 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Monotonicity of Information Aging
Mar 06, 2024
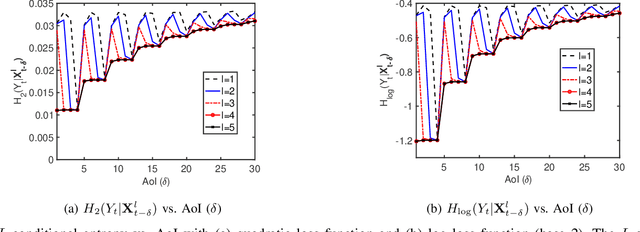
In this paper, we analyze the monotonicity of information aging in a remote estimation system, where historical observations of a Gaussian autoregressive AR(p) process are used to predict its future values. We consider two widely used loss functions in estimation: (i) logarithmic loss function for maximum likelihood estimation and (ii) quadratic loss function for MMSE estimation. The estimation error of the AR(p) process is written as a generalized conditional entropy which has closed-form expressions. By using a new information-theoretic tool called $\epsilon$-Markov chain, we can evaluate the divergence of the AR(p) process from being a Markov chain. When the divergence $\epsilon$ is large, the estimation error of the AR(p) process can be far from a non-decreasing function of the Age of Information (AoI). Conversely, for small divergence $\epsilon$, the inference error is close to a non-decreasing AoI function. Each observation is a short sequence taken from the AR(p) process. As the observation sequence length increases, the parameter $\epsilon$ progressively reduces to zero, and hence the estimation error becomes a non-decreasing AoI function. These results underscore a connection between the monotonicity of information aging and the divergence of from being a Markov chain.
The Age of Correlated Features in Supervised Learning based Forecasting
Feb 27, 2021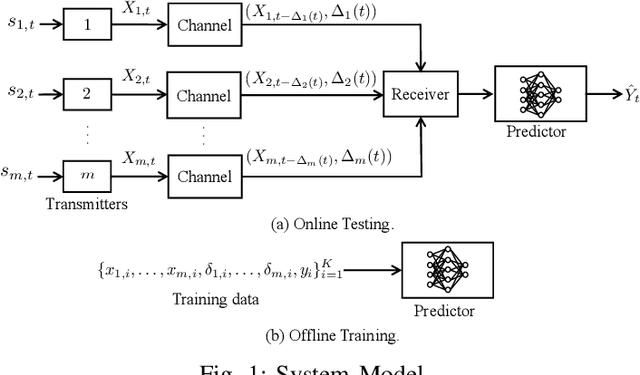
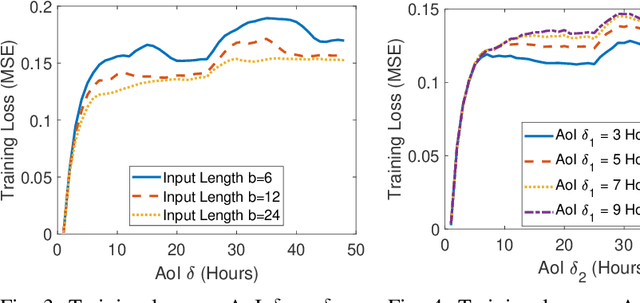
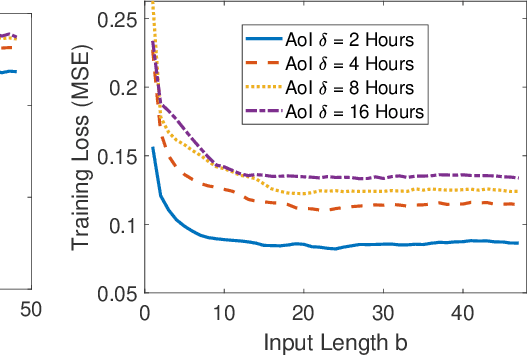
In this paper, we analyze the impact of information freshness on supervised learning based forecasting. In these applications, a neural network is trained to predict a time-varying target (e.g., solar power), based on multiple correlated features (e.g., temperature, humidity, and cloud coverage). The features are collected from different data sources and are subject to heterogeneous and time-varying ages. By using an information-theoretic approach, we prove that the minimum training loss is a function of the ages of the features, where the function is not always monotonic. However, if the empirical distribution of the training data is close to the distribution of a Markov chain, then the training loss is approximately a non-decreasing age function. Both the training loss and testing loss depict similar growth patterns as the age increases. An experiment on solar power prediction is conducted to validate our theory. Our theoretical and experimental results suggest that it is beneficial to (i) combine the training data with different age values into a large training dataset and jointly train the forecasting decisions for these age values, and (ii) feed the age value as a part of the input feature to the neural network.