 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafely Learning Visuo-Tactile Feedback Policies in Real For Industrial Insertion
Oct 04, 2022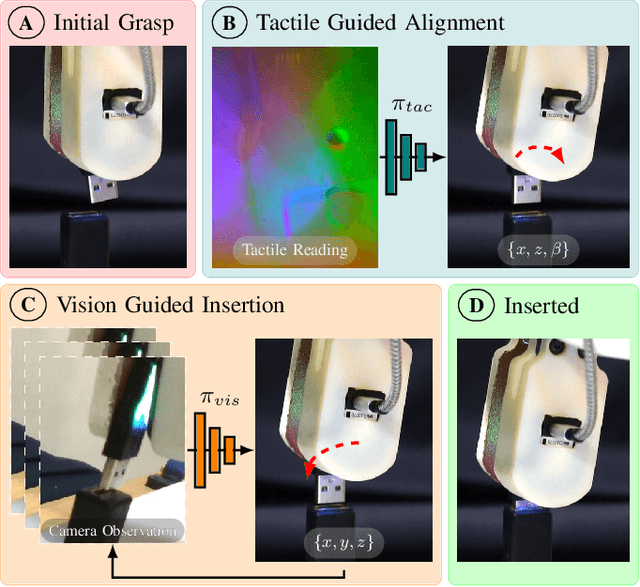
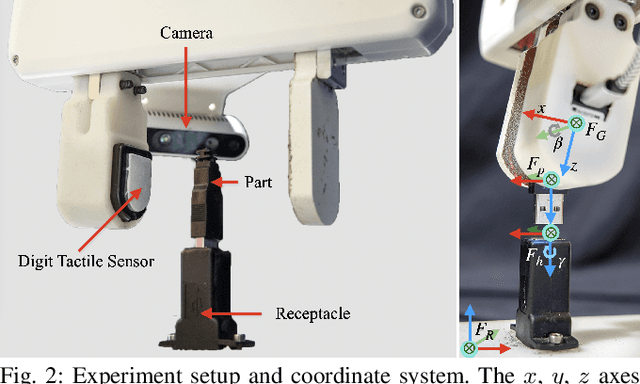

Industrial insertion tasks are often performed repetitively with parts that are subject to tight tolerances and prone to breakage. In this paper, we present a safe method to learn a visuo-tactile insertion policy that is robust against grasp pose variations while minimizing human inputs and collision between the robot and the environment. We achieve this by dividing the insertion task into two phases. In the first align phase, we learn a tactile-based grasp pose estimation model to align the insertion part with the receptacle. In the second insert phase, we learn a vision-based policy to guide the part into the receptacle. Using force-torque sensing, we also develop a safe self-supervised data collection pipeline that limits collision between the part and the surrounding environment. Physical experiments on the USB insertion task from the NIST Assembly Taskboard suggest that our approach can achieve 45/45 insertion successes on 45 different initial grasp poses, improving on two baselines: (1) a behavior cloning agent trained on 50 human insertion demonstrations (1/45) and (2) an online RL policy (TD3) trained in real (0/45).
