 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Performance Limits in Autonomous Racing: Continuous Stability-Aware Adaptive Velocity Planning in Formula Student Driverless
Jun 09, 2026In autonomous racing, especially in competitions such as Formula Student Driverless, precise planning of the target velocity of a race car is crucial for competitive lap times and stable driving behavior. Especially at high speeds, Velocity Planning (VP) is a significant challenge as it has to be performed in real time, taking into account track layouts, environmental influences, mechanical tolerances, and the resulting control inaccuracies. In this paper, we present a novel approach to VP that dynamically adapts to such changing conditions. Instead of estimating the physical Tire-Road Friction Coefficient (TRFC), a continuous scaling factor is inferred indirectly from vehicle stability. This factor not only reflects the effective tire-road interaction but also captures effects of control inaccuracies. From this, we generate a continuous friction map, which serves as a robust, adaptive basis for computing the optimal target speed, accounting for both vehicle and environmental limits. Our proposed approach was evaluated on a real Formula Student race car, showing a lap time improvement of 35 % over ten laps and an average increase of 8 % compared to a non-adaptive approach.
Vehicle Prediction Model for Enhanced MPC Path Tracking in Formula Student Driverless
Jun 09, 2026Autonomous race cars, such as in Formula Student Driverless, operate close to their physical handling limits. The resulting highly nonlinear vehicle behavior increases the path tracking complexity, especially on narrow tracks. Model Predictive Control (MPC) is commonly used to address this issue, a method whose performance is closely tied to the accuracy of the underlying prediction model. This paper presents a novel, real-time capable prediction model for autonomous race cars that adjusts to changing conditions by combining information from past runs and the current driving situation. Our model is divided into three consecutive submodels: a nominal Kinematic Bicycle Model, an offline Bayesian Linear Regression (BLR) model, and an online Sparse Gaussian Process Regression (SGPR) model. The proposed approach enables efficient integration of all available data without significantly increasing computational cost, ensuring high prediction accuracy and a quantitative uncertainty assessment right from the start of the run. Compared to existing approaches, an improvement in prediction accuracy of up to 57% was achieved. Further, we successfully demonstrated the practical applicability of the model within an MPC-based path tracking controller on a real Formula Student race car.
TD-TOG Dataset: Benchmarking Zero-Shot and One-Shot Task-Oriented Grasping for Object Generalization
Jun 05, 2025Task-oriented grasping (TOG) is an essential preliminary step for robotic task execution, which involves predicting grasps on regions of target objects that facilitate intended tasks. Existing literature reveals there is a limited availability of TOG datasets for training and benchmarking despite large demand, which are often synthetic or have artifacts in mask annotations that hinder model performance. Moreover, TOG solutions often require affordance masks, grasps, and object masks for training, however, existing datasets typically provide only a subset of these annotations. To address these limitations, we introduce the Top-down Task-oriented Grasping (TD-TOG) dataset, designed to train and evaluate TOG solutions. TD-TOG comprises 1,449 real-world RGB-D scenes including 30 object categories and 120 subcategories, with hand-annotated object masks, affordances, and planar rectangular grasps. It also features a test set for a novel challenge that assesses a TOG solution's ability to distinguish between object subcategories. To contribute to the demand for TOG solutions that can adapt and manipulate previously unseen objects without re-training, we propose a novel TOG framework, Binary-TOG. Binary-TOG uses zero-shot for object recognition, and one-shot learning for affordance recognition. Zero-shot learning enables Binary-TOG to identify objects in multi-object scenes through textual prompts, eliminating the need for visual references. In multi-object settings, Binary-TOG achieves an average task-oriented grasp accuracy of 68.9%. Lastly, this paper contributes a comparative analysis between one-shot and zero-shot learning for object generalization in TOG to be used in the development of future TOG solutions.
Implicit Shape Model Trees: Recognition of 3-D Indoor Scenes and Prediction of Object Poses for Mobile Robots
Jan 25, 2023



For a mobile robot, we present an approach to recognize scenes in arrangements of objects distributed over cluttered environments. Recognition is made possible by letting the robot alternately search for objects and assign found objects to scenes. Our scene model "Implicit Shape Model (ISM) trees" allows us to solve these two tasks together. For the ISM trees, this article presents novel algorithms for recognizing scenes and predicting the poses of searched objects. We define scenes as sets of objects, where some objects are connected by 3-D spatial relations. In previous work, we recognized scenes using single ISMs. However, these ISMs were prone to false positives. To address this problem, we introduced ISM trees, a hierarchical model that includes multiple ISMs. Through the recognition algorithm it contributes, this article ultimately enables the use of ISM trees in scene recognition. We intend to enable users to generate ISM trees from object arrangements demonstrated by humans. The lack of a suitable algorithm is overcome by the introduction of an ISM tree generation algorithm. In scene recognition, it is usually assumed that image data is already available. However, this is not always the case for robots. For this reason, we combined scene recognition and object search in previous work. However, we did not provide an efficient algorithm to link the two tasks. This article introduces such an algorithm that predicts the poses of searched objects with relations. Experiments show that our overall approach enables robots to find and recognize object arrangements that cannot be perceived from a single viewpoint.
