 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Correspondence in Visuomotor Policy Learning
Sep 16, 2019
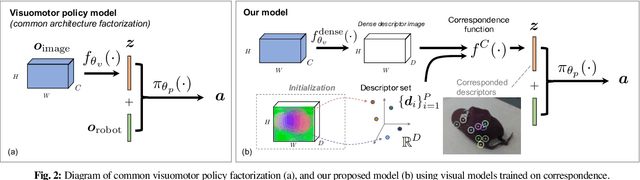
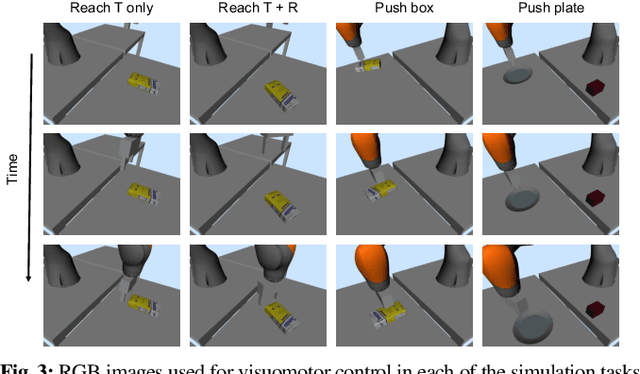
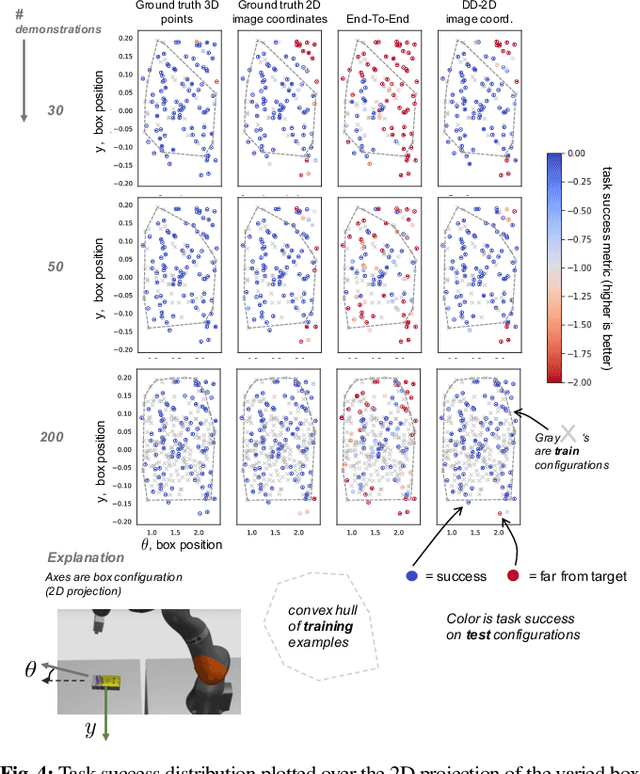
In this paper we explore using self-supervised correspondence for improving the generalization performance and sample efficiency of visuomotor policy learning. Prior work has primarily used approaches such as autoencoding, pose-based losses, and end-to-end policy optimization in order to train the visual portion of visuomotor policies. We instead propose an approach using self-supervised dense visual correspondence training, and show this enables visuomotor policy learning with surprisingly high generalization performance with modest amounts of data: using imitation learning, we demonstrate extensive hardware validation on challenging manipulation tasks with as few as 50 demonstrations. Our learned policies can generalize across classes of objects, react to deformable object configurations, and manipulate textureless symmetrical objects in a variety of backgrounds, all with closed-loop, real-time vision-based policies. Simulated imitation learning experiments suggest that correspondence training offers sample complexity and generalization benefits compared to autoencoding and end-to-end training.
kPAM: KeyPoint Affordances for Category-Level Robotic Manipulation
Mar 15, 2019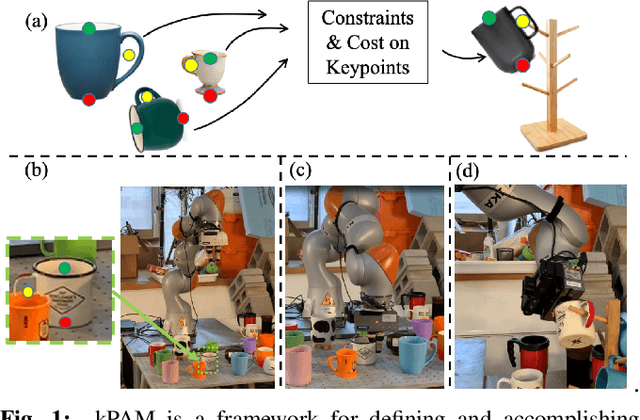



