 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Jailbreak Detection of Large Vision Language Models with Representational Contrastive Scoring
Dec 12, 2025



Large Vision-Language Models (LVLMs) are vulnerable to a growing array of multimodal jailbreak attacks, necessitating defenses that are both generalizable to novel threats and efficient for practical deployment. Many current strategies fall short, either targeting specific attack patterns, which limits generalization, or imposing high computational overhead. While lightweight anomaly-detection methods offer a promising direction, we find that their common one-class design tends to confuse novel benign inputs with malicious ones, leading to unreliable over-rejection. To address this, we propose Representational Contrastive Scoring (RCS), a framework built on a key insight: the most potent safety signals reside within the LVLM's own internal representations. Our approach inspects the internal geometry of these representations, learning a lightweight projection to maximally separate benign and malicious inputs in safety-critical layers. This enables a simple yet powerful contrastive score that differentiates true malicious intent from mere novelty. Our instantiations, MCD (Mahalanobis Contrastive Detection) and KCD (K-nearest Contrastive Detection), achieve state-of-the-art performance on a challenging evaluation protocol designed to test generalization to unseen attack types. This work demonstrates that effective jailbreak detection can be achieved by applying simple, interpretable statistical methods to the appropriate internal representations, offering a practical path towards safer LVLM deployment. Our code is available on Github https://github.com/sarendis56/Jailbreak_Detection_RCS.
Harvesting Private Medical Images in Federated Learning Systems with Crafted Models
Jul 13, 2024

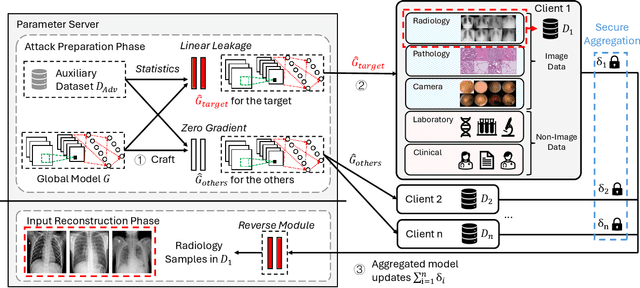

Federated learning (FL) allows a set of clients to collaboratively train a machine-learning model without exposing local training samples. In this context, it is considered to be privacy-preserving and hence has been adopted by medical centers to train machine-learning models over private data. However, in this paper, we propose a novel attack named MediLeak that enables a malicious parameter server to recover high-fidelity patient images from the model updates uploaded by the clients. MediLeak requires the server to generate an adversarial model by adding a crafted module in front of the original model architecture. It is published to the clients in the regular FL training process and each client conducts local training on it to generate corresponding model updates. Then, based on the FL protocol, the model updates are sent back to the server and our proposed analytical method recovers private data from the parameter updates of the crafted module. We provide a comprehensive analysis for MediLeak and show that it can successfully break the state-of-the-art cryptographic secure aggregation protocols, designed to protect the FL systems from privacy inference attacks. We implement MediLeak on the MedMNIST and COVIDx CXR-4 datasets. The results show that MediLeak can nearly perfectly recover private images with high recovery rates and quantitative scores. We further perform downstream tasks such as disease classification with the recovered data, where our results show no significant performance degradation compared to using the original training samples.
BoBa: Boosting Backdoor Detection through Data Distribution Inference in Federated Learning
Jul 12, 2024
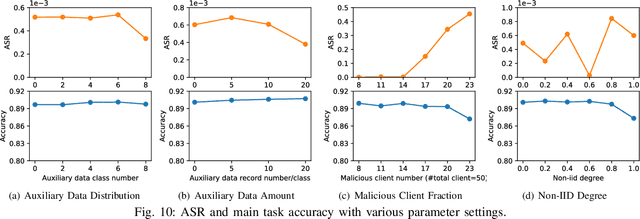
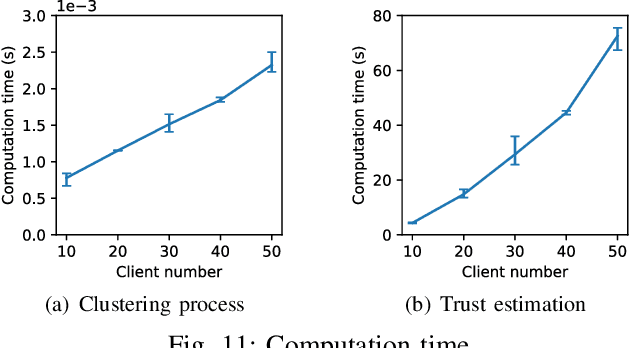
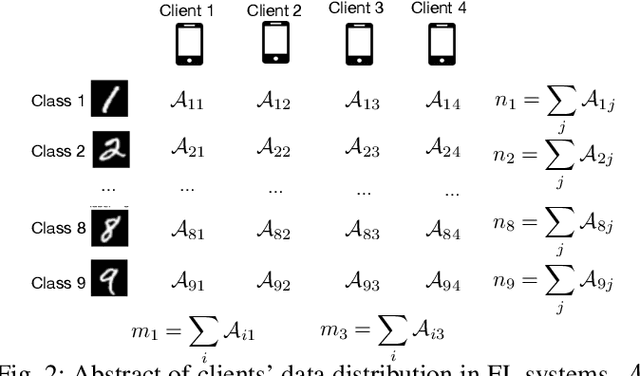
