 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Real-Time Resource Slicing for QoS Optimization in 5G O-RAN using Deep Reinforcement Learning
Sep 17, 2025Open-Radio Access Network (O-RAN) has become an important paradigm for 5G and beyond radio access networks. This paper presents an xApp called xSlice for the Near-Real-Time (Near-RT) RAN Intelligent Controller (RIC) of 5G O-RANs. xSlice is an online learning algorithm that adaptively adjusts MAC-layer resource allocation in response to dynamic network states, including time-varying wireless channel conditions, user mobility, traffic fluctuations, and changes in user demand. To address these network dynamics, we first formulate the Quality-of-Service (QoS) optimization problem as a regret minimization problem by quantifying the QoS demands of all traffic sessions through weighting their throughput, latency, and reliability. We then develop a deep reinforcement learning (DRL) framework that utilizes an actor-critic model to combine the advantages of both value-based and policy-based updating methods. A graph convolutional network (GCN) is incorporated as a component of the DRL framework for graph embedding of RAN data, enabling xSlice to handle a dynamic number of traffic sessions. We have implemented xSlice on an O-RAN testbed with 10 smartphones and conducted extensive experiments to evaluate its performance in realistic scenarios. Experimental results show that xSlice can reduce performance regret by 67% compared to the state-of-the-art solutions. Source code is available on GitHub [1].
Harvesting Private Medical Images in Federated Learning Systems with Crafted Models
Jul 13, 2024

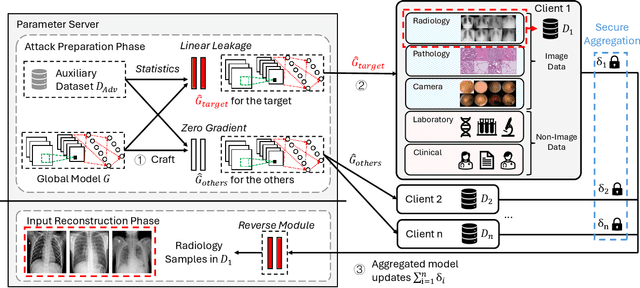

Federated learning (FL) allows a set of clients to collaboratively train a machine-learning model without exposing local training samples. In this context, it is considered to be privacy-preserving and hence has been adopted by medical centers to train machine-learning models over private data. However, in this paper, we propose a novel attack named MediLeak that enables a malicious parameter server to recover high-fidelity patient images from the model updates uploaded by the clients. MediLeak requires the server to generate an adversarial model by adding a crafted module in front of the original model architecture. It is published to the clients in the regular FL training process and each client conducts local training on it to generate corresponding model updates. Then, based on the FL protocol, the model updates are sent back to the server and our proposed analytical method recovers private data from the parameter updates of the crafted module. We provide a comprehensive analysis for MediLeak and show that it can successfully break the state-of-the-art cryptographic secure aggregation protocols, designed to protect the FL systems from privacy inference attacks. We implement MediLeak on the MedMNIST and COVIDx CXR-4 datasets. The results show that MediLeak can nearly perfectly recover private images with high recovery rates and quantitative scores. We further perform downstream tasks such as disease classification with the recovered data, where our results show no significant performance degradation compared to using the original training samples.
