 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-the-fly Large-scale 3D Reconstruction from Multi-Camera Rigs
Dec 09, 2025Recent advances in 3D Gaussian Splatting (3DGS) have enabled efficient free-viewpoint rendering and photorealistic scene reconstruction. While on-the-fly extensions of 3DGS have shown promise for real-time reconstruction from monocular RGB streams, they often fail to achieve complete 3D coverage due to the limited field of view (FOV). Employing a multi-camera rig fundamentally addresses this limitation. In this paper, we present the first on-the-fly 3D reconstruction framework for multi-camera rigs. Our method incrementally fuses dense RGB streams from multiple overlapping cameras into a unified Gaussian representation, achieving drift-free trajectory estimation and efficient online reconstruction. We propose a hierarchical camera initialization scheme that enables coarse inter-camera alignment without calibration, followed by a lightweight multi-camera bundle adjustment that stabilizes trajectories while maintaining real-time performance. Furthermore, we introduce a redundancy-free Gaussian sampling strategy and a frequency-aware optimization scheduler to reduce the number of Gaussian primitives and the required optimization iterations, thereby maintaining both efficiency and reconstruction fidelity. Our method reconstructs hundreds of meters of 3D scenes within just 2 minutes using only raw multi-camera video streams, demonstrating unprecedented speed, robustness, and Fidelity for on-the-fly 3D scene reconstruction.
FedHL: Federated Learning for Heterogeneous Low-Rank Adaptation via Unbiased Aggregation
May 24, 2025



Federated Learning (FL) facilitates the fine-tuning of Foundation Models (FMs) using distributed data sources, with Low-Rank Adaptation (LoRA) gaining popularity due to its low communication costs and strong performance. While recent work acknowledges the benefits of heterogeneous LoRA in FL and introduces flexible algorithms to support its implementation, our theoretical analysis reveals a critical gap: existing methods lack formal convergence guarantees due to parameter truncation and biased gradient updates. Specifically, adapting client-specific LoRA ranks necessitates truncating global parameters, which introduces inherent truncation errors and leads to subsequent inaccurate gradient updates that accumulate over training rounds, ultimately degrading performance. To address the above issues, we propose \textbf{FedHL}, a simple yet effective \textbf{Fed}erated Learning framework tailored for \textbf{H}eterogeneous \textbf{L}oRA. By leveraging the full-rank global model as a calibrated aggregation basis, FedHL eliminates the direct truncation bias from initial alignment with client-specific ranks. Furthermore, we derive the theoretically optimal aggregation weights by minimizing the gradient drift term in the convergence upper bound. Our analysis shows that FedHL guarantees $\mathcal{O}(1/\sqrt{T})$ convergence rate, and experiments on multiple real-world datasets demonstrate a 1-3\% improvement over several state-of-the-art methods.
Federated Learning for Diffusion Models
Mar 09, 2025Diffusion models are powerful generative models that can produce highly realistic samples for various tasks. Typically, these models are constructed using centralized, independently and identically distributed (IID) training data. However, in practical scenarios, data is often distributed across multiple clients and frequently manifests non-IID characteristics. Federated Learning (FL) can leverage this distributed data to train diffusion models, but the performance of existing FL methods is unsatisfactory in non-IID scenarios. To address this, we propose FedDDPM-Federated Learning with Denoising Diffusion Probabilistic Models, which leverages the data generative capability of diffusion models to facilitate model training. In particular, the server uses well-trained local diffusion models uploaded by each client before FL training to generate auxiliary data that can approximately represent the global data distribution. Following each round of model aggregation, the server further optimizes the global model using the auxiliary dataset to alleviate the impact of heterogeneous data on model performance. We provide a rigorous convergence analysis of FedDDPM and propose an enhanced algorithm, FedDDPM+, to reduce training overheads. FedDDPM+ detects instances of slow model learning and performs a one-shot correction using the auxiliary dataset. Experimental results validate that our proposed algorithms outperform the state-of-the-art FL algorithms on the MNIST, CIFAR10 and CIFAR100 datasets.
