 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceiver-Actor: A Multi-Task Transformer for Robotic Manipulation
Paper and Code

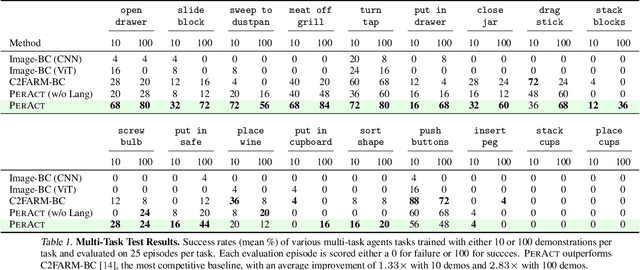
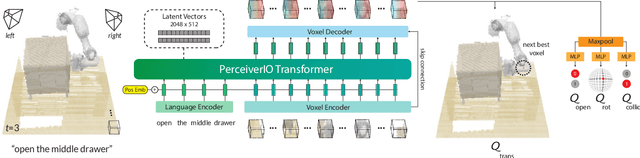
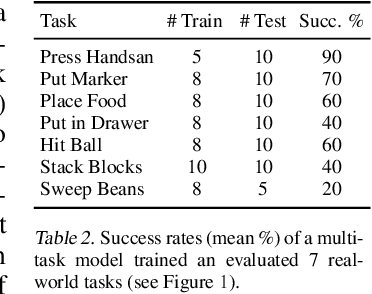
Transformers have revolutionized vision and natural language processing with their ability to scale with large datasets. But in robotic manipulation, data is both limited and expensive. Can we still benefit from Transformers with the right problem formulation? We investigate this question with PerAct, a language-conditioned behavior-cloning agent for multi-task 6-DoF manipulation. PerAct encodes language goals and RGB-D voxel observations with a Perceiver Transformer, and outputs discretized actions by "detecting the next best voxel action". Unlike frameworks that operate on 2D images, the voxelized observation and action space provides a strong structural prior for efficiently learning 6-DoF policies. With this formulation, we train a single multi-task Transformer for 18 RLBench tasks (with 249 variations) and 7 real-world tasks (with 18 variations) from just a few demonstrations per task. Our results show that PerAct significantly outperforms unstructured image-to-action agents and 3D ConvNet baselines for a wide range of tabletop tasks.