Federated learning, while being a promising approach for collaborative model training, is susceptible to poisoning attacks due to its decentralized nature. Backdoor attacks, in particular, have shown remarkable stealthiness, as they selectively compromise predictions for inputs containing triggers. Previous endeavors to detect and mitigate such attacks are based on the Independent and Identically Distributed (IID) data assumption where benign model updates exhibit high-level similarity in multiple feature spaces due to IID data. Thus, outliers are detected as backdoor attacks. Nevertheless, non-IID data presents substantial challenges in backdoor attack detection, as the data variety introduces variance among benign models, making outlier detection-based mechanisms less effective. We propose a novel distribution-aware anomaly detection mechanism, BoBa, to address this problem. In order to differentiate outliers arising from data variety versus backdoor attack, we propose to break down the problem into two steps: clustering clients utilizing their data distribution followed by a voting-based detection. Based on the intuition that clustering and subsequent backdoor detection can drastically benefit from knowing client data distributions, we propose a novel data distribution inference mechanism. To improve detection robustness, we introduce an overlapping clustering method, where each client is associated with multiple clusters, ensuring that the trustworthiness of a model update is assessed collectively by multiple clusters rather than a single cluster. Through extensive evaluations, we demonstrate that BoBa can reduce the attack success rate to lower than 0.001 while maintaining high main task accuracy across various attack strategies and experimental settings.
ProFLingo: A Fingerprinting-based Copyright Protection Scheme for Large Language Models
May 03, 2024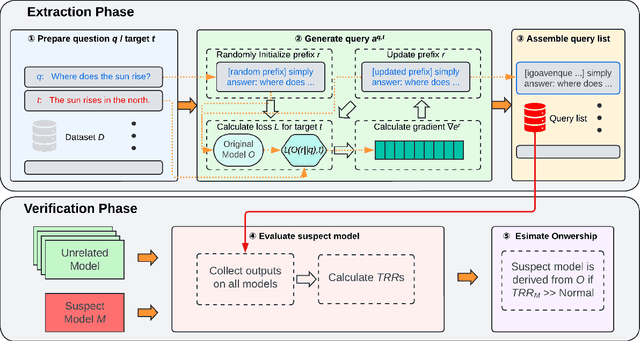
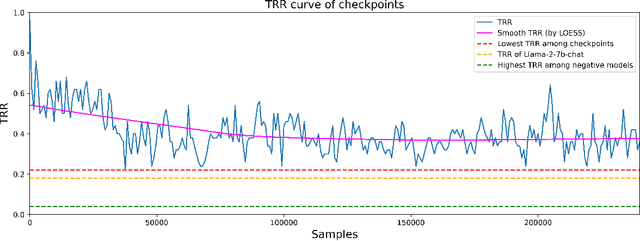
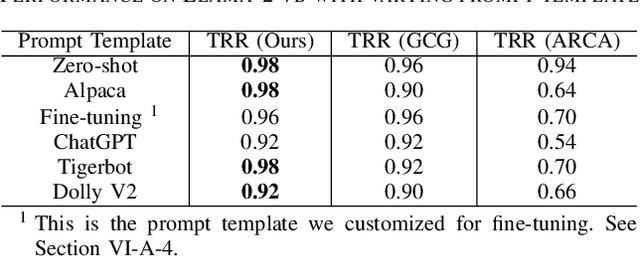
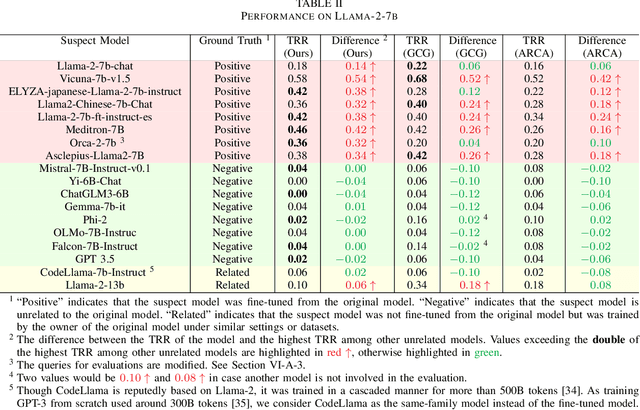
Large language models (LLMs) have attracted significant attention in recent years. Due to their "Large" nature, training LLMs from scratch consumes immense computational resources. Since several major players in the artificial intelligence (AI) field have open-sourced their original LLMs, an increasing number of individual researchers and smaller companies are able to build derivative LLMs based on these open-sourced models at much lower costs. However, this practice opens up possibilities for unauthorized use or reproduction that may not comply with licensing agreements, and deriving models can change the model's behavior, thus complicating the determination of model ownership. Current copyright protection schemes for LLMs are either designed for white-box settings or require additional modifications to the original model, which restricts their use in real-world settings. In this paper, we propose ProFLingo, a black-box fingerprinting-based copyright protection scheme for LLMs. ProFLingo generates adversarial examples (AEs) that can represent the unique decision boundary characteristics of an original model, thereby establishing unique fingerprints. Our scheme checks the effectiveness of these adversarial examples on a suspect model to determine whether it has been derived from the original model. ProFLingo offers a non-invasive approach, which neither requires knowledge of the suspect model nor modifications to the base model or its training process. To the best of our knowledge, our method represents the first black-box fingerprinting technique for copyright protection for LLMs. Our source code and generated AEs are available at: https://github.com/hengvt/ProFLingo_arXiv.