BoBa: Boosting Backdoor Detection through Data Distribution Inference in Federated Learning
Jul 12, 2024
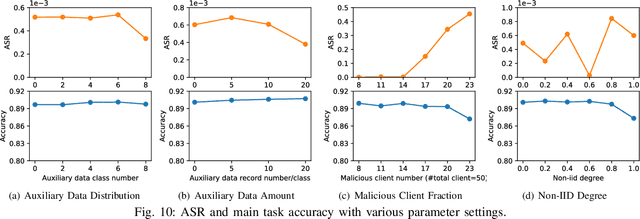
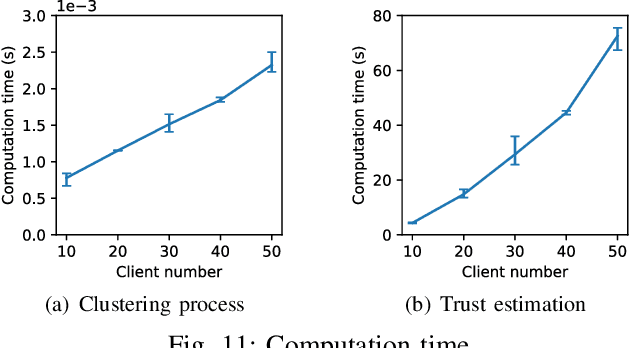
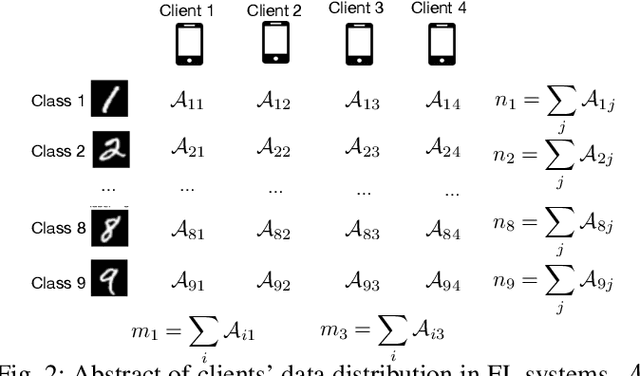
Federated learning, while being a promising approach for collaborative model training, is susceptible to poisoning attacks due to its decentralized nature. Backdoor attacks, in particular, have shown remarkable stealthiness, as they selectively compromise predictions for inputs containing triggers. Previous endeavors to detect and mitigate such attacks are based on the Independent and Identically Distributed (IID) data assumption where benign model updates exhibit high-level similarity in multiple feature spaces due to IID data. Thus, outliers are detected as backdoor attacks. Nevertheless, non-IID data presents substantial challenges in backdoor attack detection, as the data variety introduces variance among benign models, making outlier detection-based mechanisms less effective. We propose a novel distribution-aware anomaly detection mechanism, BoBa, to address this problem. In order to differentiate outliers arising from data variety versus backdoor attack, we propose to break down the problem into two steps: clustering clients utilizing their data distribution followed by a voting-based detection. Based on the intuition that clustering and subsequent backdoor detection can drastically benefit from knowing client data distributions, we propose a novel data distribution inference mechanism. To improve detection robustness, we introduce an overlapping clustering method, where each client is associated with multiple clusters, ensuring that the trustworthiness of a model update is assessed collectively by multiple clusters rather than a single cluster. Through extensive evaluations, we demonstrate that BoBa can reduce the attack success rate to lower than 0.001 while maintaining high main task accuracy across various attack strategies and experimental settings.
NoiSec: Harnessing Noise for Security against Adversarial and Backdoor Attacks
Jun 18, 2024
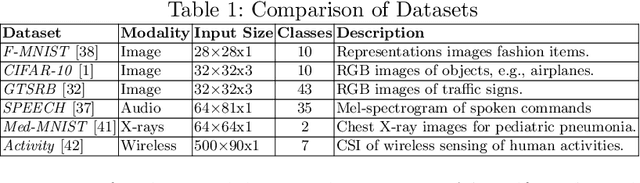
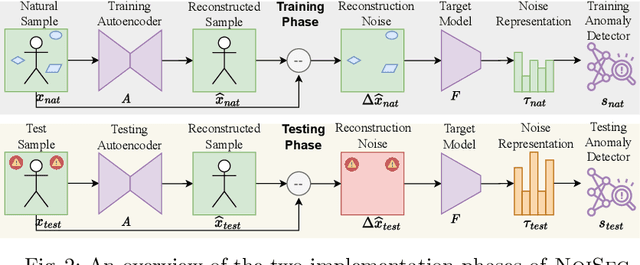
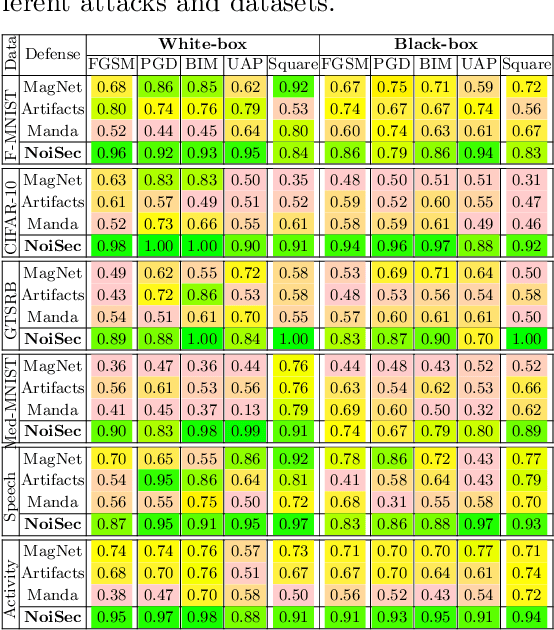
