 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCCDA: Adaptive Model Updates in the Presence of Concept Drift under a Constrained Resource Budget
May 30, 2025



Machine learning (ML) algorithms deployed in real-world environments are often faced with the challenge of adapting models to concept drift, where the task data distributions are shifting over time. The problem becomes even more difficult when model performance must be maintained under adherence to strict resource constraints. Existing solutions often depend on drift-detection methods that produce high computational overhead for resource-constrained environments, and fail to provide strict guarantees on resource usage or theoretical performance assurances. To address these shortcomings, we propose RCCDA: a dynamic model update policy that optimizes ML training dynamics while ensuring strict compliance to predefined resource constraints, utilizing only past loss information and a tunable drift threshold. In developing our policy, we analytically characterize the evolution of model loss under concept drift with arbitrary training update decisions. Integrating these results into a Lyapunov drift-plus-penalty framework produces a lightweight policy based on a measurable accumulated loss threshold that provably limits update frequency and cost. Experimental results on three domain generalization datasets demonstrate that our policy outperforms baseline methods in inference accuracy while adhering to strict resource constraints under several schedules of concept drift, making our solution uniquely suited for real-time ML deployments.
Goal-Oriented Communications for Real-time Inference with Two-Way Delay
Oct 11, 2024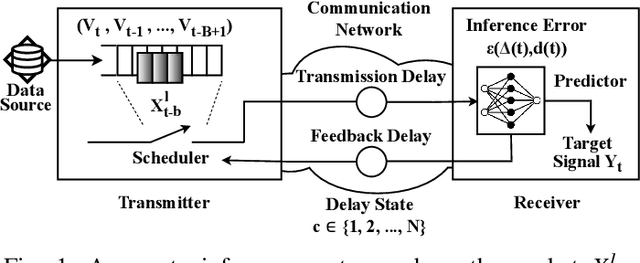
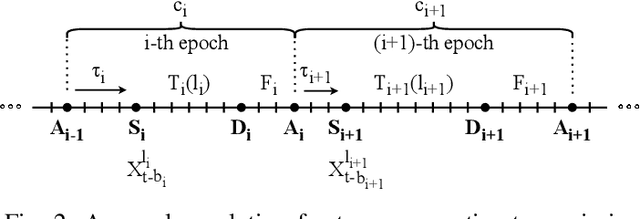
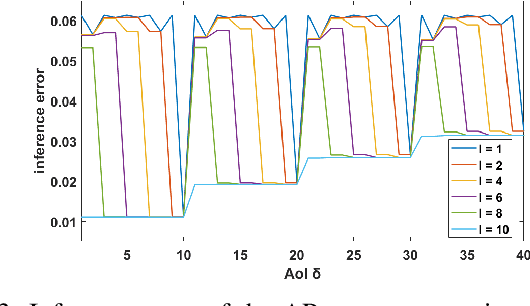
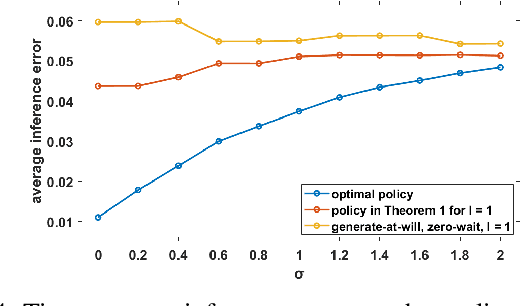
We design a goal-oriented communication strategy for remote inference, where an intelligent model (e.g., a pre-trained neural network) at the receiver side predicts the real-time value of a target signal based on data packets transmitted from a remote location. The inference error depends on both the Age of Information (AoI) and the length of the data packets. Previous formulations of this problem either assumed IID transmission delays with immediate feedback or focused only on monotonic relations where inference performance degrades as the input data ages. In contrast, we consider a possibly non-monotonic relationship between the inference error and AoI. We show how to minimize the expected time-average inference error under two-way delay, where the delay process can have memory. Simulation results highlight the significant benefits of adopting such a goal-oriented communication strategy for remote inference, especially under highly variable delay scenarios.
Timely Communications for Remote Inference
Apr 25, 2024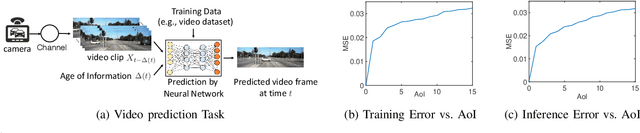
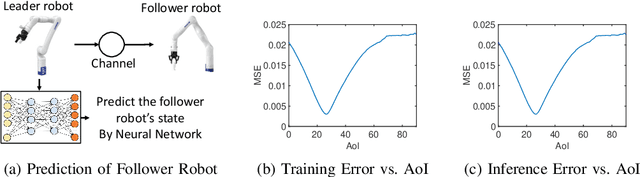

