 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoPrune: Early-Stage Visual Token Pruning for Efficient MLLMs
Mar 04, 2026Multimodal Large Language Models (MLLMs) have shown strong performance in vision-language tasks, but their inference efficiency is severely limited by the exponential growth of visual tokens in complex scenarios such as high-resolution images and videos. Existing visual token pruning methods mainly operate after visual encoding, overlooking the substantial computational cost incurred during the encoding stage. To address this issue, we propose EvoPrune, an early-stage visual token pruning method for MLLMs that performs pruning directly during visual encoding. Specifically, EvoPrune employs a layer-wise pruning strategy guided by token similarity, diversity, and attention-based importance to retain the most informative visual tokens at selected encoding layers. Extensive experiments on image and video benchmarks validate the effectiveness of EvoPrune. In particular, on the VideoMME dataset, EvoPrune achieves 2$\times$ inference speedup with less than 1% performance degradation, demonstrating its potential for latency-sensitive MLLM deployment.
Prolonged Reasoning Is Not All You Need: Certainty-Based Adaptive Routing for Efficient LLM/MLLM Reasoning
May 21, 2025



Recent advancements in reasoning have significantly enhanced the capabilities of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) across diverse tasks. However, excessive reliance on chain-of-thought (CoT) reasoning can impair model performance and brings unnecessarily lengthened outputs, reducing efficiency. Our work reveals that prolonged reasoning does not universally improve accuracy and even degrade performance on simpler tasks. To address this, we propose Certainty-based Adaptive Reasoning (CAR), a novel framework that dynamically switches between short answers and long-form reasoning based on the model perplexity. CAR first generates a short answer and evaluates its perplexity, triggering reasoning only when the model exhibits low confidence (i.e., high perplexity). Experiments across diverse multimodal VQA/KIE benchmarks and text reasoning datasets show that CAR outperforms both short-answer and long-form reasoning approaches, striking an optimal balance between accuracy and efficiency.
OCRBench v2: An Improved Benchmark for Evaluating Large Multimodal Models on Visual Text Localization and Reasoning
Dec 31, 2024



Scoring the Optical Character Recognition (OCR) capabilities of Large Multimodal Models (LMMs) has witnessed growing interest recently. Existing benchmarks have highlighted the impressive performance of LMMs in text recognition; however, their abilities on certain challenging tasks, such as text localization, handwritten content extraction, and logical reasoning, remain underexplored. To bridge this gap, we introduce OCRBench v2, a large-scale bilingual text-centric benchmark with currently the most comprehensive set of tasks (4x more tasks than the previous multi-scene benchmark OCRBench), the widest coverage of scenarios (31 diverse scenarios including street scene, receipt, formula, diagram, and so on), and thorough evaluation metrics, with a total of 10,000 human-verified question-answering pairs and a high proportion of difficult samples. After carefully benchmarking state-of-the-art LMMs on OCRBench v2, we find that 20 out of 22 LMMs score below 50 (100 in total) and suffer from five-type limitations, including less frequently encountered text recognition, fine-grained perception, layout perception, complex element parsing, and logical reasoning. The benchmark and evaluation scripts are available at https://github.com/Yuliang-liu/MultimodalOCR.
