 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParGo: Bridging Vision-Language with Partial and Global Views
Paper and Code

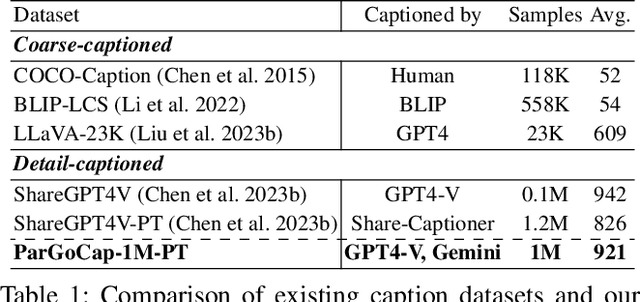
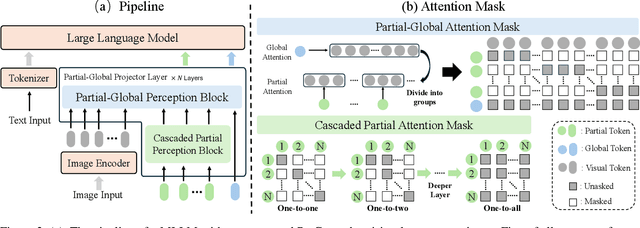
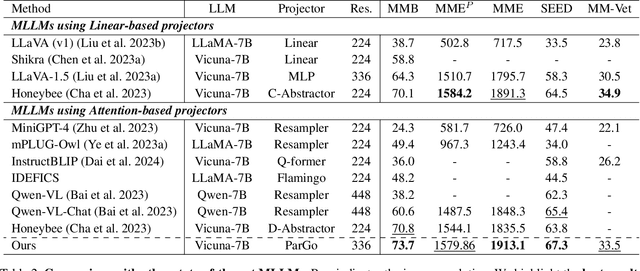
This work presents ParGo, a novel Partial-Global projector designed to connect the vision and language modalities for Multimodal Large Language Models (MLLMs). Unlike previous works that rely on global attention-based projectors, our ParGo bridges the representation gap between the separately pre-trained vision encoders and the LLMs by integrating global and partial views, which alleviates the overemphasis on prominent regions. To facilitate the effective training of ParGo, we collect a large-scale detail-captioned image-text dataset named ParGoCap-1M-PT, consisting of 1 million images paired with high-quality captions. Extensive experiments on several MLLM benchmarks demonstrate the effectiveness of our ParGo, highlighting its superiority in aligning vision and language modalities. Compared to conventional Q-Former projector, our ParGo achieves an improvement of 259.96 in MME benchmark. Furthermore, our experiments reveal that ParGo significantly outperforms other projectors, particularly in tasks that emphasize detail perception ability.