In this paper, we analyze the impact of data freshness on remote inference systems, where a pre-trained neural network infers a time-varying target (e.g., the locations of vehicles and pedestrians) based on features (e.g., video frames) observed at a sensing node (e.g., a camera). One might expect that the performance of a remote inference system degrades monotonically as the feature becomes stale. Using an information-theoretic analysis, we show that this is true if the feature and target data sequence can be closely approximated as a Markov chain, whereas it is not true if the data sequence is far from Markovian. Hence, the inference error is a function of Age of Information (AoI), where the function could be non-monotonic. To minimize the inference error in real-time, we propose a new "selection-from-buffer" model for sending the features, which is more general than the "generate-at-will" model used in earlier studies. In addition, we design low-complexity scheduling policies to improve inference performance. For single-source, single-channel systems, we provide an optimal scheduling policy. In multi-source, multi-channel systems, the scheduling problem becomes a multi-action restless multi-armed bandit problem. For this setting, we design a new scheduling policy by integrating Whittle index-based source selection and duality-based feature selection-from-buffer algorithms. This new scheduling policy is proven to be asymptotically optimal. These scheduling results hold for minimizing general AoI functions (monotonic or non-monotonic). Data-driven evaluations demonstrate the significant advantages of our proposed scheduling policies.
How Does Data Freshness Affect Real-time Supervised Learning?
Aug 15, 2022
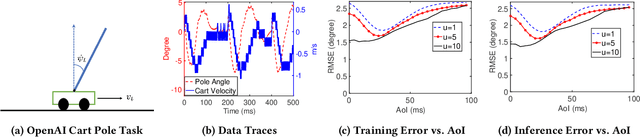


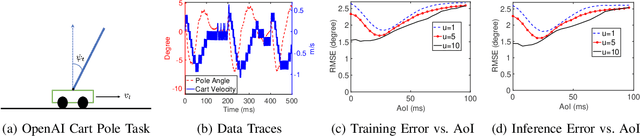
In this paper, we analyze the impact of data freshness on real-time supervised learning, where a neural network is trained to infer a time-varying target (e.g., the position of the vehicle in front) based on features (e.g., video frames) observed at a sensing node (e.g., camera or lidar). One might expect that the performance of real-time supervised learning degrades monotonically as the feature becomes stale. Using an information-theoretic analysis, we show that this is true if the feature and target data sequence can be closely approximated as a Markov chain; it is not true if the data sequence is far from Markovian. Hence, the prediction error of real-time supervised learning is a function of the Age of Information (AoI), where the function could be non-monotonic. Several experiments are conducted to illustrate the monotonic and non-monotonic behaviors of the prediction error. To minimize the inference error in real-time, we propose a new "selection-from-buffer" model for sending the features, which is more general than the "generate-at-will" model used in earlier studies. By using Gittins and Whittle indices, low-complexity scheduling strategies are developed to minimize the inference error, where a new connection between the Gittins index theory and Age of Information (AoI) minimization is discovered. These scheduling results hold (i) for minimizing general AoI functions (monotonic or non-monotonic) and (ii) for general feature transmission time distributions. Data-driven evaluations are presented to illustrate the benefits of the proposed scheduling algorithms.
A Local Geometric Interpretation of Feature Extraction in Deep Feedforward Neural Networks
Feb 10, 2022
In this paper, we present a local geometric analysis to interpret how deep feedforward neural networks extract low-dimensional features from high-dimensional data. Our study shows that, in a local geometric region, the optimal weight in one layer of the neural network and the optimal feature generated by the previous layer comprise a low-rank approximation of a matrix that is determined by the Bayes action of this layer. This result holds (i) for analyzing both the output layer and the hidden layers of the neural network, and (ii) for neuron activation functions with non-vanishing gradients. We use two supervised learning problems to illustrate our results: neural network based maximum likelihood classification (i.e., softmax regression) and neural network based minimum mean square estimation. Experimental validation of these theoretical results will be conducted in our future work.