MCTBench: Multimodal Cognition towards Text-Rich Visual Scenes Benchmark
Oct 15, 2024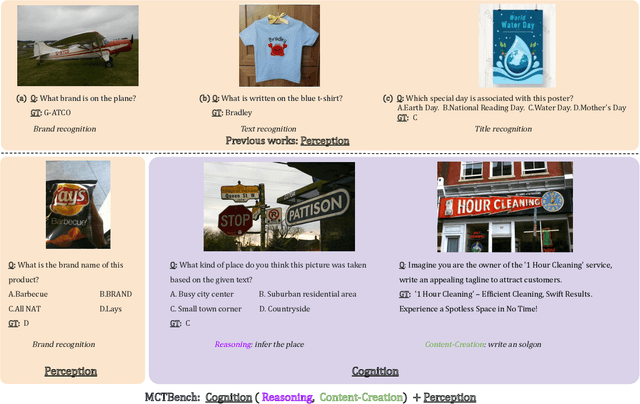
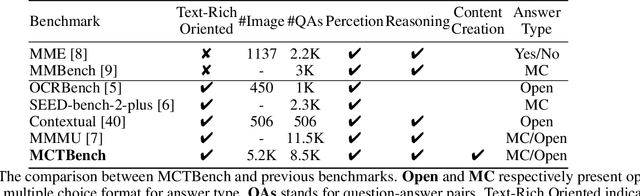
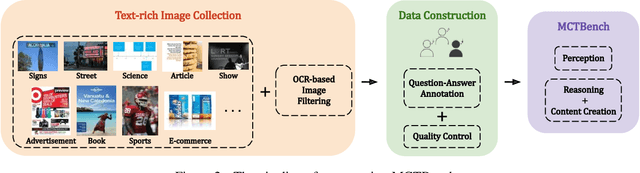
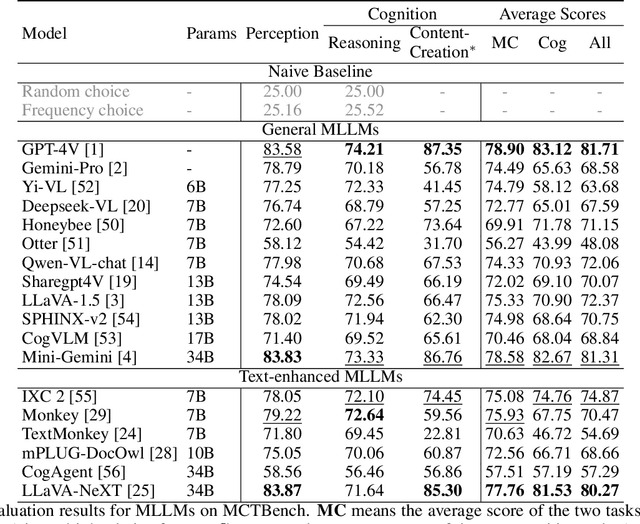
The comprehension of text-rich visual scenes has become a focal point for evaluating Multi-modal Large Language Models (MLLMs) due to their widespread applications. Current benchmarks tailored to the scenario emphasize perceptual capabilities, while overlooking the assessment of cognitive abilities. To address this limitation, we introduce a Multimodal benchmark towards Text-rich visual scenes, to evaluate the Cognitive capabilities of MLLMs through visual reasoning and content-creation tasks (MCTBench). To mitigate potential evaluation bias from the varying distributions of datasets, MCTBench incorporates several perception tasks (e.g., scene text recognition) to ensure a consistent comparison of both the cognitive and perceptual capabilities of MLLMs. To improve the efficiency and fairness of content-creation evaluation, we conduct an automatic evaluation pipeline. Evaluations of various MLLMs on MCTBench reveal that, despite their impressive perceptual capabilities, their cognition abilities require enhancement. We hope MCTBench will offer the community an efficient resource to explore and enhance cognitive capabilities towards text-rich visual scenes.
ParGo: Bridging Vision-Language with Partial and Global Views
Aug 23, 2024
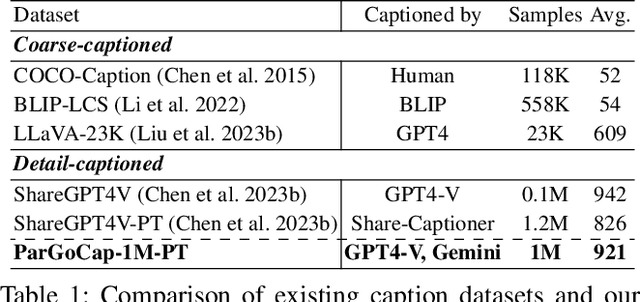
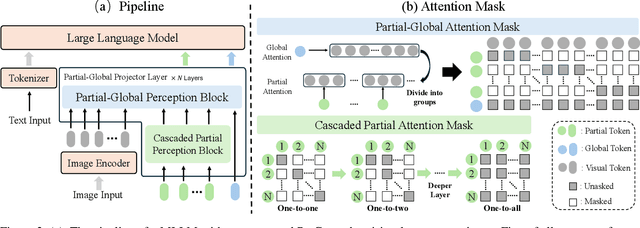
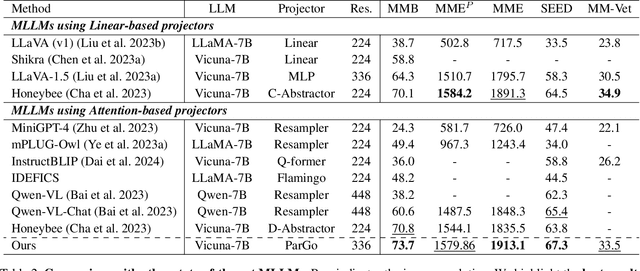
This work presents ParGo, a novel Partial-Global projector designed to connect the vision and language modalities for Multimodal Large Language Models (MLLMs). Unlike previous works that rely on global attention-based projectors, our ParGo bridges the representation gap between the separately pre-trained vision encoders and the LLMs by integrating global and partial views, which alleviates the overemphasis on prominent regions. To facilitate the effective training of ParGo, we collect a large-scale detail-captioned image-text dataset named ParGoCap-1M-PT, consisting of 1 million images paired with high-quality captions. Extensive experiments on several MLLM benchmarks demonstrate the effectiveness of our ParGo, highlighting its superiority in aligning vision and language modalities. Compared to conventional Q-Former projector, our ParGo achieves an improvement of 259.96 in MME benchmark. Furthermore, our experiments reveal that ParGo significantly outperforms other projectors, particularly in tasks that emphasize detail perception ability.