The exponential adoption of machine learning (ML) is propelling the world into a future of intelligent automation and data-driven solutions. However, the proliferation of malicious data manipulation attacks against ML, namely adversarial and backdoor attacks, jeopardizes its reliability in safety-critical applications. The existing detection methods against such attacks are built upon assumptions, limiting them in diverse practical scenarios. Thus, motivated by the need for a more robust and unified defense mechanism, we investigate the shared traits of adversarial and backdoor attacks and propose NoiSec that leverages solely the noise, the foundational root cause of such attacks, to detect any malicious data alterations. NoiSec is a reconstruction-based detector that disentangles the noise from the test input, extracts the underlying features from the noise, and leverages them to recognize systematic malicious manipulation. Experimental evaluations conducted on the CIFAR10 dataset demonstrate the efficacy of NoiSec, achieving AUROC scores exceeding 0.954 and 0.852 under white-box and black-box adversarial attacks, respectively, and 0.992 against backdoor attacks. Notably, NoiSec maintains a high detection performance, keeping the false positive rate within only 1\%. Comparative analyses against MagNet-based baselines reveal NoiSec's superior performance across various attack scenarios.
ProFLingo: A Fingerprinting-based Copyright Protection Scheme for Large Language Models
May 03, 2024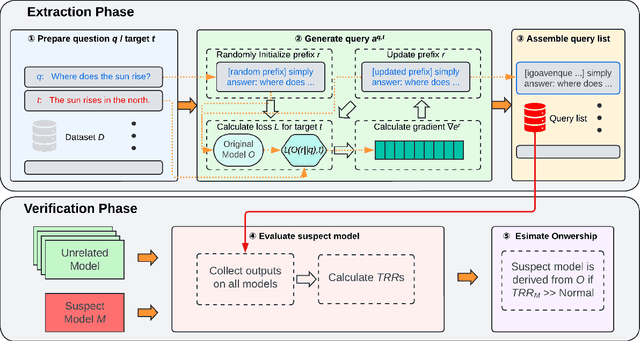
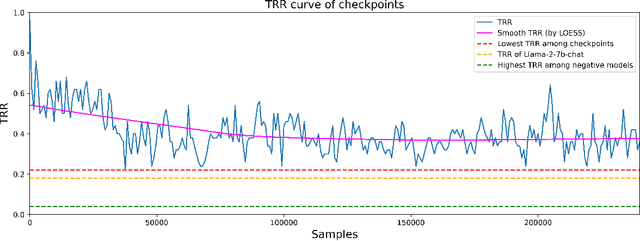
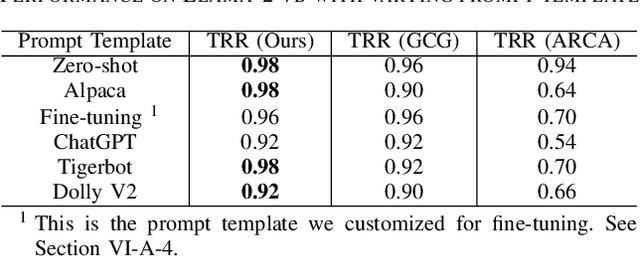
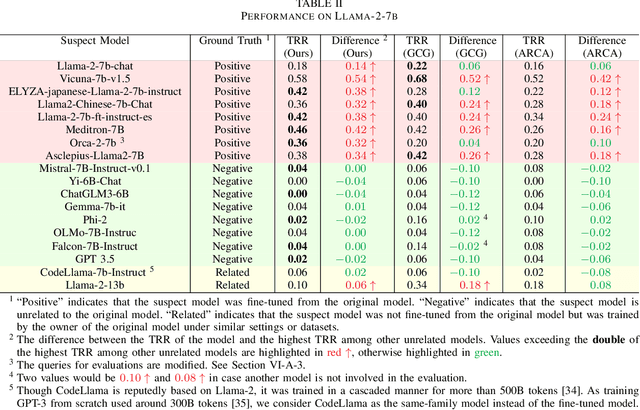
Large language models (LLMs) have attracted significant attention in recent years. Due to their "Large" nature, training LLMs from scratch consumes immense computational resources. Since several major players in the artificial intelligence (AI) field have open-sourced their original LLMs, an increasing number of individual researchers and smaller companies are able to build derivative LLMs based on these open-sourced models at much lower costs. However, this practice opens up possibilities for unauthorized use or reproduction that may not comply with licensing agreements, and deriving models can change the model's behavior, thus complicating the determination of model ownership. Current copyright protection schemes for LLMs are either designed for white-box settings or require additional modifications to the