SpeedFolding: Learning Efficient Bimanual Folding of Garments
Aug 22, 2022

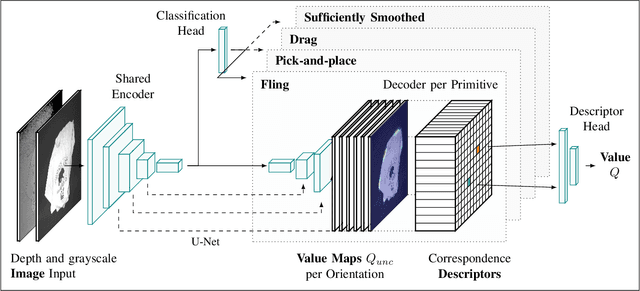
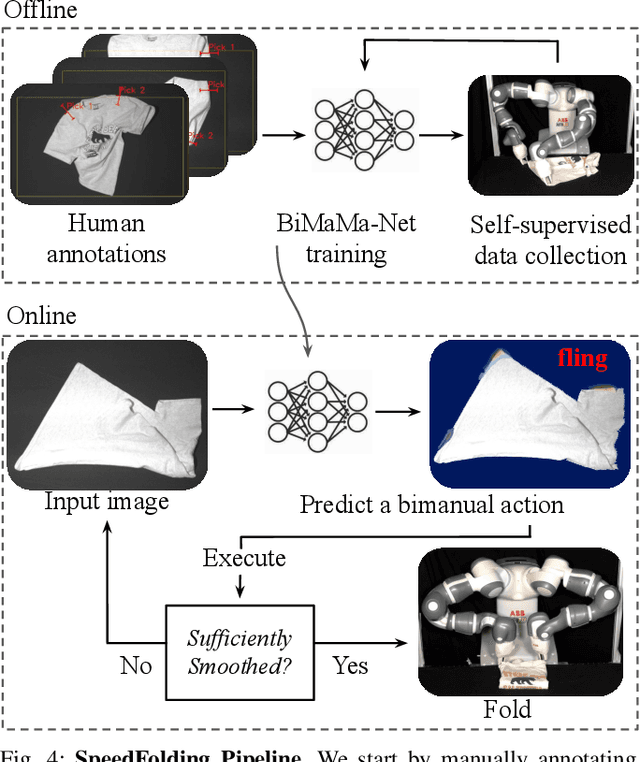
Folding garments reliably and efficiently is a long standing challenge in robotic manipulation due to the complex dynamics and high dimensional configuration space of garments. An intuitive approach is to initially manipulate the garment to a canonical smooth configuration before folding. In this work, we develop SpeedFolding, a reliable and efficient bimanual system, which given user-defined instructions as folding lines, manipulates an initially crumpled garment to (1) a smoothed and (2) a folded configuration. Our primary contribution is a novel neural network architecture that is able to predict pairs of gripper poses to parameterize a diverse set of bimanual action primitives. After learning from 4300 human-annotated and self-supervised actions, the robot is able to fold garments from a random initial configuration in under 120s on average with a success rate of 93%. Real-world experiments show that the system is able to generalize to unseen garments of different color, shape, and stiffness. While prior work achieved 3-6 Folds Per Hour (FPH), SpeedFolding achieves 30-40 FPH.
Learning a Generative Transition Model for Uncertainty-Aware Robotic Manipulation
Jul 06, 2021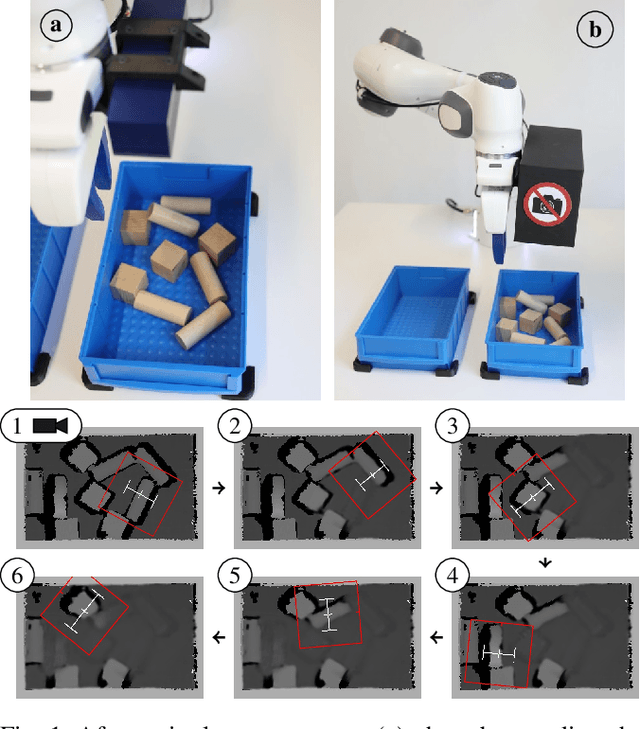
Robot learning of real-world manipulation tasks remains challenging and time consuming, even though actions are often simplified by single-step manipulation primitives. In order to compensate the removed time dependency, we additionally learn an image-to-image transition model that is able to predict a next state including its uncertainty. We apply this approach to bin picking, the task of emptying a bin using grasping as well as pre-grasping manipulation as fast as possible. The transition model is trained with up to 42000 pairs of real-world images before and after a manipulation action. Our approach enables two important skills: First, for applications with flange-mounted cameras, picks per hours (PPH) can be increased by around 15% by skipping image measurements. Second, we use the model to plan action sequences ahead of time and optimize time-dependent rewards, e.g. to minimize the number of actions required to empty the bin. We evaluate both improvements with real-robot experiments and achieve over 700 PPH in the YCB Box and Blocks Test.