Efficient Discrete Physics-informed Neural Networks for Addressing Evolutionary Partial Differential Equations
Dec 22, 2023Physics-informed neural networks (PINNs) have shown promising potential for solving partial differential equations (PDEs) using deep learning. However, PINNs face training difficulties for evolutionary PDEs, particularly for dynamical systems whose solutions exhibit multi-scale or turbulent behavior over time. The reason is that PINNs may violate the temporal causality property since all the temporal features in the PINNs loss are trained simultaneously. This paper proposes to use implicit time differencing schemes to enforce temporal causality, and use transfer learning to sequentially update the PINNs in space as surrogates for PDE solutions in different time frames. The evolving PINNs are better able to capture the varying complexities of the evolutionary equations, while only requiring minor updates between adjacent time frames. Our method is theoretically proven to be convergent if the time step is small and each PINN in different time frames is well-trained. In addition, we provide state-of-the-art (SOTA) numerical results for a variety of benchmarks for which existing PINNs formulations may fail or be inefficient. We demonstrate that the proposed method improves the accuracy of PINNs approximation for evolutionary PDEs and improves efficiency by a factor of 4-40x.
Physics-guided Data Augmentation for Learning the Solution Operator of Linear Differential Equations
Dec 08, 2022Neural networks, especially the recent proposed neural operator models, are increasingly being used to find the solution operator of differential equations. Compared to traditional numerical solvers, they are much faster and more efficient in practical applications. However, one critical issue is that training neural operator models require large amount of ground truth data, which usually comes from the slow numerical solvers. In this paper, we propose a physics-guided data augmentation (PGDA) method to improve the accuracy and generalization of neural operator models. Training data is augmented naturally through the physical properties of differential equations such as linearity and translation. We demonstrate the advantage of PGDA on a variety of linear differential equations, showing that PGDA can improve the sample complexity and is robust to distributional shift.
* Nanjing University of Aeronautics and Astronautics
VI-PINNs: Variance-involved Physics-informed Neural Networks for Fast and Accurate Prediction of Partial Differential Equations
Nov 30, 2022



Although physics-informed neural networks(PINNs) have progressed a lot in many real applications recently, there remains problems to be further studied, such as achieving more accurate results, taking less training time, and quantifying the uncertainty of the predicted results. Recent advances in PINNs have indeed significantly improved the performance of PINNs in many aspects, but few have considered the effect of variance in the training process. In this work, we take into consideration the effect of variance and propose our VI-PINNs to give better predictions. We output two values in the final layer of the network to represent the predicted mean and variance respectively, and the latter is used to represent the uncertainty of the output. A modified negative log-likelihood loss and an auxiliary task are introduced for fast and accurate training. We perform several experiments on a wide range of different problems to highlight the advantages of our approach. The results convey that our method not only gives more accurate predictions but also converges faster.
ERNIE-UniX2: A Unified Cross-lingual Cross-modal Framework for Understanding and Generation
Nov 09, 2022



Recent cross-lingual cross-modal works attempt to extend Vision-Language Pre-training (VLP) models to non-English inputs and achieve impressive performance. However, these models focus only on understanding tasks utilizing encoder-only architecture. In this paper, we propose ERNIE-UniX2, a unified cross-lingual cross-modal pre-training framework for both generation and understanding tasks. ERNIE-UniX2 integrates multiple pre-training paradigms (e.g., contrastive learning and language modeling) based on encoder-decoder architecture and attempts to learn a better joint representation across languages and modalities. Furthermore, ERNIE-UniX2 can be seamlessly fine-tuned for varieties of generation and understanding downstream tasks. Pre-trained on both multilingual text-only and image-text datasets, ERNIE-UniX2 achieves SOTA results on various cross-lingual cross-modal generation and understanding tasks such as multimodal machine translation and multilingual visual question answering.
