 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComLQ: Benchmarking Complex Logical Queries in Information Retrieval
Nov 15, 2025

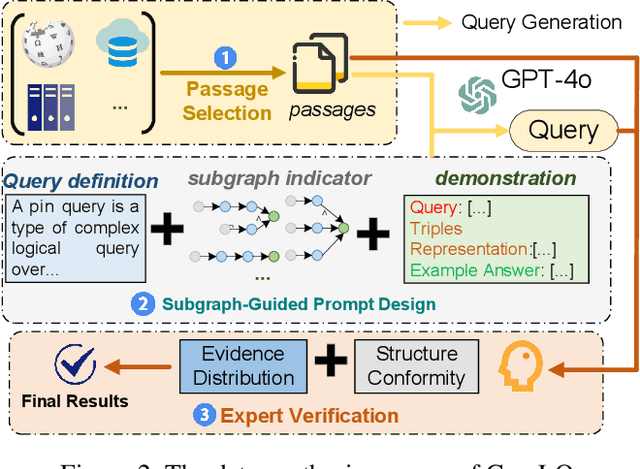

Information retrieval (IR) systems play a critical role in navigating information overload across various applications. Existing IR benchmarks primarily focus on simple queries that are semantically analogous to single- and multi-hop relations, overlooking \emph{complex logical queries} involving first-order logic operations such as conjunction ($\land$), disjunction ($\lor$), and negation ($\lnot$). Thus, these benchmarks can not be used to sufficiently evaluate the performance of IR models on complex queries in real-world scenarios. To address this problem, we propose a novel method leveraging large language models (LLMs) to construct a new IR dataset \textbf{ComLQ} for \textbf{Com}plex \textbf{L}ogical \textbf{Q}ueries, which comprises 2,909 queries and 11,251 candidate passages. A key challenge in constructing the dataset lies in capturing the underlying logical structures within unstructured text. Therefore, by designing the subgraph-guided prompt with the subgraph indicator, an LLM (such as GPT-4o) is guided to generate queries with specific logical structures based on selected passages. All query-passage pairs in ComLQ are ensured \emph{structure conformity} and \emph{evidence distribution} through expert annotation. To better evaluate whether retrievers can handle queries with negation, we further propose a new evaluation metric, \textbf{Log-Scaled Negation Consistency} (\textbf{LSNC@$K$}). As a supplement to standard relevance-based metrics (such as nDCG and mAP), LSNC@$K$ measures whether top-$K$ retrieved passages violate negation conditions in queries. Our experimental results under zero-shot settings demonstrate existing retrieval models' limited performance on complex logical queries, especially on queries with negation, exposing their inferior capabilities of modeling exclusion.
Logical Consistency is Vital: Neural-Symbolic Information Retrieval for Negative-Constraint Queries
May 29, 2025

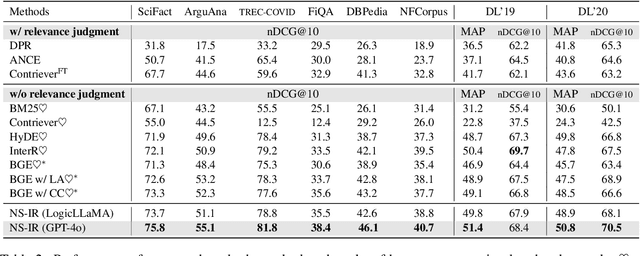
Information retrieval plays a crucial role in resource localization. Current dense retrievers retrieve the relevant documents within a corpus via embedding similarities, which compute similarities between dense vectors mainly depending on word co-occurrence between queries and documents, but overlook the real query intents. Thus, they often retrieve numerous irrelevant documents. Particularly in the scenarios of complex queries such as \emph{negative-constraint queries}, their retrieval performance could be catastrophic. To address the issue, we propose a neuro-symbolic information retrieval method, namely \textbf{NS-IR}, that leverages first-order logic (FOL) to optimize the embeddings of naive natural language by considering the \emph{logical consistency} between queries and documents. Specifically, we introduce two novel techniques, \emph{logic alignment} and \emph{connective constraint}, to rerank candidate documents, thereby enhancing retrieval relevance. Furthermore, we construct a new dataset \textbf{NegConstraint} including negative-constraint queries to evaluate our NS-IR's performance on such complex IR scenarios. Our extensive experiments demonstrate that NS-IR not only achieves superior zero-shot retrieval performance on web search and low-resource retrieval tasks, but also performs better on negative-constraint queries. Our scource code and dataset are available at https://github.com/xgl-git/NS-IR-main.
