 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Multi-bit Generative Watermarking Schemes Under Worst-Case False-Alarm Constraints
Apr 09, 2026This paper considers the problem of multi-bit generative watermarking for large language models under a worst-case false-alarm constraint. Prior work established a lower bound on the achievable miss-detection probability in the finite-token regime and proposed a scheme claimed to achieve this bound. We show, however, that the proposed scheme is in fact suboptimal. We then develop two new encoding-decoding constructions that attain the previously established lower bound, thereby completely characterizing the optimal multi-bit watermarking performance. Our approach formulates the watermark design problem as a linear program and derives the structural conditions under which optimality can be achieved. In addition, we identify the failure mechanism of the previous construction and compare the tradeoffs between the two proposed schemes.
Reinforcement Learning for Diffusion LLMs with Entropy-Guided Step Selection and Stepwise Advantages
Mar 13, 2026Reinforcement learning (RL) has been effective for post-training autoregressive (AR) language models, but extending these methods to diffusion language models (DLMs) is challenging due to intractable sequence-level likelihoods. Existing approaches therefore rely on surrogate likelihoods or heuristic approximations, which can introduce bias and obscure the sequential structure of denoising. We formulate diffusion-based sequence generation as a finite-horizon Markov decision process over the denoising trajectory and derive an exact, unbiased policy gradient that decomposes over denoising steps and is expressed in terms of intermediate advantages, without requiring explicit evaluation of the sequence likelihood. To obtain a practical and compute-efficient estimator, we (i) select denoising steps for policy updates via an entropy-guided approximation bound, and (ii) estimate intermediate advantages using a one-step denoising reward naturally provided by the diffusion model, avoiding costly multi-step rollouts. Experiments on coding and logical reasoning benchmarks demonstrate state-of-the-art results, with strong competitive performance on mathematical reasoning, outperforming existing RL post-training approaches for DLMs. Code is available at https://github.com/vishnutez/egspo-dllm-rl.
Zak-OTFS Based Coded Random Access for Uplink mMTC
Jul 29, 2025This paper proposes a grant-free coded random access (CRA) scheme for uplink massive machine-type communications (mMTC), based on Zak-orthogonal time frequency space (Zak-OTFS) modulation in the delay-Doppler domain. The scheme is tailored for doubly selective wireless channels, where conventional orthogonal frequency-division multiplexing (OFDM)-based CRA suffers from unreliable inter-slot channel prediction due to time-frequency variability. By exploiting the predictable nature of Zak-OTFS, the proposed approach enables accurate channel estimation across slots, facilitating reliable successive interference cancellation across user packet replicas. A fair comparison with an OFDM-based CRA baseline shows that the proposed scheme achieves significantly lower packet loss rates under high mobility and user density. Extensive simulations over the standardized Veh-A channel confirm the robustness and scalability of Zak-OTFS-based CRA, supporting its applicability to future mMTC deployments.
In-Context Learning for Gradient-Free Receiver Adaptation: Principles, Applications, and Theory
Jun 18, 2025In recent years, deep learning has facilitated the creation of wireless receivers capable of functioning effectively in conditions that challenge traditional model-based designs. Leveraging programmable hardware architectures, deep learning-based receivers offer the potential to dynamically adapt to varying channel environments. However, current adaptation strategies, including joint training, hypernetwork-based methods, and meta-learning, either demonstrate limited flexibility or necessitate explicit optimization through gradient descent. This paper presents gradient-free adaptation techniques rooted in the emerging paradigm of in-context learning (ICL). We review architectural frameworks for ICL based on Transformer models and structured state-space models (SSMs), alongside theoretical insights into how sequence models effectively learn adaptation from contextual information. Further, we explore the application of ICL to cell-free massive MIMO networks, providing both theoretical analyses and empirical evidence. Our findings indicate that ICL represents a principled and efficient approach to real-time receiver adaptation using pilot signals and auxiliary contextual information-without requiring online retraining.