Learning a Generative Transition Model for Uncertainty-Aware Robotic Manipulation
Jul 06, 2021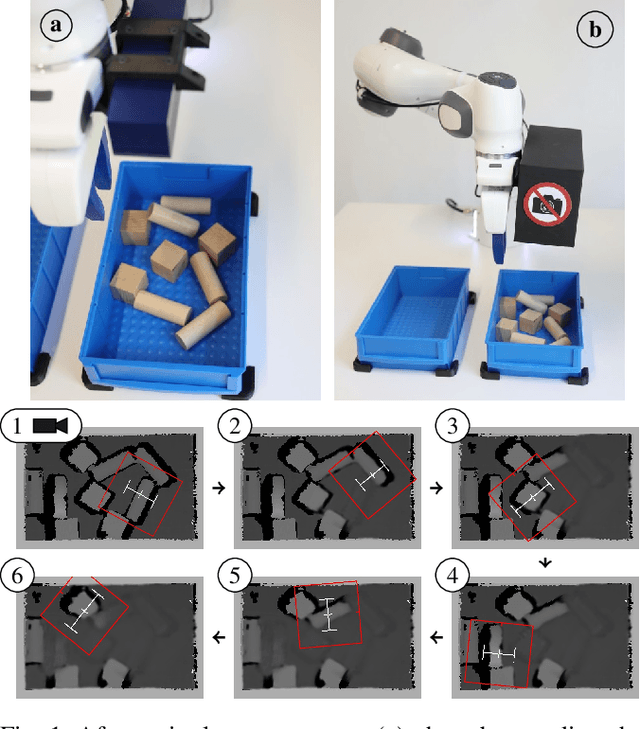
Robot learning of real-world manipulation tasks remains challenging and time consuming, even though actions are often simplified by single-step manipulation primitives. In order to compensate the removed time dependency, we additionally learn an image-to-image transition model that is able to predict a next state including its uncertainty. We apply this approach to bin picking, the task of emptying a bin using grasping as well as pre-grasping manipulation as fast as possible. The transition model is trained with up to 42000 pairs of real-world images before and after a manipulation action. Our approach enables two important skills: First, for applications with flange-mounted cameras, picks per hours (PPH) can be increased by around 15% by skipping image measurements. Second, we use the model to plan action sequences ahead of time and optimize time-dependent rewards, e.g. to minimize the number of actions required to empty the bin. We evaluate both improvements with real-robot experiments and achieve over 700 PPH in the YCB Box and Blocks Test.
Self-supervised Learning for Precise Pick-and-place without Object Model
Jun 15, 2020
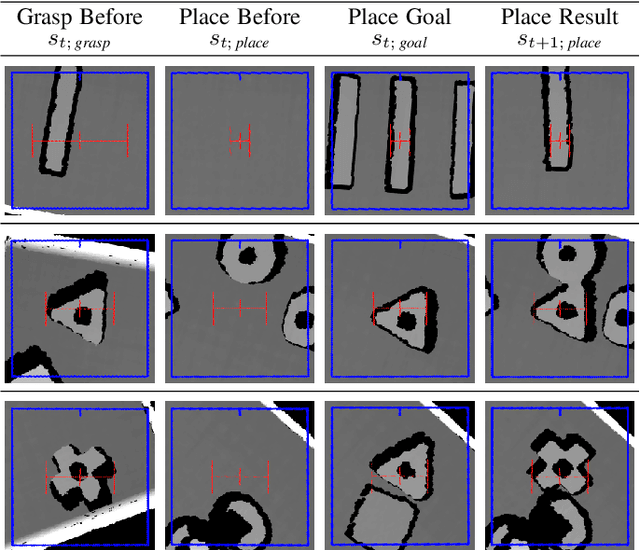
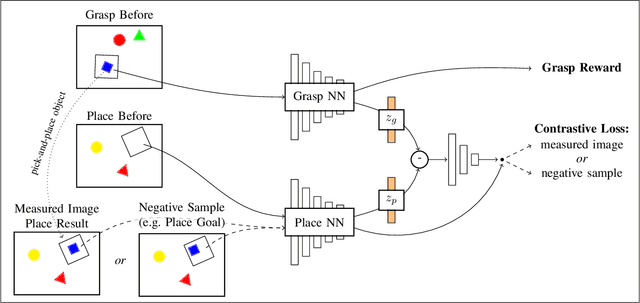

Flexible pick-and-place is a fundamental yet challenging task within robotics, in particular due to the need of an object model for a simple target pose definition. In this work, the robot instead learns to pick-and-place objects using planar manipulation according to a single, demonstrated goal state. Our primary contribution lies within combining robot learning of primitives, commonly estimated by fully-convolutional neural networks, with one-shot imitation learning. Therefore, we define the place reward as a contrastive loss between real-world measurements and a task-specific noise distribution. Furthermore, we design our system to learn in a self-supervised manner, enabling real-world experiments with up to 25000 pick-and-place actions. Then, our robot is able to place trained objects with an average placement error of 2.7 (0.2) mm and 2.6 (0.8){\deg}. As our approach does not require an object model, the robot is able to generalize to unknown objects while keeping a precision of 5.9 (1.1) mm and 4.1 (1.2){\deg}. We further show a range of emerging behaviors: The robot naturally learns to select the correct object in the presence of multiple object types, precisely inserts objects within a peg game, picks screws out of dense clutter, and infers multiple pick-and-place actions from a single goal state.
