 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReLoop: Structured Modeling and Behavioral Verification for Reliable LLM-Based Optimization
Feb 17, 2026Large language models (LLMs) can translate natural language into optimization code, but silent failures pose a critical risk: code that executes and returns solver-feasible solutions may encode semantically incorrect formulations, creating a feasibility-correctness gap of up to 90 percentage points on compositional problems. We introduce ReLoop, addressing silent failures from two complementary directions. Structured generation decomposes code production into a four-stage reasoning chain (understand, formalize, synthesize, verify) that mirrors expert modeling practice, with explicit variable-type reasoning and self-verification to prevent formulation errors at their source. Behavioral verification detects errors that survive generation by testing whether the formulation responds correctly to solver-based parameter perturbation, without requiring ground truth -- an external semantic signal that bypasses the self-consistency problem inherent in LLM-based code review. The two mechanisms are complementary: structured generation dominates on complex compositional problems, while behavioral verification becomes the largest single contributor on problems with localized formulation defects. Together with execution recovery via IIS-enhanced diagnostics, ReLoop raises correctness from 22.6% to 31.1% and execution from 72.1% to 100.0% on the strongest model, with consistent gains across five models spanning three paradigms (foundation, SFT, RL) and three benchmarks. We additionally release RetailOpt-190, 190 compositional retail optimization scenarios targeting the multi-constraint interactions where LLMs most frequently fail.
ProFLingo: A Fingerprinting-based Copyright Protection Scheme for Large Language Models
May 03, 2024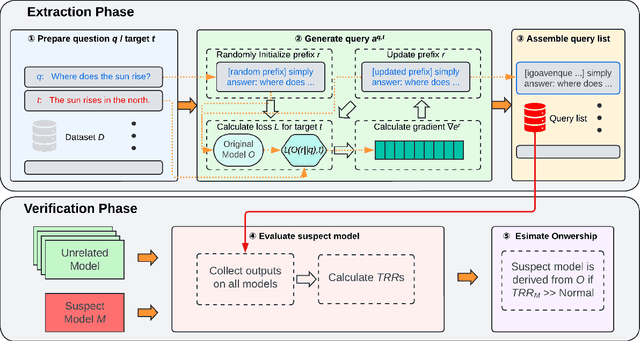
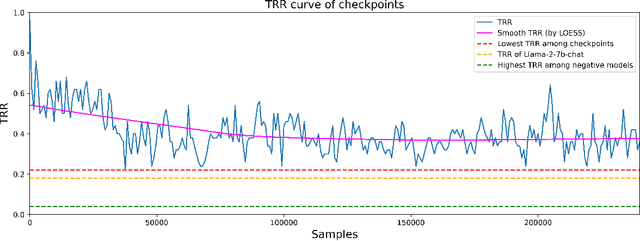
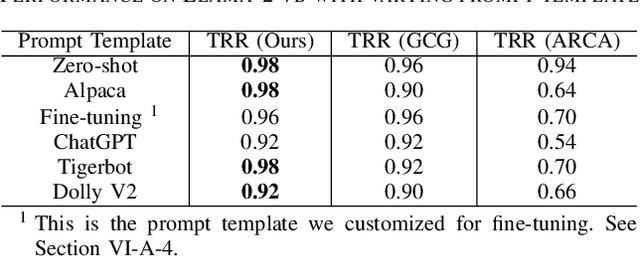
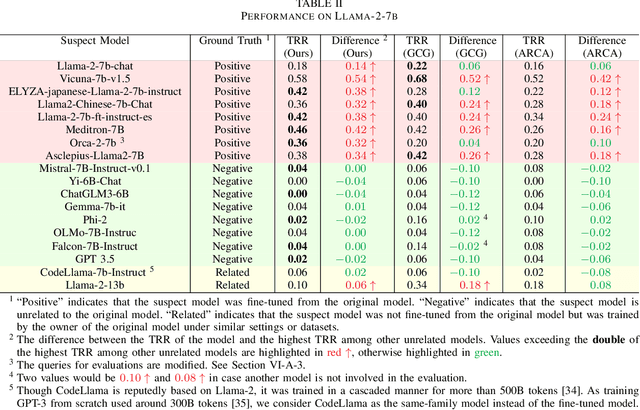
Large language models (LLMs) have attracted significant attention in recent years. Due to their "Large" nature, training LLMs from scratch consumes immense computational resources. Since several major players in the artificial intelligence (AI) field have open-sourced their original LLMs, an increasing number of individual researchers and smaller companies are able to build derivative LLMs based on these open-sourced models at much lower costs. However, this practice opens up possibilities for unauthorized use or reproduction that may not comply with licensing agreements, and deriving models can change the model's behavior, thus complicating the determination of model ownership. Current copyright protection schemes for LLMs are either designed for white-box settings or require additional modifications to the original model, which restricts their use in real-world settings. In this paper, we propose ProFLingo, a black-box fingerprinting-based copyright protection scheme for LLMs. ProFLingo generates adversarial examples (AEs) that can represent the unique decision boundary characteristics of an original model, thereby establishing unique fingerprints. Our scheme checks the effectiveness of these adversarial examples on a suspect model to determine whether it has been derived from the original model. ProFLingo offers a non-invasive approach, which neither requires knowledge of the suspect model nor modifications to the base model or its training process. To the best of our knowledge, our method represents the first black-box fingerprinting technique for copyright protection for LLMs. Our source code and generated AEs are available at: https://github.com/hengvt/ProFLingo_arXiv.