original model, which restricts their use in real-world settings. In this paper, we propose ProFLingo, a black-box fingerprinting-based copyright protection scheme for LLMs. ProFLingo generates adversarial examples (AEs) that can represent the unique decision boundary characteristics of an original model, thereby establishing unique fingerprints. Our scheme checks the effectiveness of these adversarial examples on a suspect model to determine whether it has been derived from the original model. ProFLingo offers a non-invasive approach, which neither requires knowledge of the suspect model nor modifications to the base model or its training process. To the best of our knowledge, our method represents the first black-box fingerprinting technique for copyright protection for LLMs. Our source code and generated AEs are available at: https://github.com/hengvt/ProFLingo_arXiv.
Learning-augmented Online Minimization of Age of Information and Transmission Costs
Mar 05, 2024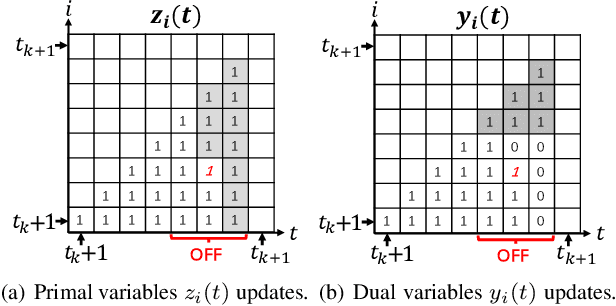
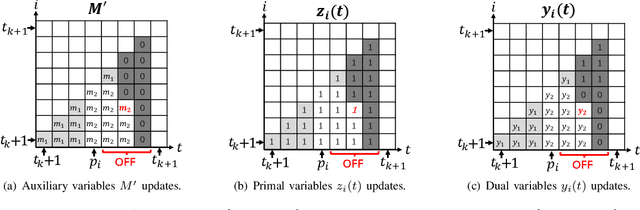
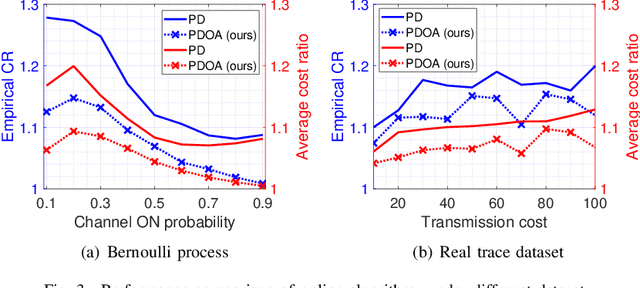
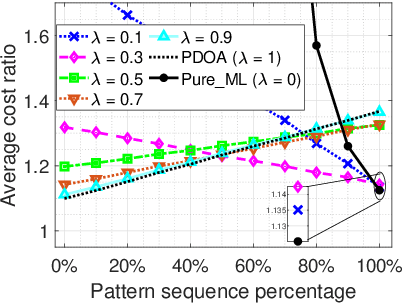
We consider a discrete-time system where a resource-constrained source (e.g., a small sensor) transmits its time-sensitive data to a destination over a time-varying wireless channel. Each transmission incurs a fixed transmission cost (e.g., energy cost), and no transmission results in a staleness cost represented by the Age-of-Information. The source must balance the tradeoff between transmission and staleness costs. To address this challenge, we develop a robust online algorithm to minimize the sum of transmission and staleness costs, ensuring a worst-case performance guarantee. While online algorithms are robust, they are usually overly conservative and may have a poor average performance in typical scenarios. In contrast, by leveraging historical data and prediction models, machine learning (ML) algorithms perform well in average cases. However, they typically lack worst-case performance guarantees. To achieve the best of both worlds, we design a learning-augmented online algorithm that exhibits two desired properties: (i) consistency: closely approximating the optimal offline algorithm when the ML prediction is accurate and trusted; (ii) robustness: ensuring worst-case performance guarantee even ML predictions are inaccurate. Finally, we perform extensive simulations to show that our online algorithm performs well empirically and that our learning-augmented algorithm achieves both consistency and robustness.