Delay-Doppler Signal Processing with Zadoff-Chu Sequences
Dec 05, 2024

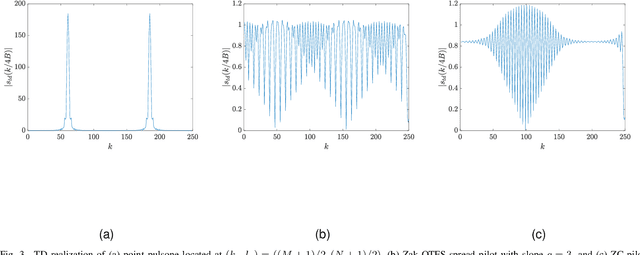

Much of the engineering behind current wireless systems has focused on designing an efficient and high-throughput downlink to support human-centric communication such as video streaming and internet browsing. This paper looks ahead to design of the uplink, anticipating the emergence of machine-type communication (MTC) and the confluence of sensing, communication, and distributed learning. We demonstrate that grant-free multiple access is possible even in the presence of highly time-varying channels. Our approach provides a pathway to standards adoption, since it is built on enhancing the 2-step random access procedure which is already part of the 5GNR standard. This 2-step procedure uses Zadoff-Chu (ZC) sequences as preambles that point to radio resources which are then used to upload data. We also use ZC sequences as preambles / pilots, but we process signals in the Delay-Doppler (DD) domain rather than the time-domain. We demonstrate that it is possible to detect multiple preambles in the presence of mobility and delay spread using a receiver with no knowledge of the channel other than the worst case delay and Doppler spreads. Our approach depends on the mathematical properties of ZC sequences in the DD domain. We derive a closed form expression for ZC pilots in the DD domain, we characterize the possible self-ambiguity functions, and we determine the magnitude of the possible cross-ambiguity functions. These mathematical properties enable detection of multiple pilots through solution of a compressed sensing problem. The columns of the compressed sensing matrix are the translates of individual ZC pilots in delay and Doppler. We show that columns in the design matrix satisfy a coherence property that makes it possible to detect multiple preambles in a single Zak-OTFS subframe using One-Step Thresholding (OST), which is an algorithm with low complexity.
OD-Stega: LLM-Based Near-Imperceptible Steganography via Optimized Distributions
Oct 06, 2024We consider coverless steganography where a Large Language Model (LLM) drives an arithmetic coding decoder to generate stego-texts. An efficient method should embed secret message bits in as few language tokens as possible, while still keeping the stego-text natural and fluent. We show that on the individual token level, this problem is mathematically equivalent to maximizing the entropy of a replacement probability distribution of the next token generation, subject to a constraint on the KL divergence between the chosen probability distribution and the original distribution given by the LLM. A closed-form solution is provided for the optimization problem, which can be computed efficiently. Several important practical issues are also tackled: 1) An often-overlooked tokenization mismatch issue is resolved with a simple prompt selection approach, 2) The combination of the optimized distribution and the vocabulary truncation technique is considered, and 3) The combination of the optimized distribution with other sequence-level selection heuristics to further enhance the efficiency and reliability is studied.
LIGHTCODE: Light Analytical and Neural Codes for Channels with Feedback
Mar 16, 2024The design of reliable and efficient codes for channels with feedback remains a longstanding challenge in communication theory. While significant improvements have been achieved by leveraging deep learning techniques, neural codes often suffer from high computational costs, a lack of interpretability, and limited practicality in resource-constrained settings. We focus on designing low-complexity coding schemes that are interpretable and more suitable for communication systems. We advance both analytical and neural codes. First, we demonstrate that POWERBLAST, an analytical coding scheme inspired by Schalkwijk-Kailath (SK) and Gallager-Nakiboglu (GN) schemes, achieves notable reliability improvements over both SK and GN schemes, outperforming neural codes in high signal-to-noise ratio (SNR) regions. Next, to enhance reliability in low-SNR regions, we propose LIGHTCODE, a lightweight neural code that achieves state-of-the-art reliability while using a fraction of memory and compute compared to existing deep-learning-based codes. Finally, we systematically analyze the learned codes, establishing connections between LIGHTCODE and POWERBLAST, identifying components crucial for performance, and providing interpretation aided by linear regression analysis.
Transformers are Efficient In-Context Estimators for Wireless Communication
Nov 01, 2023



Pre-trained transformers can perform in-context learning, where they adapt to a new task using only a small number of prompts without any explicit model optimization. Inspired by this attribute, we propose a novel approach, called in-context estimation, for the canonical communication problem of estimating transmitted symbols from received symbols. A communication channel is essentially a noisy function that maps transmitted symbols to received symbols, and this function can be represented by an unknown parameter whose statistics depend on an (also unknown) latent context. Conventional approaches ignore this hierarchical structure and simply attempt to use known transmissions, called pilots, to perform a least-squares estimate of the channel parameter, which is then used to estimate successive, unknown transmitted symbols. We make the basic connection that transformers show excellent contextual sequence completion with a few prompts, and so they should be able to implicitly determine the latent context from pilot symbols to perform end-to-end in-context estimation of transmitted symbols. Furthermore, the transformer should use information efficiently, i.e., it should utilize any pilots received to attain the best possible symbol estimates. Through extensive simulations, we show that in-context estimation not only significantly outperforms standard approaches, but also achieves the same performance as an estimator with perfect knowledge of the latent context within a few context examples. Thus, we make a strong case that transformers are efficient in-context estimators in the communication setting.