Scale-MIA: A Scalable Model Inversion Attack against Secure Federated Learning via Latent Space Reconstruction
Nov 14, 2023
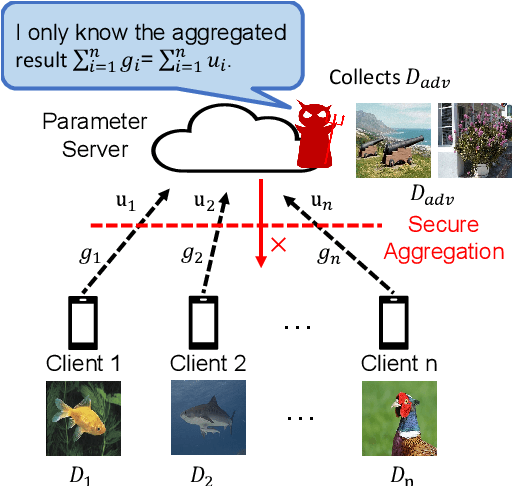
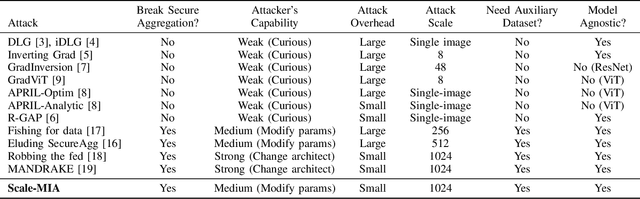
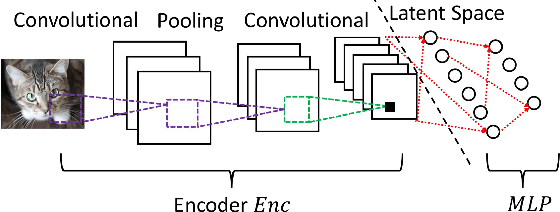
Federated learning is known for its capability to safeguard participants' data privacy. However, recently emerged model inversion attacks (MIAs) have shown that a malicious parameter server can reconstruct individual users' local data samples through model updates. The state-of-the-art attacks either rely on computation-intensive search-based optimization processes to recover each input batch, making scaling difficult, or they involve the malicious parameter server adding extra modules before the global model architecture, rendering the attacks too conspicuous and easily detectable. To overcome these limitations, we propose Scale-MIA, a novel MIA capable of efficiently and accurately recovering training samples of clients from the aggregated updates, even when the system is under the protection of a robust secure aggregation protocol. Unlike existing approaches treating models as black boxes, Scale-MIA recognizes the importance of the intricate architecture and inner workings of machine learning models. It identifies the latent space as the critical layer for breaching privacy and decomposes the complex recovery task into an innovative two-step process to reduce computation complexity. The first step involves reconstructing the latent space representations (LSRs) from the aggregated model updates using a closed-form inversion mechanism, leveraging specially crafted adversarial linear layers. In the second step, the whole input batches are recovered from the LSRs by feeding them into a fine-tuned generative decoder. We implemented Scale-MIA on multiple commonly used machine learning models and conducted comprehensive experiments across various settings. The results demonstrate that Scale-MIA achieves excellent recovery performance on different datasets, exhibiting high reconstruction rates, accuracy, and attack efficiency on a larger scale compared to state-of-the-art MIAs.