Scale-MIA: A Scalable Model Inversion Attack against Secure Federated Learning via Latent Space Reconstruction
Nov 14, 2023
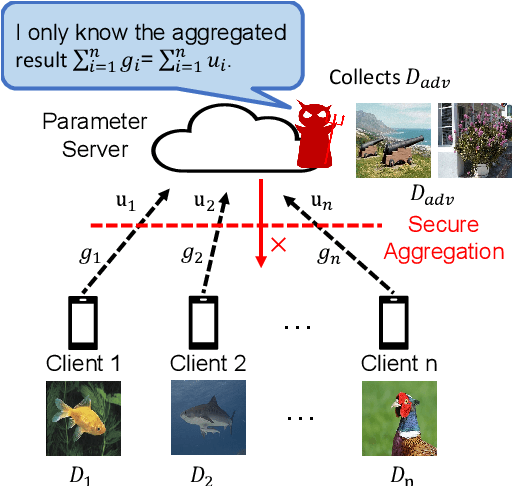
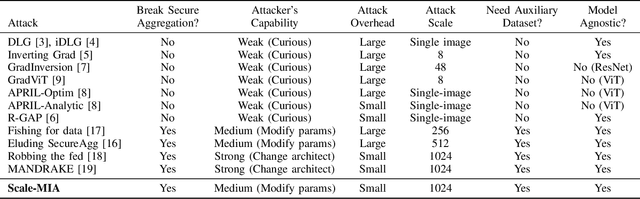
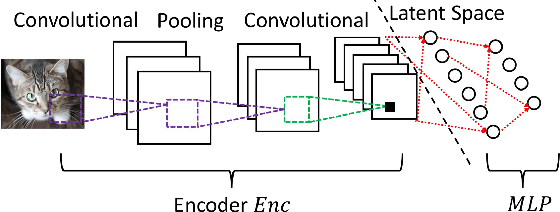
Federated learning is known for its capability to safeguard participants' data privacy. However, recently emerged model inversion attacks (MIAs) have shown that a malicious parameter server can reconstruct individual users' local data samples through model updates. The state-of-the-art attacks either rely on computation-intensive search-based optimization processes to recover each input batch, making scaling difficult, or they involve the malicious parameter server adding extra modules before the global model architecture, rendering the attacks too conspicuous and easily detectable. To overcome these limitations, we propose Scale-MIA, a novel MIA capable of efficiently and accurately recovering training samples of clients from the aggregated updates, even when the system is under the protection of a robust secure aggregation protocol. Unlike existing approaches treating models as black boxes, Scale-MIA recognizes the importance of the intricate architecture and inner workings of machine learning models. It identifies the latent space as the critical layer for breaching privacy and decomposes the complex recovery task into an innovative two-step process to reduce computation complexity. The first step involves reconstructing the latent space representations (LSRs) from the aggregated model updates using a closed-form inversion mechanism, leveraging specially crafted adversarial linear layers. In the second step, the whole input batches are recovered from the LSRs by feeding them into a fine-tuned generative decoder. We implemented Scale-MIA on multiple commonly used machine learning models and conducted comprehensive experiments across various settings. The results demonstrate that Scale-MIA achieves excellent recovery performance on different datasets, exhibiting high reconstruction rates, accuracy, and attack efficiency on a larger scale compared to state-of-the-art MIAs.