We would like robots to achieve purposeful manipulation by placing any instance from a category of objects into a desired set of goal states. Existing manipulation pipelines typically specify the desired configuration as a target 6-DOF pose and rely on explicitly estimating the pose of the manipulated objects. However, representing an object with a parameterized transformation defined on a fixed template cannot capture large intra-category shape variation, and specifying a target pose at a category level can be physically infeasible or fail to accomplish the task -- e.g. knowing the pose and size of a coffee mug relative to some canonical mug is not sufficient to successfully hang it on a rack by its handle. Hence we propose a novel formulation of category-level manipulation that uses semantic 3D keypoints as the object representation. This keypoint representation enables a simple and interpretable specification of the manipulation target as geometric costs and constraints on the keypoints, which flexibly generalizes existing pose-based manipulation methods. Using this formulation, we factor the manipulation policy into instance segmentation, 3D keypoint detection, optimization-based robot action planning and local dense-geometry-based action execution. This factorization allows us to leverage advances in these sub-problems and combine them into a general and effective perception-to-action manipulation pipeline. Our pipeline is robust to large intra-category shape variation and topology changes as the keypoint representation ignores task-irrelevant geometric details. Extensive hardware experiments demonstrate our method can reliably accomplish tasks with never-before seen objects in a category, such as placing shoes and mugs with significant shape variation into category level target configurations.
DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation
Jan 16, 2019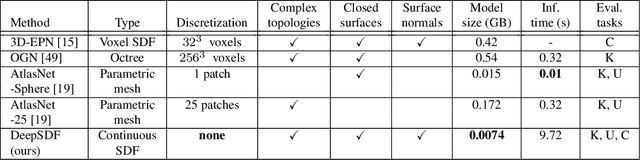

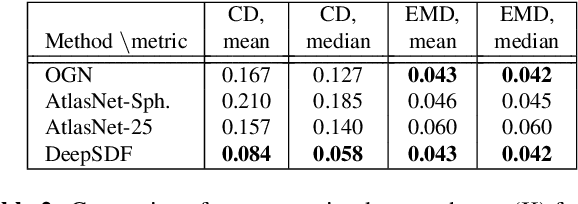

Computer graphics, 3D computer vision and robotics communities have produced multiple approaches to representing 3D geometry for rendering and reconstruction. These provide trade-offs across fidelity, efficiency and compression capabilities. In this work, we introduce DeepSDF, a learned continuous Signed Distance Function (SDF) representation of a class of shapes that enables high quality shape representation, interpolation and completion from partial and noisy 3D input data. DeepSDF, like its classical counterpart, represents a shape's surface by a continuous volumetric field: the magnitude of a point in the field represents the distance to the surface boundary and the sign indicates whether the region is inside (-) or outside (+) of the shape, hence our representation implicitly encodes a shape's boundary as the zero-level-set of the learned function while explicitly representing the classification of space as being part of the shapes interior or not. While classical SDF's both in analytical or discretized voxel form typically represent the surface of a single shape, DeepSDF can represent an entire class of shapes. Furthermore, we show state-of-the-art performance for learned 3D shape representation and completion while reducing the model size by an order of magnitude compared with previous work.