 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-MIA: A Scalable Model Inversion Attack against Secure Federated Learning via Latent Space Reconstruction
Paper and Code
Nov 14, 2023
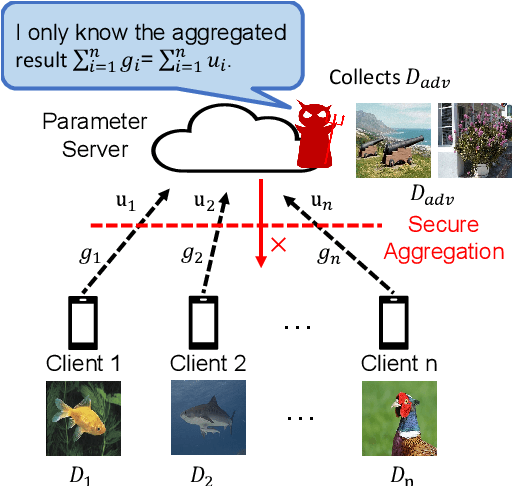
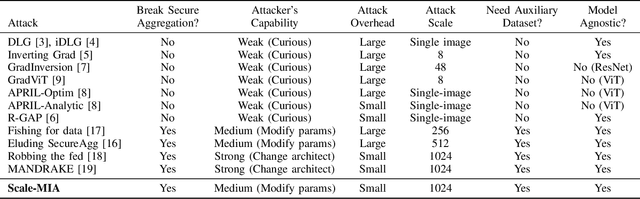
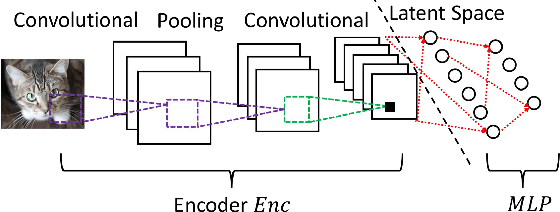
Federated learning is known for its capability to safeguard participants' data privacy. However, recently emerged model inversion attacks (MIAs) have shown that a malicious parameter server can reconstruct individual users' local data samples through model updates. The state-of-the-art attacks either rely on computation-intensive search-based optimization processes to recover each input batch, making scaling difficult, or they involve the malicious parameter server adding extra modules before the global model architecture, rendering the attacks too conspicuous and easily detectable. To overcome these limitations, we propose Scale-MIA, a novel MIA capable of efficiently and accurately recovering training samples of clients from the aggregated updates, even when the system is under the protection of a robust secure aggregation protocol. Unlike existing approaches treating models as black boxes, Scale-MIA recognizes the importance of the intricate architecture and inner workings of machine learning models. It identifies the latent space as the critical layer for breaching privacy and decomposes the complex recovery task into an innovative two-step process to reduce computation complexity. The first step involves reconstructing the latent space representations (LSRs) from the aggregated model updates using a closed-form inversion mechanism, leveraging specially crafted adversarial linear layers. In the second step, the whole input batches are recovered from the LSRs by feeding them into a fine-tuned generative decoder. We implemented Scale-MIA on multiple commonly used machine learning models and conducted comprehensive experiments across various settings. The results demonstrate that Scale-MIA achieves excellent recovery performance on different datasets, exhibiting high reconstruction rates, accuracy, and attack efficiency on a larger scale compared to state-of-the-art MIAs.