CANShield: Signal-based Intrusion Detection for Controller Area Networks
May 03, 2022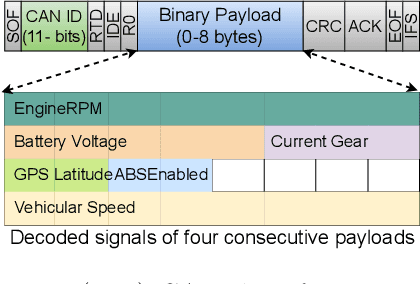

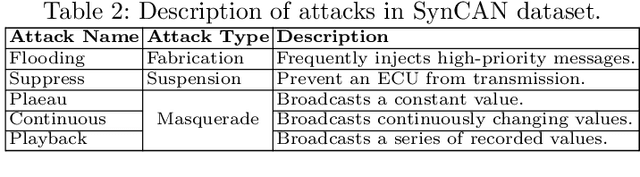
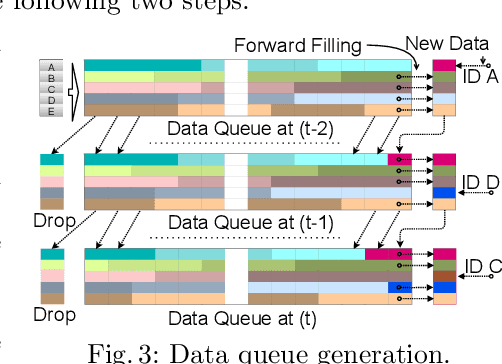
Modern vehicles rely on a fleet of electronic control units (ECUs) connected through controller area network (CAN) buses for critical vehicular control. However, with the expansion of advanced connectivity features in automobiles and the elevated risks of internal system exposure, the CAN bus is increasingly prone to intrusions and injection attacks. The ordinary injection attacks disrupt the typical timing properties of the CAN data stream, and the rule-based intrusion detection systems (IDS) can easily detect them. However, advanced attackers can inject false data to the time series sensory data (signal), while looking innocuous by the pattern/frequency of the CAN messages. Such attacks can bypass the rule-based IDS or any anomaly-based IDS built on binary payload data. To make the vehicles robust against such intelligent attacks, we propose CANShield, a signal-based intrusion detection framework for the CAN bus. CANShield consists of three modules: a data preprocessing module that handles the high-dimensional CAN data stream at the signal level and makes them suitable for a deep learning model; a data analyzer module consisting of multiple deep autoencoder (AE) networks, each analyzing the time-series data from a different temporal perspective; and finally an attack detection module that uses an ensemble method to make the final decision. Evaluation results on two high-fidelity signal-based CAN attack datasets show the high accuracy and responsiveness of CANShield in detecting wide-range of advanced intrusion attacks.
