 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Decoder: Towards Training Recurrent Neural Networks for Time Series Forecasting
Jun 14, 2024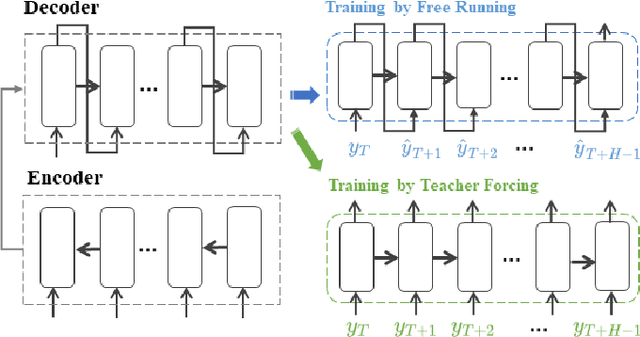
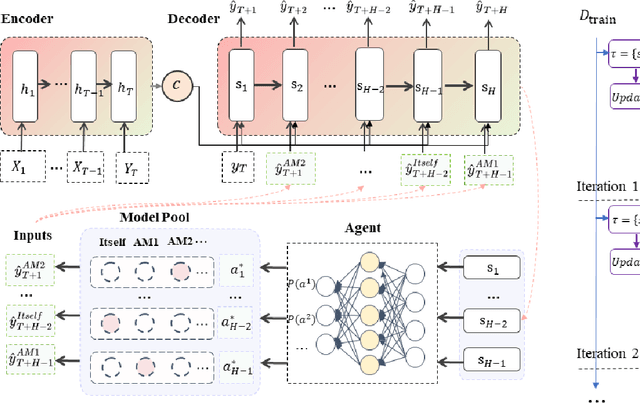
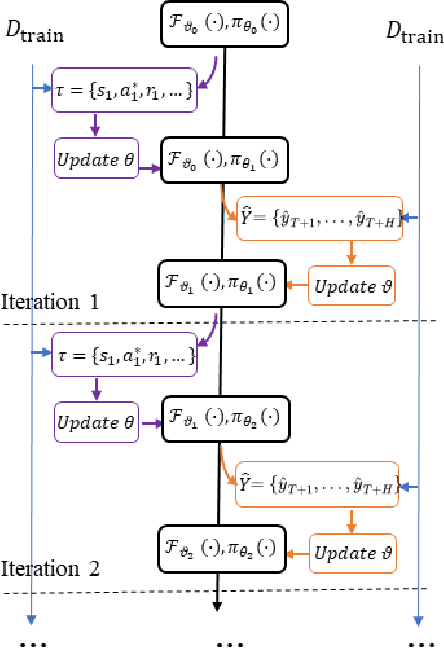
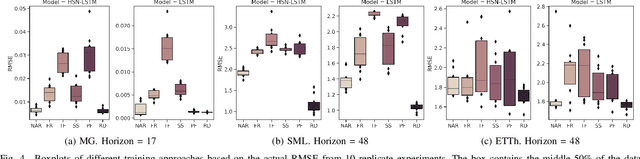
Recurrent neural network-based sequence-to-sequence models have been extensively applied for multi-step-ahead time series forecasting. These models typically involve a decoder trained using either its previous forecasts or the actual observed values as the decoder inputs. However, relying on self-generated predictions can lead to the rapid accumulation of errors over multiple steps, while using the actual observations introduces exposure bias as these values are unavailable during the extrapolation stage. In this regard, this study proposes a novel training approach called reinforced decoder, which introduces auxiliary models to generate alternative decoder inputs that remain accessible when extrapolating. Additionally, a reinforcement learning algorithm is utilized to dynamically select the optimal inputs to improve accuracy. Comprehensive experiments demonstrate that our approach outperforms representative training methods over several datasets. Furthermore, the proposed approach also exhibits promising performance when generalized to self-attention-based sequence-to-sequence forecasting models.