TrueRMA: Learning Fast and Smooth Robot Trajectories with Recursive Midpoint Adaptations in Cartesian Space
Jun 05, 2020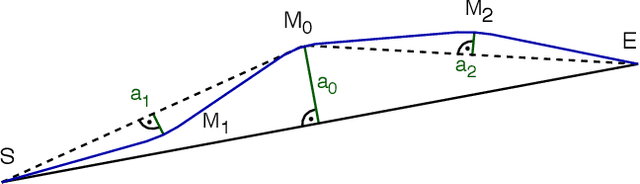
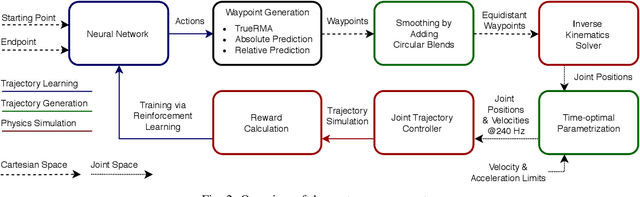
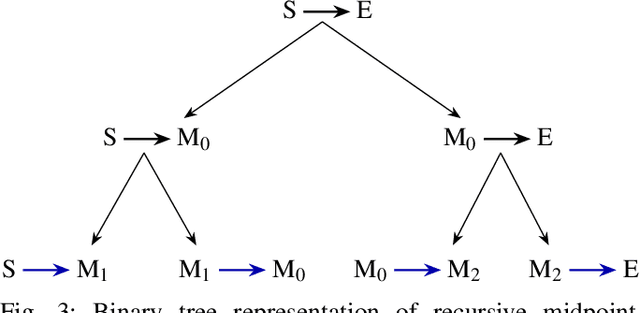
We present TrueRMA, a data-efficient, model-free method to learn cost-optimized robot trajectories over a wide range of starting points and endpoints. The key idea is to calculate trajectory waypoints in Cartesian space by recursively predicting orthogonal adaptations relative to the midpoints of straight lines. We generate a differentiable path by adding circular blends around the waypoints, calculate the corresponding joint positions with an inverse kinematics solver and calculate a time-optimal parameterization considering velocity and acceleration limits. During training, the trajectory is executed in a physics simulator and costs are assigned according to a user-specified cost function which is not required to be differentiable. Given a starting point and an endpoint as input, a neural network is trained to predict midpoint adaptations that minimize the cost of the resulting trajectory via reinforcement learning. We successfully train a KUKA iiwa robot to keep a ball on a plate while moving between specified points and compare the performance of TrueRMA against two baselines. The results show that our method requires less training data to learn the task while generating shorter and faster trajectories.
