 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Text-Guided 3D-Aware Portrait Generation with Score Distillation Sampling on Distribution
Paper and Code
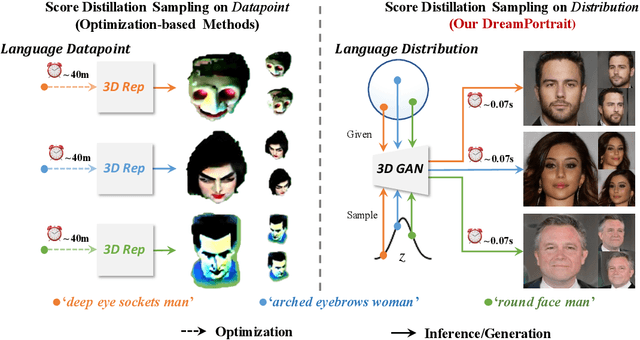

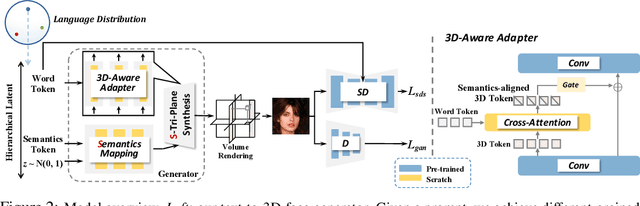

Text-to-3D is an emerging task that allows users to create 3D content with infinite possibilities. Existing works tackle the problem by optimizing a 3D representation with guidance from pre-trained diffusion models. An apparent drawback is that they need to optimize from scratch for each prompt, which is computationally expensive and often yields poor visual fidelity. In this paper, we propose DreamPortrait, which aims to generate text-guided 3D-aware portraits in a single-forward pass for efficiency. To achieve this, we extend Score Distillation Sampling from datapoint to distribution formulation, which injects semantic prior into a 3D distribution. However, the direct extension will lead to the mode collapse problem since the objective only pursues semantic alignment. Hence, we propose to optimize a distribution with hierarchical condition adapters and GAN loss regularization. For better 3D modeling, we further design a 3D-aware gated cross-attention mechanism to explicitly let the model perceive the correspondence between the text and the 3D-aware space. These elaborated designs enable our model to generate portraits with robust multi-view semantic consistency, eliminating the need for optimization-based methods. Extensive experiments demonstrate our model's highly competitive performance and significant speed boost against existing methods.