Jerk-limited Real-time Trajectory Generation with Arbitrary Target States
May 11, 2021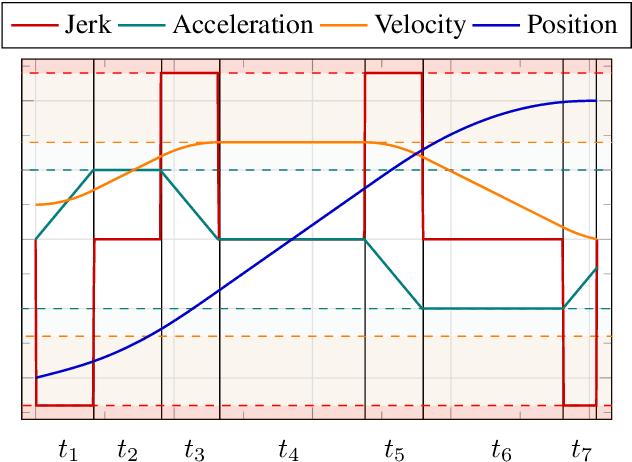
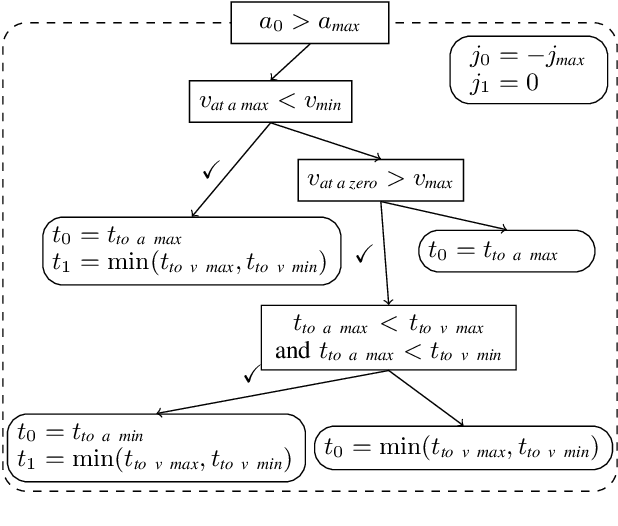
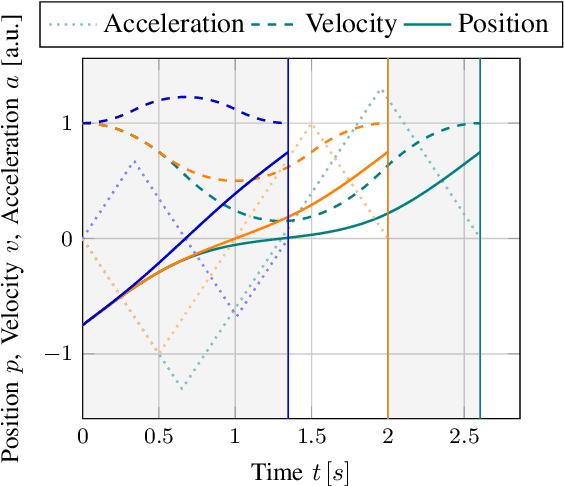
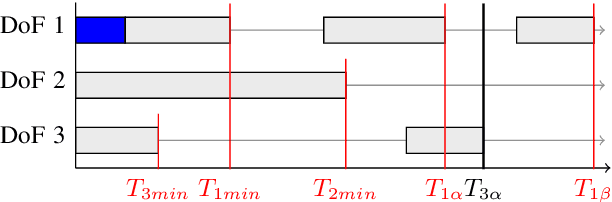
We present Ruckig, an algorithm for Online Trajectory Generation (OTG) respecting third-order constraints and complete kinematic target states. Given any initial state of a system with multiple Degrees of Freedom (DoFs), Ruckig calculates a time-optimal trajectory to an arbitrary target state defined by its position, velocity, and acceleration limited by velocity, acceleration, and jerk constraints. The proposed algorithm and implementation allows three contributions: (1) To the best of our knowledge, we derive the first OTG algorithm with non-zero target acceleration, resulting in a complete defined target state. (2) This is the first open-source prototype of time-optimal OTG with limited jerk. (3) Ruckig allows for directional velocity and acceleration limits, enabling robots to better use their dynamical resources. We evaluate the robustness and real-time capability of the proposed algorithm on a test suite with over 1,000,000,000 random trajectories as well as in real-world applications.