Sketched Ridgeless Linear Regression: The Role of Downsampling
Feb 02, 2023Overparametrization often helps improve the generalization performance. This paper proposes a dual view of overparametrization suggesting that downsampling may also help generalize. Motivated by this dual view, we characterize two out-of-sample prediction risks of the sketched ridgeless least square estimator in the proportional regime $m\asymp n \asymp p$, where $m$ is the sketching size, $n$ the sample size, and $p$ the feature dimensionality. Our results reveal the statistical role of downsampling. Specifically, downsampling does not always hurt the generalization performance, and may actually help improve it in some cases. We identify the optimal sketching sizes that minimize the out-of-sample prediction risks, and find that the optimally sketched estimator has stabler risk curves that eliminates the peaks of those for the full-sample estimator. We then propose a practical procedure to empirically identify the optimal sketching size. Finally, we extend our results to cover central limit theorems and misspecified models. Numerical studies strongly support our theory.
Comprehensive learning particle swarm optimization enabled modeling framework for multi-step-ahead influenza prediction
Oct 27, 2021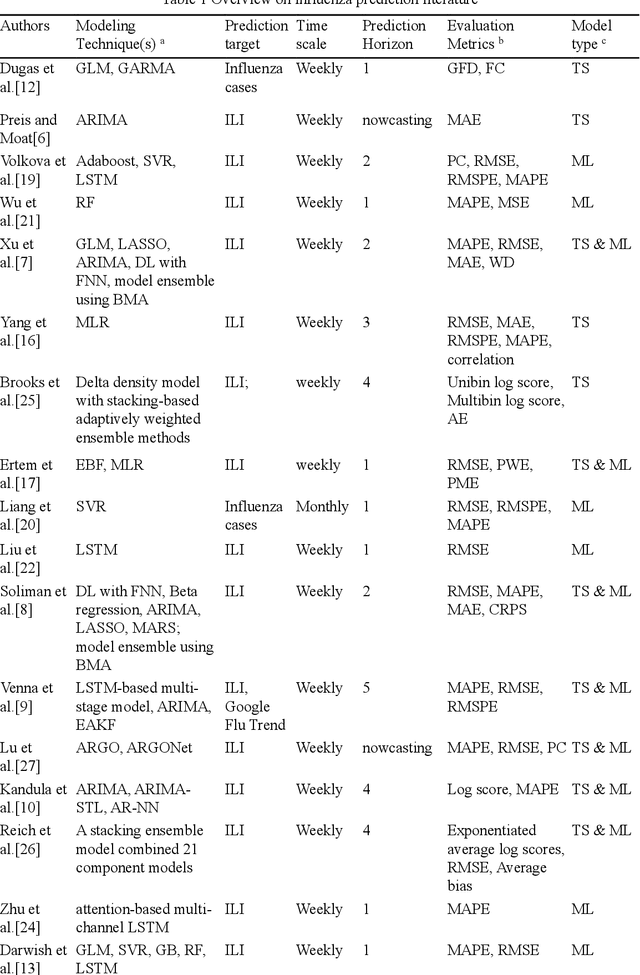
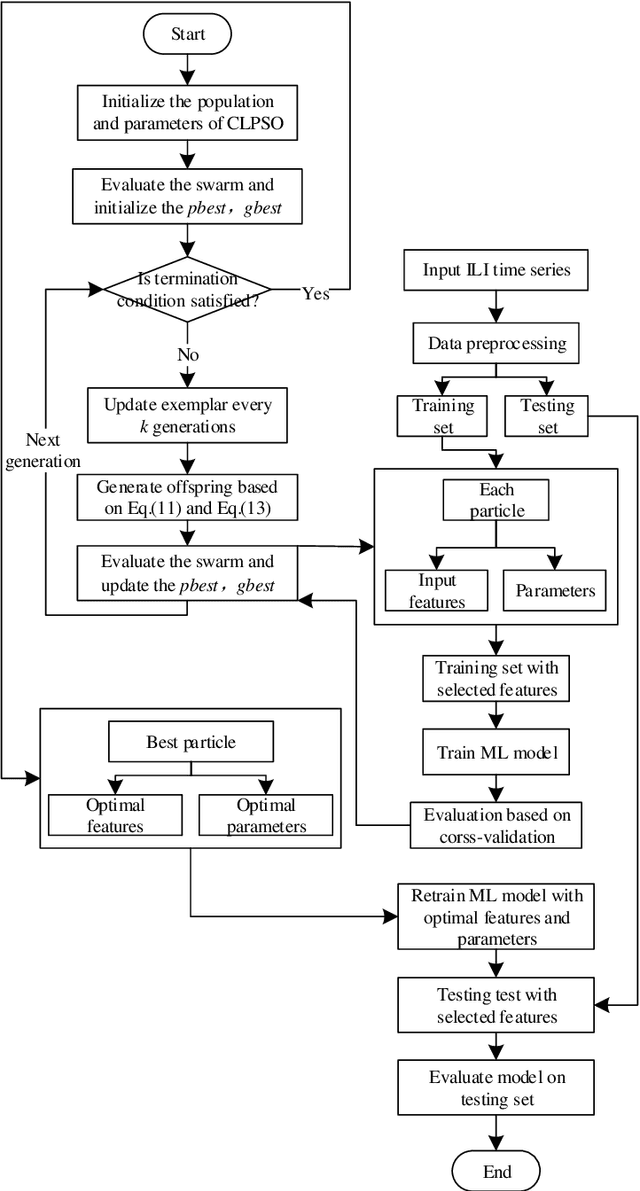
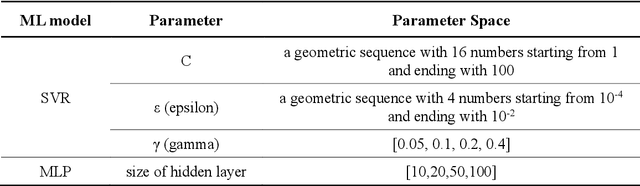
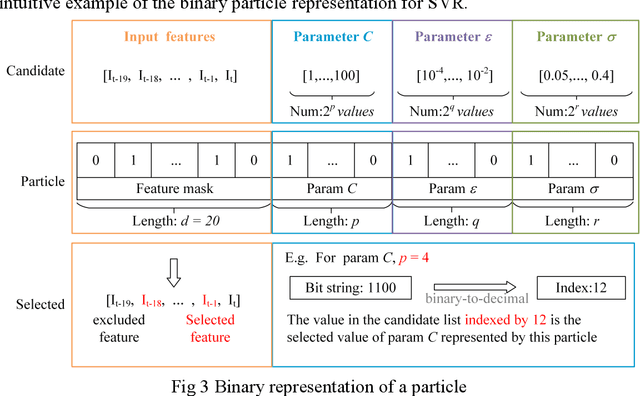