ERNIE-ViL 2.0: Multi-view Contrastive Learning for Image-Text Pre-training
Sep 30, 2022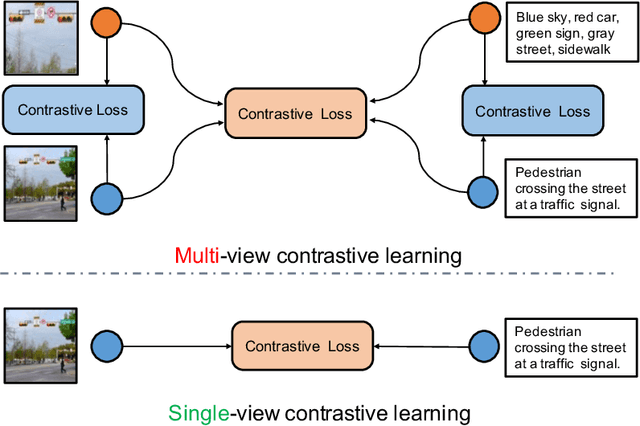
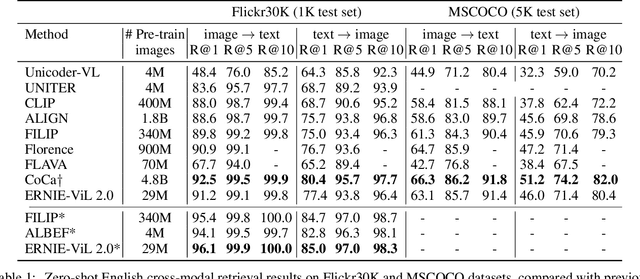
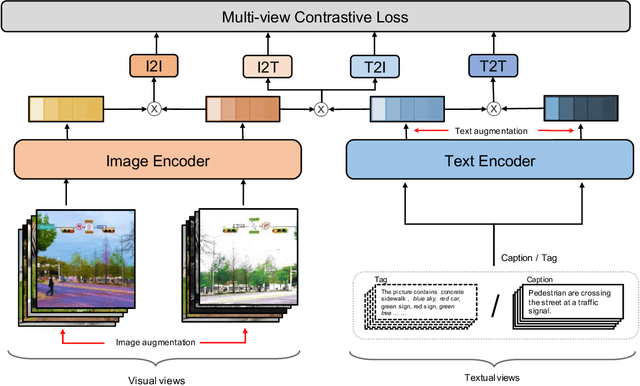
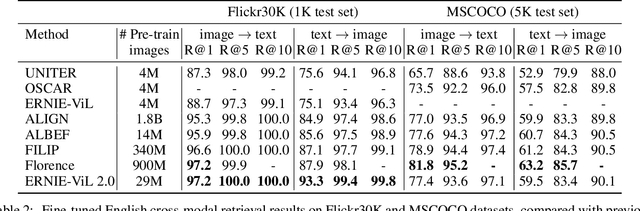
Recent Vision-Language Pre-trained (VLP) models based on dual encoder have attracted extensive attention from academia and industry due to their superior performance on various cross-modal tasks and high computational efficiency. They attempt to learn cross-modal representation using contrastive learning on image-text pairs, however, the built inter-modal correlations only rely on a single view for each modality. Actually, an image or a text contains various potential views, just as humans could capture a real-world scene via diverse descriptions or photos. In this paper, we propose ERNIE-ViL 2.0, a Multi-View Contrastive learning framework to build intra-modal and inter-modal correlations between diverse views simultaneously, aiming at learning a more robust cross-modal representation. Specifically, we construct multiple views within each modality to learn the intra-modal correlation for enhancing the single-modal representation. Besides the inherent visual/textual views, we construct sequences of object tags as a special textual view to narrow the cross-modal semantic gap on noisy image-text pairs. Pre-trained with 29M publicly available datasets, ERNIE-ViL 2.0 achieves competitive results on English cross-modal retrieval. Additionally, to generalize our method to Chinese cross-modal tasks, we train ERNIE-ViL 2.0 through scaling up the pre-training datasets to 1.5B Chinese image-text pairs, resulting in significant improvements compared to previous SOTA results on Chinese cross-modal retrieval. We release our pre-trained models in https://github.com/PaddlePaddle/ERNIE.