Robot Learning of 6 DoF Grasping using Model-based Adaptive Primitives
Mar 23, 2021
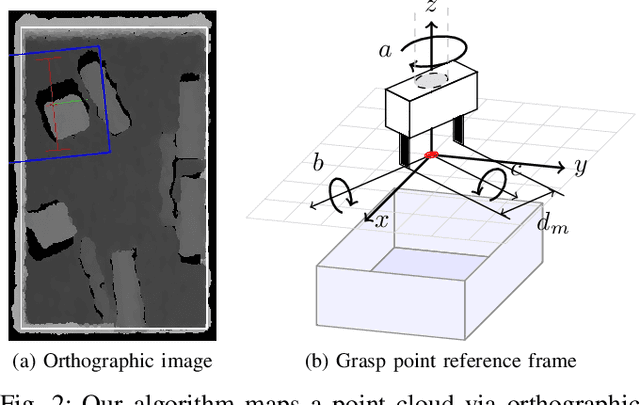
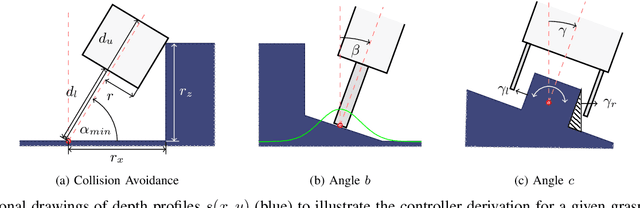
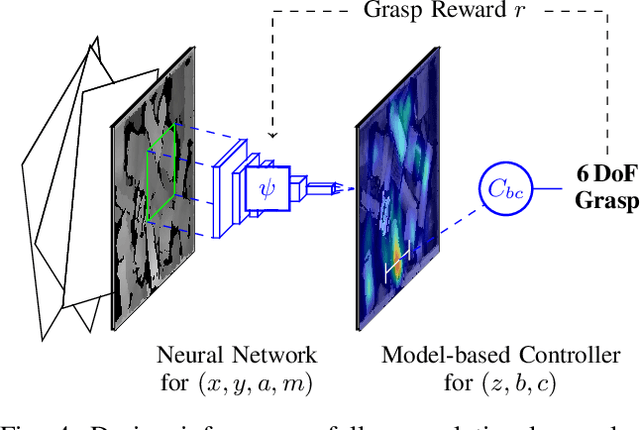
Robot learning is often simplified to planar manipulation due to its data consumption. Then, a common approach is to use a fully-convolutional neural network to estimate the reward of grasp primitives. In this work, we extend this approach by parametrizing the two remaining, lateral Degrees of Freedom (DoFs) of the primitives. We apply this principle to the task of 6 DoF bin picking: We introduce a model-based controller to calculate angles that avoid collisions, maximize the grasp quality while keeping the uncertainty small. As the controller is integrated into the training, our hybrid approach is able to learn about and exploit the model-based controller. After real-world training of 27000 grasp attempts, the robot is able to grasp known objects with a success rate of over 92% in dense clutter. Grasp inference takes less than 50ms. In further real-world experiments, we evaluate grasp rates in a range of scenarios including its ability to generalize to unknown objects. We show that the system is able to avoid collisions, enabling grasps that would not be possible without primitive adaption.