LLMZip: Lossless Text Compression using Large Language Models
Jun 26, 2023



We provide new estimates of an asymptotic upper bound on the entropy of English using the large language model LLaMA-7B as a predictor for the next token given a window of past tokens. This estimate is significantly smaller than currently available estimates in \cite{cover1978convergent}, \cite{lutati2023focus}. A natural byproduct is an algorithm for lossless compression of English text which combines the prediction from the large language model with a lossless compression scheme. Preliminary results from limited experiments suggest that our scheme outperforms state-of-the-art text compression schemes such as BSC, ZPAQ, and paq8h.
Bayesian Graph Contrastive Learning
Jan 22, 2022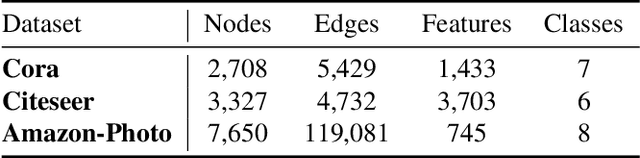
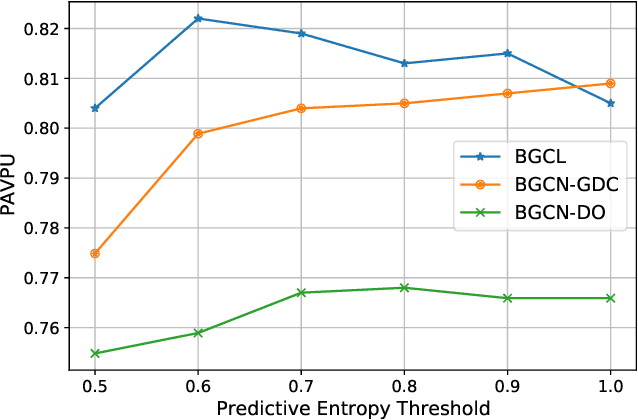
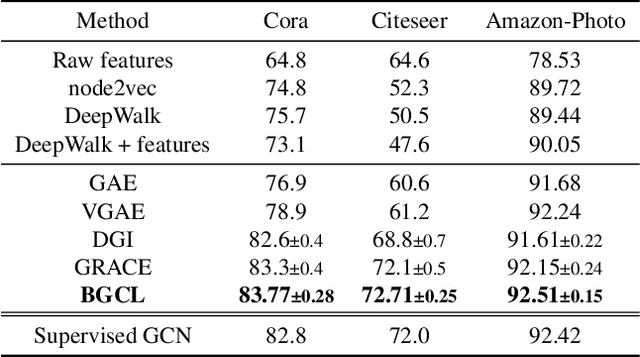
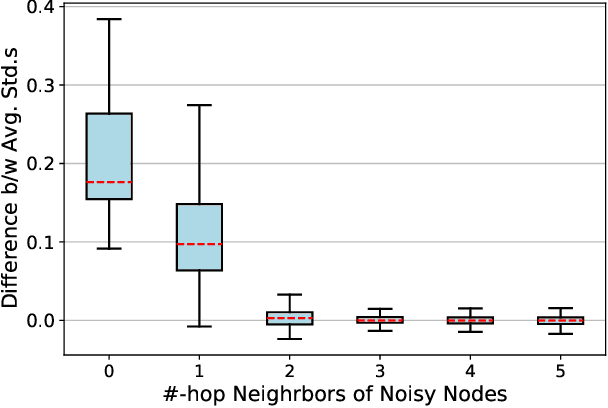
Contrastive learning has become a key component of self-supervised learning approaches for graph-structured data. However, despite their success, existing graph contrastive learning methods are incapable of uncertainty quantification for node representations or their downstream tasks, limiting their application in high-stakes domains. In this paper, we propose a novel Bayesian perspective of graph contrastive learning methods showing random augmentations leads to stochastic encoders. As a result, our proposed method represents each node by a distribution in the latent space in contrast to existing techniques which embed each node to a deterministic vector. By learning distributional representations, we provide uncertainty estimates in downstream graph analytics tasks and increase the expressive power of the predictive model. In addition, we propose a Bayesian framework to infer the probability of perturbations in each view of the contrastive model, eliminating the need for a computationally expensive search for hyperparameter tuning. We empirically show a considerable improvement in performance compared to existing state-of-the-art methods on several benchmark datasets.