Indeterminate Probability Neural Network
Mar 21, 2023



We propose a new general model called IPNN - Indeterminate Probability Neural Network, which combines neural network and probability theory together. In the classical probability theory, the calculation of probability is based on the occurrence of events, which is hardly used in current neural networks. In this paper, we propose a new general probability theory, which is an extension of classical probability theory, and makes classical probability theory a special case to our theory. Besides, for our proposed neural network framework, the output of neural network is defined as probability events, and based on the statistical analysis of these events, the inference model for classification task is deduced. IPNN shows new property: It can perform unsupervised clustering while doing classification. Besides, IPNN is capable of making very large classification with very small neural network, e.g. model with 100 output nodes can classify 10 billion categories. Theoretical advantages are reflected in experimental results.
Gradient-Based Meta-Learning Using Uncertainty to Weigh Loss for Few-Shot Learning
Aug 17, 2022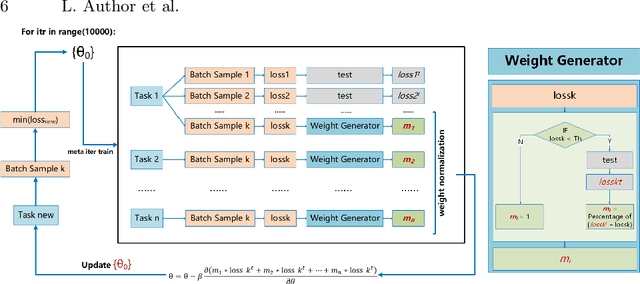
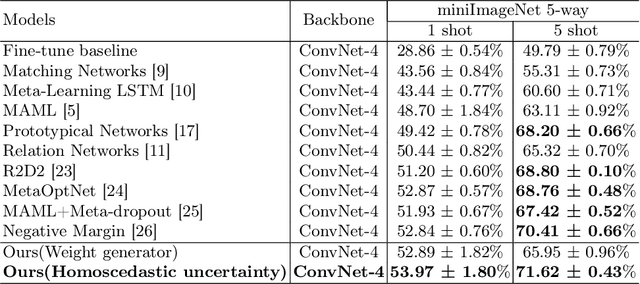
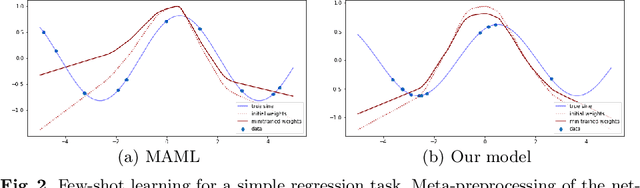
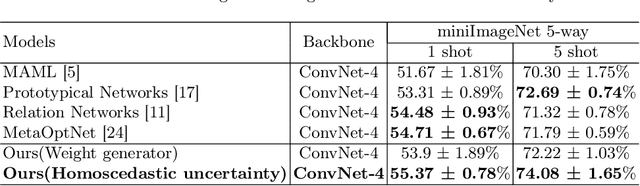
Model-Agnostic Meta-Learning (MAML) is one of the most successful meta-learning techniques for few-shot learning. It uses gradient descent to learn commonalities between various tasks, enabling the model to learn the meta-initialization of its own parameters to quickly adapt to new tasks using a small amount of labeled training data. A key challenge to few-shot learning is task uncertainty. Although a strong prior can be obtained from meta-learning with a large number of tasks, a precision model of the new task cannot be guaranteed because the volume of the training dataset is normally too small. In this study, first,in the process of choosing initialization parameters, the new method is proposed for task-specific learner adaptively learn to select initialization parameters that minimize the loss of new tasks. Then, we propose two improved methods for the meta-loss part: Method 1 generates weights by comparing meta-loss differences to improve the accuracy when there are few classes, and Method 2 introduces the homoscedastic uncertainty of each task to weigh multiple losses based on the original gradient descent,as a way to enhance the generalization ability to novel classes while ensuring accuracy improvement. Compared with previous gradient-based meta-learning methods, our model achieves better performance in regression tasks and few-shot classification and improves the robustness of the model to the learning rate and query sets in the meta-test set.