Self-supervised Learning for Precise Pick-and-place without Object Model
Jun 15, 2020
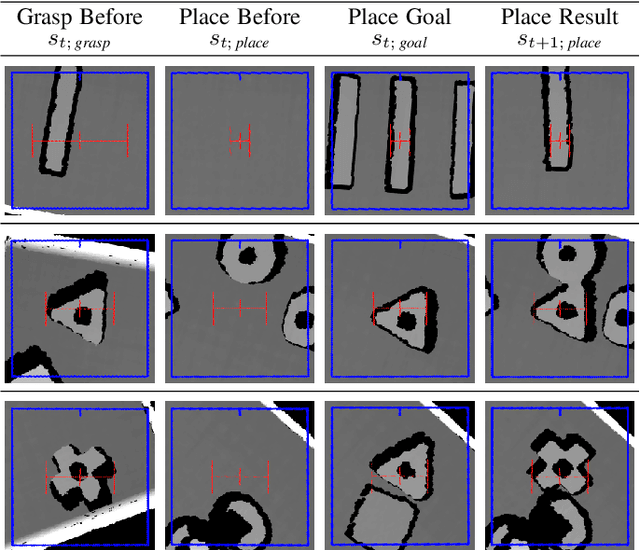
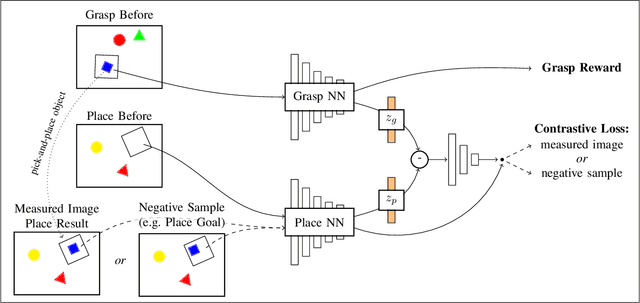

Flexible pick-and-place is a fundamental yet challenging task within robotics, in particular due to the need of an object model for a simple target pose definition. In this work, the robot instead learns to pick-and-place objects using planar manipulation according to a single, demonstrated goal state. Our primary contribution lies within combining robot learning of primitives, commonly estimated by fully-convolutional neural networks, with one-shot imitation learning. Therefore, we define the place reward as a contrastive loss between real-world measurements and a task-specific noise distribution. Furthermore, we design our system to learn in a self-supervised manner, enabling real-world experiments with up to 25000 pick-and-place actions. Then, our robot is able to place trained objects with an average placement error of 2.7 (0.2) mm and 2.6 (0.8){\deg}. As our approach does not require an object model, the robot is able to generalize to unknown objects while keeping a precision of 5.9 (1.1) mm and 4.1 (1.2){\deg}. We further show a range of emerging behaviors: The robot naturally learns to select the correct object in the presence of multiple object types, precisely inserts objects within a peg game, picks screws out of dense clutter, and infers multiple pick-and-place actions from a single goal state.
Robot Learning of Shifting Objects for Grasping in Cluttered Environments
Jul 25, 2019
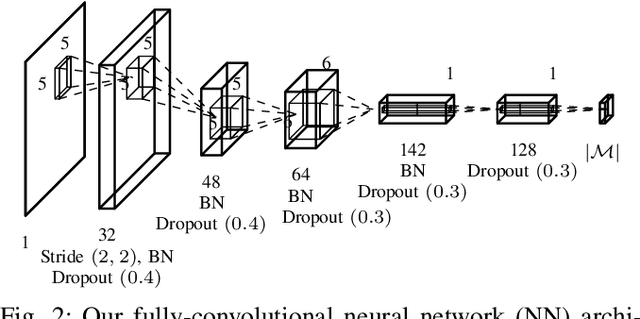
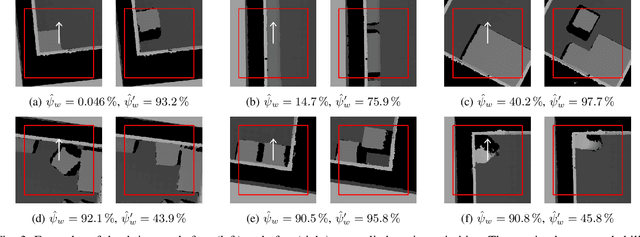
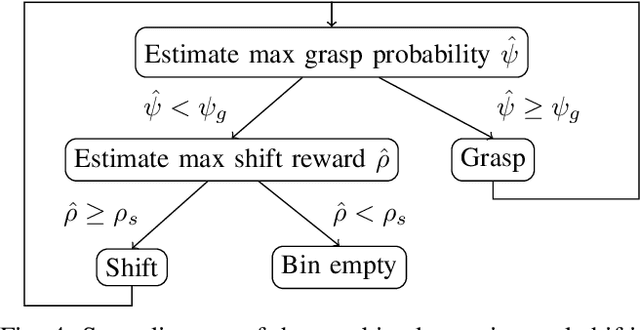
Robotic grasping in cluttered environments is often infeasible due to obstacles preventing possible grasps. Then, pre-grasping manipulation like shifting or pushing an object becomes necessary. We developed an algorithm that can learn, in addition to grasping, to shift objects in such a way that their grasp probability increases. Our research contribution is threefold: First, we present an algorithm for learning the optimal pose of manipulation primitives like clamping or shifting. Second, we learn non-prehensible actions that explicitly increase the grasping probability. Making one skill (shifting) directly dependent on another (grasping) removes the need of sparse rewards, leading to more data-efficient learning. Third, we apply a real-world solution to the industrial task of bin picking, resulting in the ability to empty bins completely. The system is trained in a self-supervised manner with around 25000 grasp and 2500 shift actions. Our robot is able to grasp and file objects with 274 picks per hour. Furthermore, we demonstrate the system's ability to generalize to novel objects.