Epidemics of influenza are major public health concerns. Since influenza prediction always relies on the weekly clinical or laboratory surveillance data, typically the weekly Influenza-like illness (ILI) rate series, accurate multi-step-ahead influenza predictions using ILI series is of great importance, especially, to the potential coming influenza outbreaks. This study proposes Comprehensive Learning Particle Swarm Optimization based Machine Learning (CLPSO-ML) framework incorporating support vector regression (SVR) and multilayer perceptron (MLP) for multi-step-ahead influenza prediction. A comprehensive examination and comparison of the performance and potential of three commonly used multi-step-ahead prediction modeling strategies, including iterated strategy, direct strategy and multiple-input multiple-output (MIMO) strategy, was conducted using the weekly ILI rate series from both the Southern and Northern China. The results show that: (1) The MIMO strategy achieves the best multi-step-ahead prediction, and is potentially more adaptive for longer horizon; (2) The iterated strategy demonstrates special potentials for deriving the least time difference between the occurrence of the predicted peak value and the true peak value of an influenza outbreak; (3) For ILI in the Northern China, SVR model implemented with MIMO strategy performs best, and SVR with iterated strategy also shows remarkable performance especially during outbreak periods; while for ILI in the Southern China, both SVR and MLP models with MIMO strategy have competitive prediction performance