Using EBGAN for Anomaly Intrusion Detection
Jun 21, 2022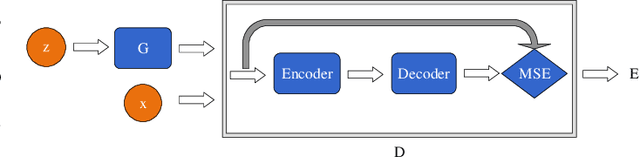
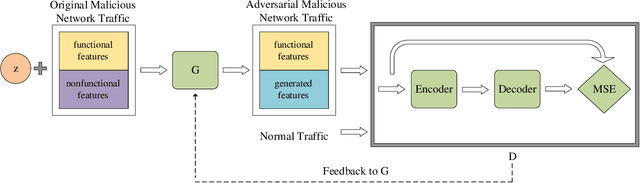
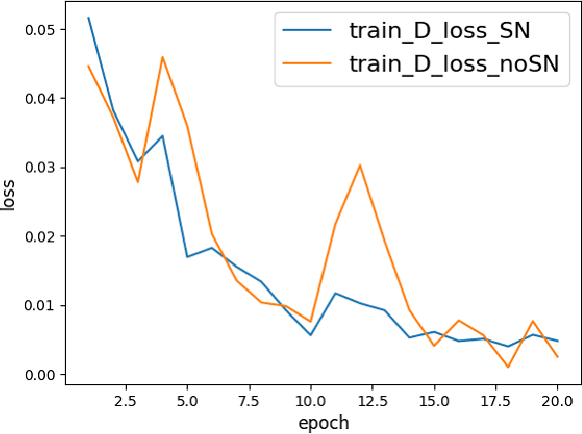
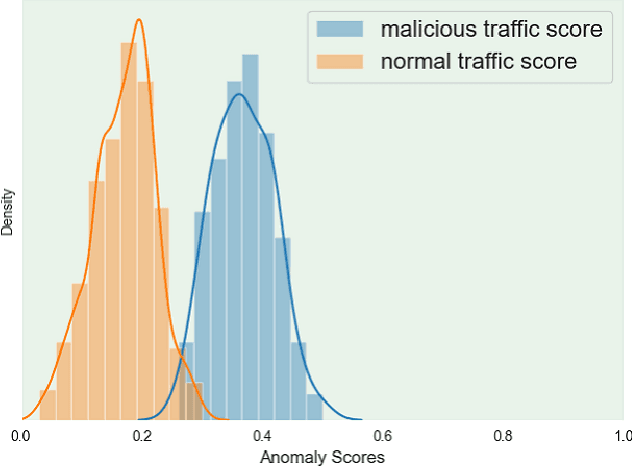
As an active network security protection scheme, intrusion detection system (IDS) undertakes the important responsibility of detecting network attacks in the form of malicious network traffic. Intrusion detection technology is an important part of IDS. At present, many scholars have carried out extensive research on intrusion detection technology. However, developing an efficient intrusion detection method for massive network traffic data is still difficult. Since Generative Adversarial Networks (GANs) have powerful modeling capabilities for complex high-dimensional data, they provide new ideas for addressing this problem. In this paper, we put forward an EBGAN-based intrusion detection method, IDS-EBGAN, that classifies network records as normal traffic or malicious traffic. The generator in IDS-EBGAN is responsible for converting the original malicious network traffic in the training set into adversarial malicious examples. This is because we want to use adversarial learning to improve the ability of discriminator to detect malicious traffic. At the same time, the discriminator adopts Autoencoder model. During testing, IDS-EBGAN uses reconstruction error of discriminator to classify traffic records.