Improving Data Efficiency of Self-supervised Learning for Robotic Grasping
Mar 01, 2019
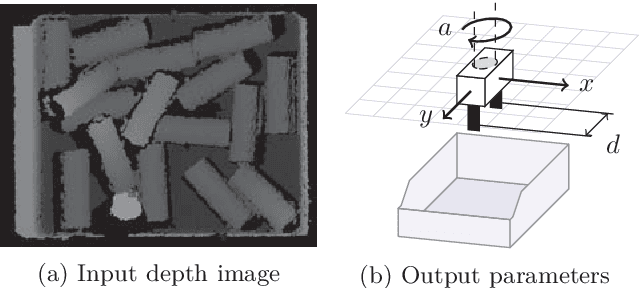
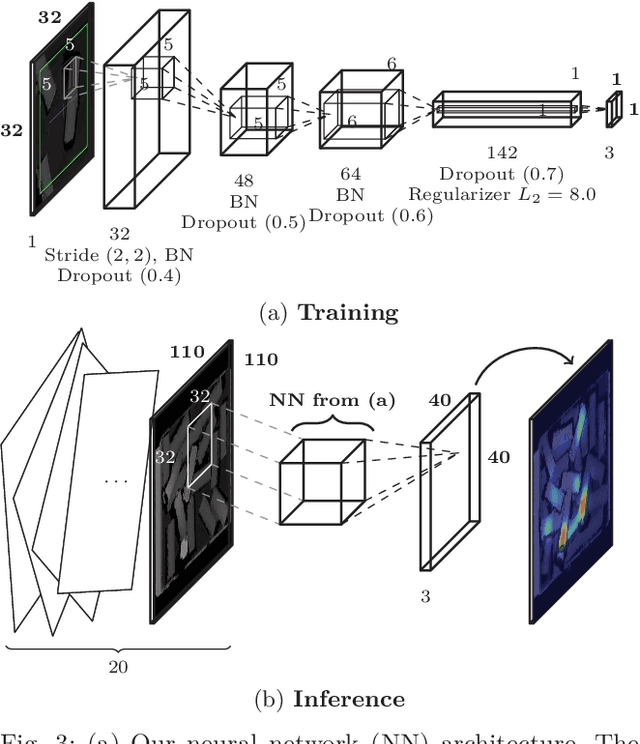

Given the task of learning robotic grasping solely based on a depth camera input and gripper force feedback, we derive a learning algorithm from an applied point of view to significantly reduce the amount of required training data. Major improvements in time and data efficiency are achieved by: Firstly, we exploit the geometric consistency between the undistorted depth images and the task space. Using a relative small, fully-convolutional neural network, we predict grasp and gripper parameters with great advantages in training as well as inference performance. Secondly, motivated by the small random grasp success rate of around 3%, the grasp space was explored in a systematic manner. The final system was learned with 23000 grasp attempts in around 60h, improving current solutions by an order of magnitude. For typical bin picking scenarios, we measured a grasp success rate of 96.6%. Further experiments showed that the system is able to generalize and transfer knowledge to novel objects and environments.