Neighborhood and Global Perturbations Supported SAM in Federated Learning: From Local Tweaks To Global Awareness
Aug 26, 2024



Federated Learning (FL) can be coordinated under the orchestration of a central server to collaboratively build a privacy-preserving model without the need for data exchange. However, participant data heterogeneity leads to local optima divergence, subsequently affecting convergence outcomes. Recent research has focused on global sharpness-aware minimization (SAM) and dynamic regularization techniques to enhance consistency between global and local generalization and optimization objectives. Nonetheless, the estimation of global SAM introduces additional computational and memory overhead, while dynamic regularization suffers from bias in the local and global dual variables due to training isolation. In this paper, we propose a novel FL algorithm, FedTOGA, designed to consider optimization and generalization objectives while maintaining minimal uplink communication overhead. By linking local perturbations to global updates, global generalization consistency is improved. Additionally, global updates are used to correct local dynamic regularizers, reducing dual variables bias and enhancing optimization consistency. Global updates are passively received by clients, reducing overhead. We also propose neighborhood perturbation to approximate local perturbation, analyzing its strengths and limitations. Theoretical analysis shows FedTOGA achieves faster convergence $O(1/T)$ under non-convex functions. Empirical studies demonstrate that FedTOGA outperforms state-of-the-art algorithms, with a 1\% accuracy increase and 30\% faster convergence, achieving state-of-the-art.
Gradient-Based Meta-Learning Using Uncertainty to Weigh Loss for Few-Shot Learning
Aug 17, 2022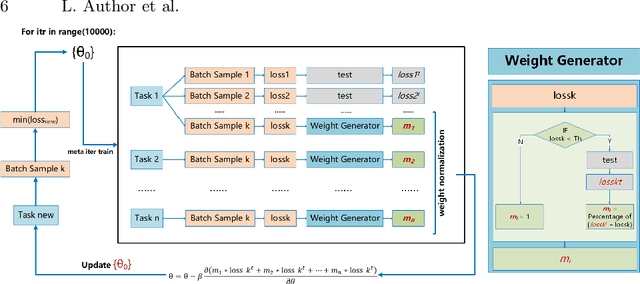
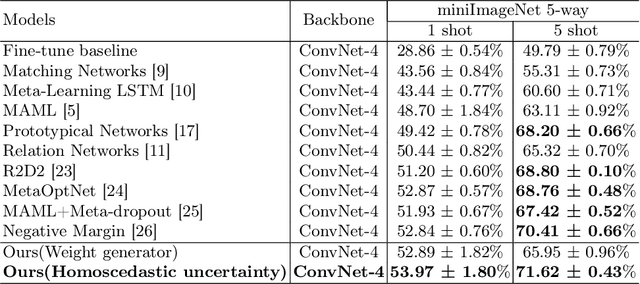
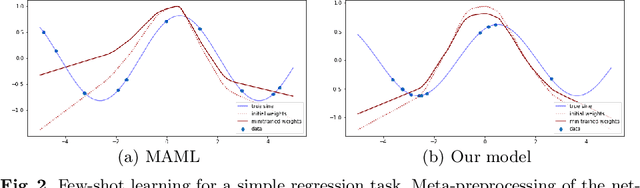
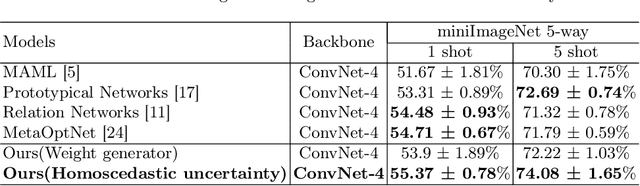
Model-Agnostic Meta-Learning (MAML) is one of the most successful meta-learning techniques for few-shot learning. It uses gradient descent to learn commonalities between various tasks, enabling the model to learn the meta-initialization of its own parameters to quickly adapt to new tasks using a small amount of labeled training data. A key challenge to few-shot learning is task uncertainty. Although a strong prior can be obtained from meta-learning with a large number of tasks, a precision model of the new task cannot be guaranteed because the volume of the training dataset is normally too small. In this study, first,in the process of choosing initialization parameters, the new method is proposed for task-specific learner adaptively learn to select initialization parameters that minimize the loss of new tasks. Then, we propose two improved methods for the meta-loss part: Method 1 generates weights by comparing meta-loss differences to improve the accuracy when there are few classes, and Method 2 introduces the homoscedastic uncertainty of each task to weigh multiple losses based on the original gradient descent,as a way to enhance the generalization ability to novel classes while ensuring accuracy improvement. Compared with previous gradient-based meta-learning methods, our model achieves better performance in regression tasks and few-shot classification and improves the robustness of the model to the learning rate and query sets in the meta-test set.