 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Object Nets: Learning Dense Visual Object Descriptors By and For Robotic Manipulation
Sep 07, 2018
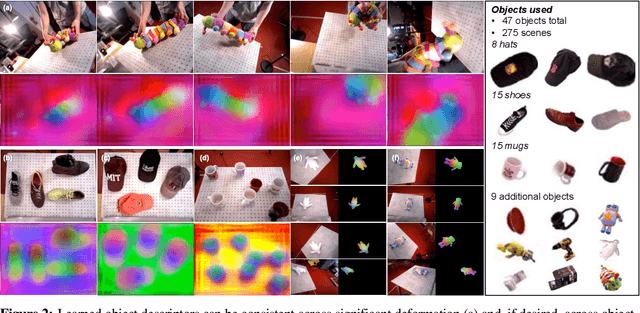
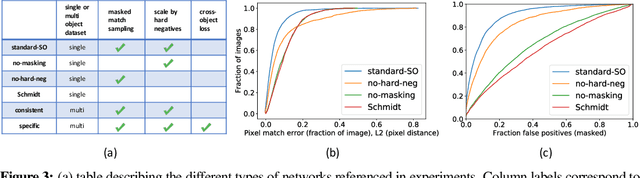
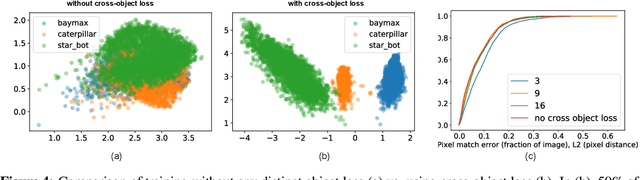
What is the right object representation for manipulation? We would like robots to visually perceive scenes and learn an understanding of the objects in them that (i) is task-agnostic and can be used as a building block for a variety of manipulation tasks, (ii) is generally applicable to both rigid and non-rigid objects, (iii) takes advantage of the strong priors provided by 3D vision, and (iv) is entirely learned from self-supervision. This is hard to achieve with previous methods: much recent work in grasping does not extend to grasping specific objects or other tasks, whereas task-specific learning may require many trials to generalize well across object configurations or other tasks. In this paper we present Dense Object Nets, which build on recent developments in self-supervised dense descriptor learning, as a consistent object representation for visual understanding and manipulation. We demonstrate they can be trained quickly (approximately 20 minutes) for a wide variety of previously unseen and potentially non-rigid objects. We additionally present novel contributions to enable multi-object descriptor learning, and show that by modifying our training procedure, we can either acquire descriptors which generalize across classes of objects, or descriptors that are distinct for each object instance. Finally, we demonstrate the novel application of learned dense descriptors to robotic manipulation. We demonstrate grasping of specific points on an object across potentially deformed object configurations, and demonstrate using class general descriptors to transfer specific grasps across objects in a class.
NanoMap: Fast, Uncertainty-Aware Proximity Queries with Lazy Search over Local 3D Data
Feb 25, 2018