Method to Annotate Arrhythmias by Deep Network
Jun 09, 2018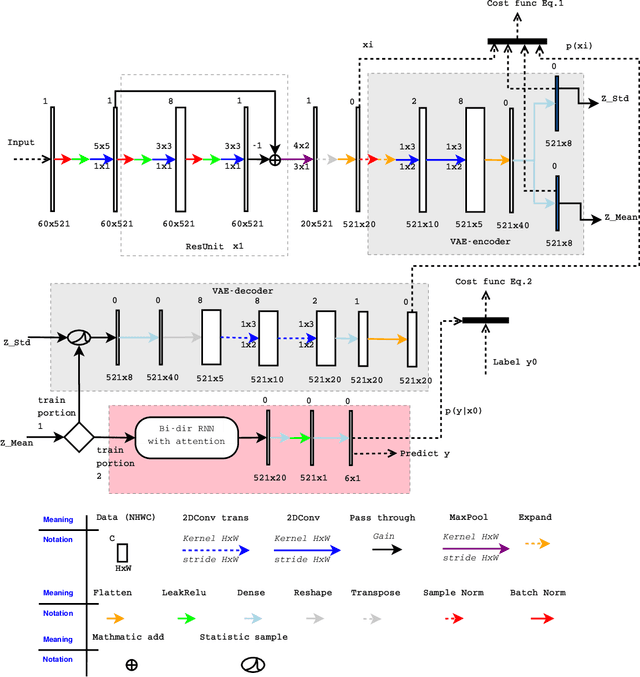
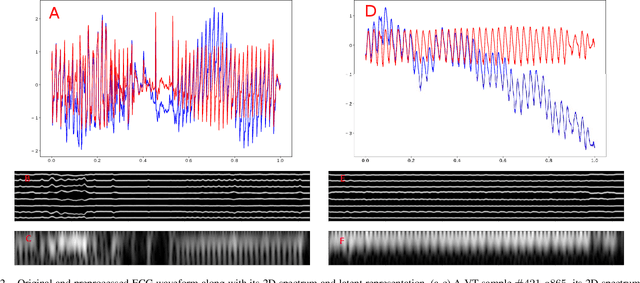

This study targets to automatically annotate on arrhythmia by deep network. The investigated types include sinus rhythm, asystole (Asys), supraventricular tachycardia (Tachy), ventricular flutter or fibrillation (VF/VFL), ventricular tachycardia (VT). Methods: 13s limb lead ECG chunks from MIT malignant ventricular arrhythmia database (VFDB) and MIT normal sinus rhythm database were partitioned into subsets for 5-fold cross validation. These signals were resampled to 200Hz, filtered to remove baseline wandering, projected to 2D gray spectrum and then fed into a deep network with brand-new structure. In this network, a feature vector for a single time point was retrieved by residual layers, from which latent representation was extracted by variational autoencoder (VAE). These front portions were trained to meet a certain threshold in loss function, then fixed while training procedure switched to remaining bidirectional recurrent neural network (RNN), the very portions to predict an arrhythmia category. Attention windows were polynomial lumped on RNN outputs for learning from details to outlines. And over sampling was employed for imbalanced data. The trained model was wrapped into docker image for deployment in edge or cloud. Conclusion: Promising sensitivities were achieved in four arrhythmias and good precision rates in two ventricular arrhythmias were also observed. Moreover, it was proven that latent representation by VAE, can significantly boost the speed of convergence and accuracy.