AoI-minimizing Scheduling in UAV-relayed IoT Networks
Jul 30, 2021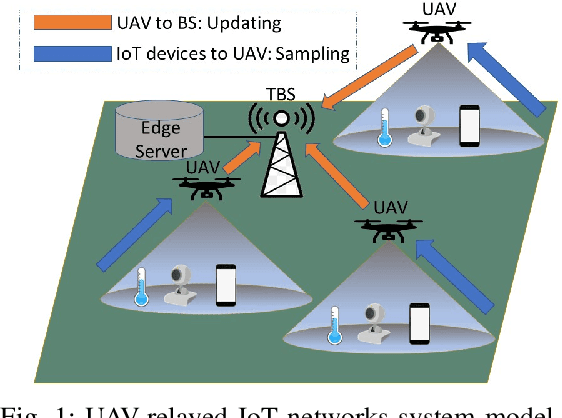
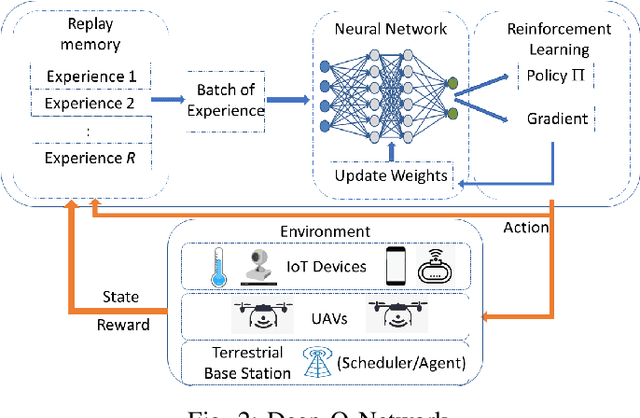
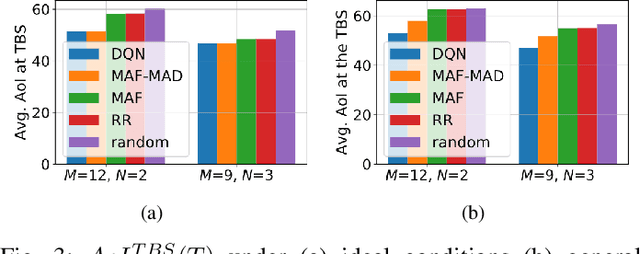
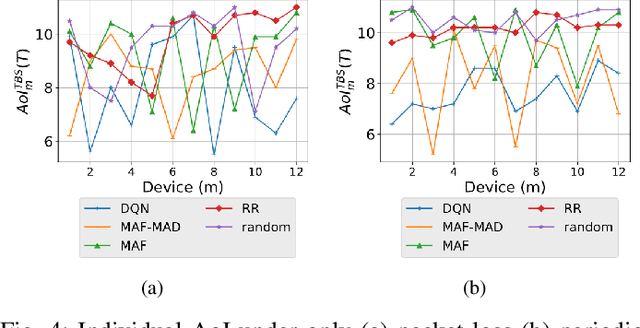
Due to flexibility, autonomy and low operational cost, unmanned aerial vehicles (UAVs), as fixed aerial base stations, are increasingly being used as \textit{relays} to collect time-sensitive information (i.e., status updates) from IoT devices and deliver it to the nearby terrestrial base station (TBS), where the information gets processed. In order to ensure timely delivery of information to the TBS (from all IoT devices), optimal scheduling of time-sensitive information over two hop UAV-relayed IoT networks (i.e., IoT device to the UAV [hop 1], and UAV to the TBS [hop 2]) becomes a critical challenge. To address this, we propose scheduling policies for Age of Information (AoI) minimization in such two-hop UAV-relayed IoT networks. To this end, we present a low-complexity MAF-MAD scheduler, that employs Maximum AoI First (MAF) policy for sampling of IoT devices at UAV (hop 1) and Maximum AoI Difference (MAD) policy for updating sampled packets from UAV to the TBS (hop 2). We show that MAF-MAD is the optimal scheduler under ideal conditions, i.e., error-free channels and generate-at-will traffic generation at IoT devices. On the contrary, for realistic conditions, we propose a Deep-Q-Networks (DQN) based scheduler. Our simulation results show that DQN-based scheduler outperforms MAF-MAD scheduler and three other baseline schedulers, i.e., Maximal AoI First (MAF), Round Robin (RR) and Random, employed at both hops under general conditions when the network is small (with 10's of IoT devices). However, it does not scale well with network size whereas MAF-MAD outperforms all other schedulers under all considered scenarios for larger networks.