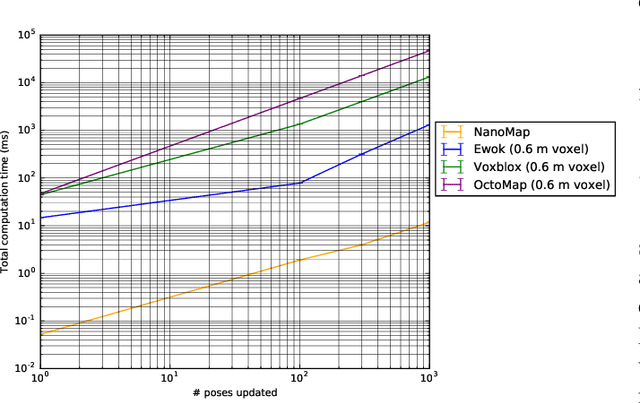
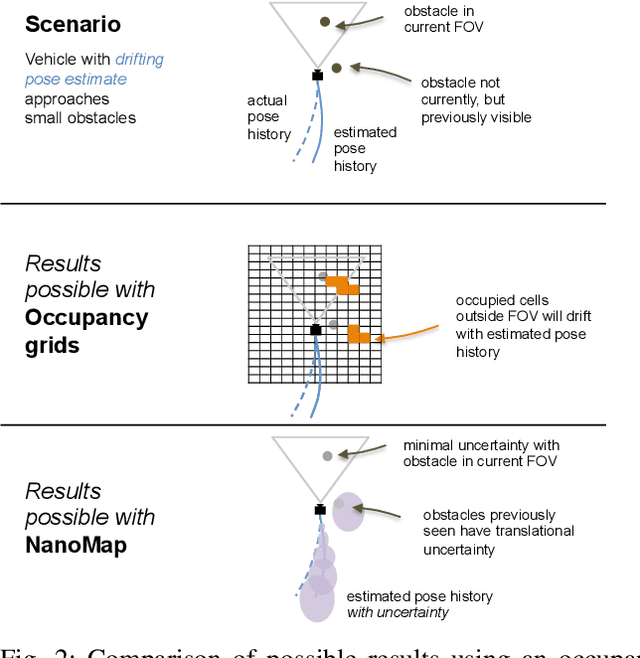
We would like robots to be able to safely navigate at high speed, efficiently use local 3D information, and robustly plan motions that consider pose uncertainty of measurements in a local map structure. This is hard to do with previously existing mapping approaches, like occupancy grids, that are focused on incrementally fusing 3D data into a common world frame. In particular, both their fragile sensitivity to state estimation errors and computational cost can be limiting. We develop an alternative framework, NanoMap, which alleviates the need for global map fusion and enables a motion planner to efficiently query pose-uncertainty-aware local 3D geometric information. The key idea of NanoMap is to store a history of noisy relative pose transforms and search over a corresponding set of depth sensor measurements for the minimum-uncertainty view of a queried point in space. This approach affords a variety of capabilities not offered by traditional mapping techniques: (a) the pose uncertainty associated with 3D data can be incorporated in motion planning, (b) poses can be updated (i.e., from loop closures) with minimal computational effort, and (c) 3D data can be fused lazily for the purpose of planning. We provide an open-source implementation of NanoMap, and analyze its capabilities and computational efficiency in simulation experiments. Finally, we demonstrate in hardware its effectiveness for fast 3D obstacle avoidance onboard a quadrotor flying up to 10 m/s.
LabelFusion: A Pipeline for Generating Ground Truth Labels for Real RGBD Data of Cluttered Scenes
Sep 26, 2017

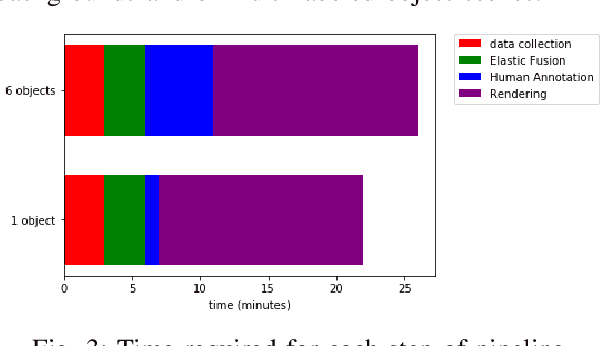

Deep neural network (DNN) architectures have been shown to outperform traditional pipelines for object segmentation and pose estimation using RGBD data, but the performance of these DNN pipelines is directly tied to how representative the training data is of the true data. Hence a key requirement for employing these methods in practice is to have a large set of labeled data for your specific robotic manipulation task, a requirement that is not generally satisfied by existing datasets. In this paper we develop a pipeline to rapidly generate high quality RGBD data with pixelwise labels and object poses. We use an RGBD camera to collect video of a scene from multiple viewpoints and leverage existing reconstruction techniques to produce a 3D dense reconstruction. We label the 3D reconstruction using a human assisted ICP-fitting of object meshes. By reprojecting the results of labeling the 3D scene we can produce labels for each RGBD image of the scene. This pipeline enabled us to collect over 1,000,000 labeled object instances in just a few days. We use this dataset to answer questions related to how much training data is required, and of what quality the data must be, to achieve high performance from a DNN architecture.