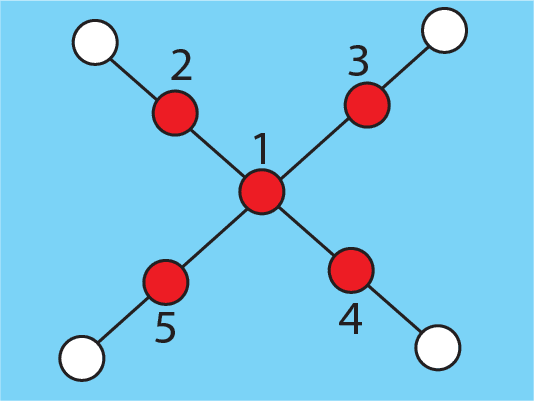

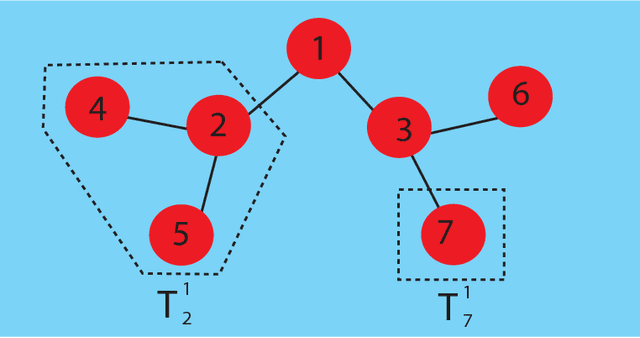
We provide a systematic study of the problem of finding the source of a rumor in a network. We model rumor spreading in a network with a variant of the popular SIR model and then construct an estimator for the rumor source. This estimator is based upon a novel topological quantity which we term \textbf{rumor centrality}. We establish that this is an ML estimator for a class of graphs. We find the following surprising threshold phenomenon: on trees which grow faster than a line, the estimator always has non-trivial detection probability, whereas on trees that grow like a line, the detection probability will go to 0 as the network grows. Simulations performed on synthetic networks such as the popular small-world and scale-free networks, and on real networks such as an internet AS network and the U.S. electric power grid network, show that the estimator either finds the source exactly or within a few hops of the true source across different network topologies. We compare rumor centrality to another common network centrality notion known as distance centrality. We prove that on trees, the rumor center and distance center are equivalent, but on general networks, they may differ. Indeed, simulations show that rumor centrality outperforms distance centrality in finding rumor sources in networks which are not tree-like.