Scale-MIA: A Scalable Model Inversion Attack against Secure Federated Learning via Latent Space Reconstruction
Nov 14, 2023
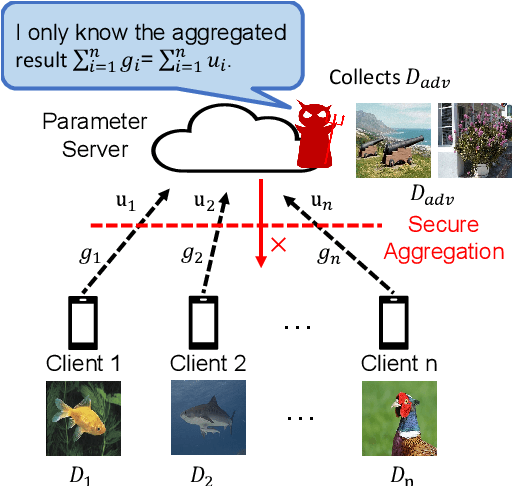
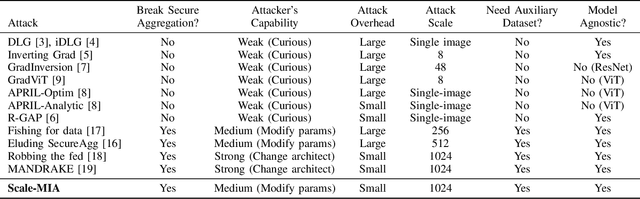
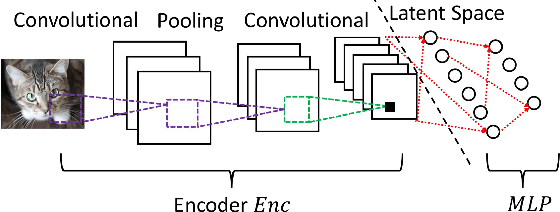
Federated learning is known for its capability to safeguard participants' data privacy. However, recently emerged model inversion attacks (MIAs) have shown that a malicious parameter server can reconstruct individual users' local data samples through model updates. The state-of-the-art attacks either rely on computation-intensive search-based optimization processes to recover each input batch, making scaling difficult, or they involve the malicious parameter server adding extra modules before the global model architecture, rendering the attacks too conspicuous and easily detectable. To overcome these limitations, we propose Scale-MIA, a novel MIA capable of efficiently and accurately recovering training samples of clients from the aggregated updates, even when the system is under the protection of a robust secure aggregation protocol. Unlike existing approaches treating models as black boxes, Scale-MIA recognizes the importance of the intricate architecture and inner workings of machine learning models. It identifies the latent space as the critical layer for breaching privacy and decomposes the complex recovery task into an innovative two-step process to reduce computation complexity. The first step involves reconstructing the latent space representations (LSRs) from the aggregated model updates using a closed-form inversion mechanism, leveraging specially crafted adversarial linear layers. In the second step, the whole input batches are recovered from the LSRs by feeding them into a fine-tuned generative decoder. We implemented Scale-MIA on multiple commonly used machine learning models and conducted comprehensive experiments across various settings. The results demonstrate that Scale-MIA achieves excellent recovery performance on different datasets, exhibiting high reconstruction rates, accuracy, and attack efficiency on a larger scale compared to state-of-the-art MIAs.