 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA hierarchical residual network with compact triplet-center loss for sketch recognition
Sep 28, 2021
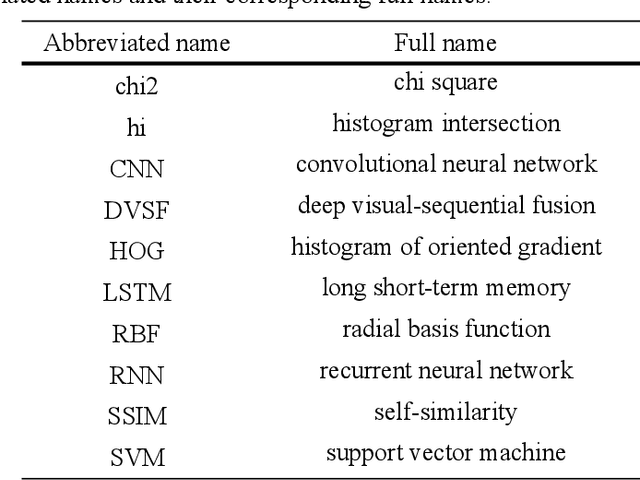
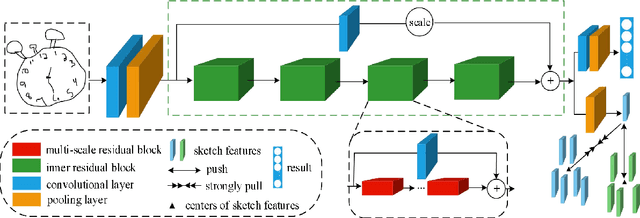
With the widespread use of touch-screen devices, it is more and more convenient for people to draw sketches on screen. This results in the demand for automatically understanding the sketches. Thus, the sketch recognition task becomes more significant than before. To accomplish this task, it is necessary to solve the critical issue of improving the distinction of the sketch features. To this end, we have made efforts in three aspects. First, a novel multi-scale residual block is designed. Compared with the conventional basic residual block, it can better perceive multi-scale information and reduce the number of parameters during training. Second, a hierarchical residual structure is built by stacking multi-scale residual blocks in a specific way. In contrast with the single-level residual structure, the learned features from this structure are more sufficient. Last but not least, the compact triplet-center loss is proposed specifically for the sketch recognition task. It can solve the problem that the triplet-center loss does not fully consider too large intra-class space and too small inter-class space in sketch field. By studying the above modules, a hierarchical residual network as a whole is proposed for sketch recognition and evaluated on Tu-Berlin benchmark thoroughly. The experimental results show that the proposed network outperforms most of baseline methods and it is excellent among non-sequential models at present.
Waiting but not Aging: Age-of-Information and Utility Optimization Under the Pull Model
Dec 17, 2019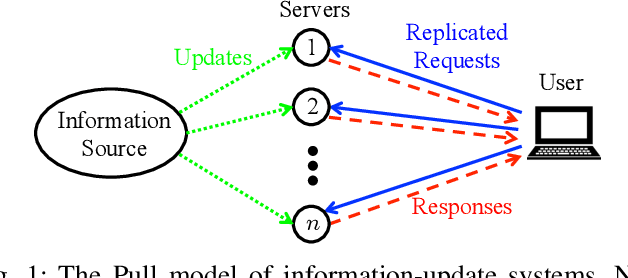
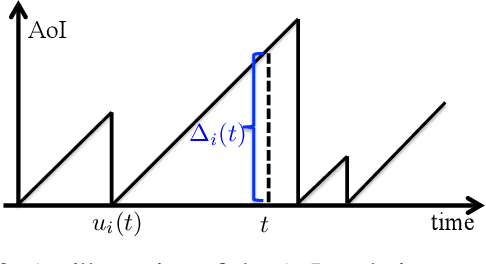

The Age-of-Information (AoI) has recently been proposed as an important metric for investigating the timeliness performance in information-update systems. In this paper, we introduce a new Pull model and study the AoI optimization problem under replication schemes. Interestingly, we find that under this new Pull model, replication schemes capture a novel tradeoff between different levels of information freshness and different response times across the servers, which can be exploited to minimize the expected AoI at the user's side. Specifically, assuming Poisson updating process for the servers and exponentially distributed response time, we derive a closed-form formula for computing the expected AoI and obtain the optimal number of responses to wait for to minimize the expected AoI. Then, we extend our analysis to the setting where the user aims to maximize the AoI-based utility, which represents the user's satisfaction level with respect to freshness of the received information. Furthermore, we consider a more realistic scenario where the user has no knowledge of the system. In this case, we reformulate the utility maximization problem as a stochastic Multi-Armed Bandit problem with side observations and leverage the unique structure of the problem to design learning algorithms with improved performance guarantees. Finally, we conduct extensive simulations to elucidate our theoretical results and compare the performance of different algorithms. Our findings reveal that under the Pull model, waiting for more than one response can significantly reduce the AoI and improve the AoI-based utility in most scenarios.