TrueAdapt: Learning Smooth Online Trajectory Adaptation with Bounded Jerk, Acceleration and Velocity in Joint Space
May 30, 2020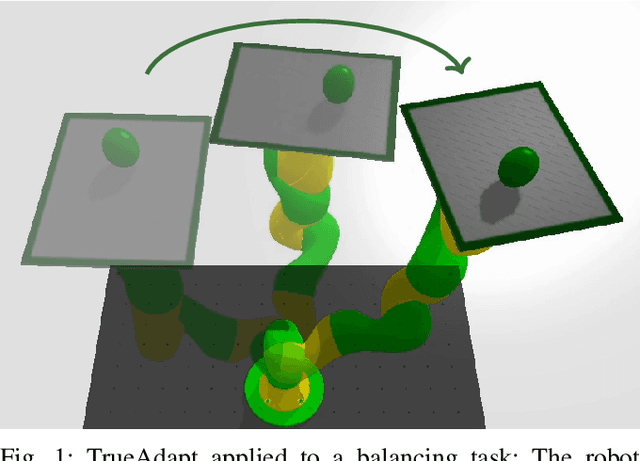
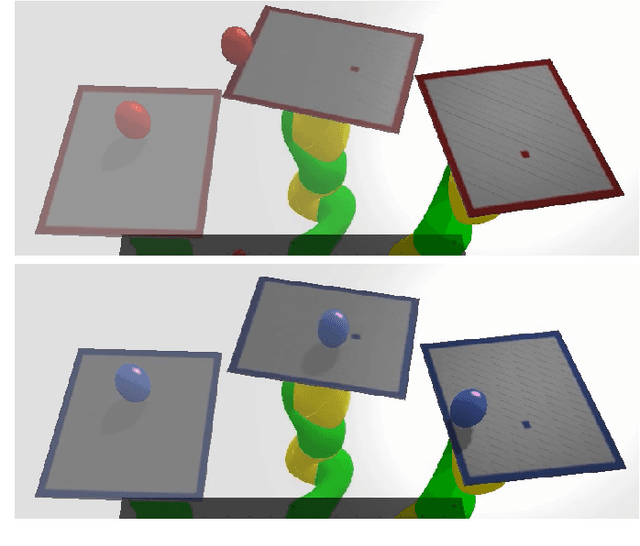
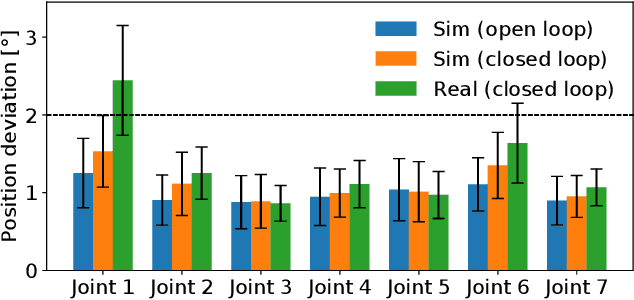
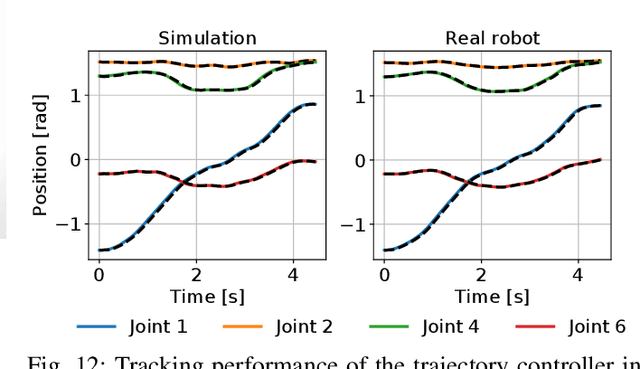
We present TrueAdapt, a model-free method to learn online adaptations of robot trajectories based on their effects on the environment. Given sensory feedback and future waypoints of the original trajectory, a neural network is trained to predict joint accelerations at regular intervals. The adapted trajectory is generated by linear interpolation of the predicted accelerations, leading to continuously differentiable joint velocities and positions. Bounded jerks, accelerations and velocities are guaranteed by calculating the valid acceleration range at each decision step and clipping the network's output accordingly. A deviation penalty during the training process causes the adapted trajectory to follow the original one. Smooth movements are encouraged by penalizing high accelerations and jerks. We evaluate our approach by training a simulated KUKA iiwa robot to balance a ball on a plate while moving and demonstrate that the balancing policy can be directly transferred to a real robot with little impact on performance.
Robot Learning of Shifting Objects for Grasping in Cluttered Environments
Jul 25, 2019
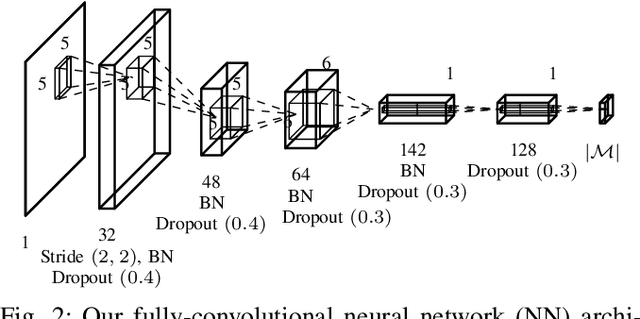
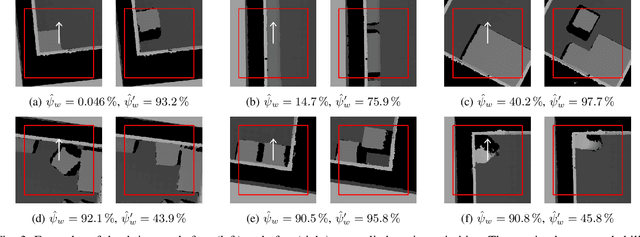
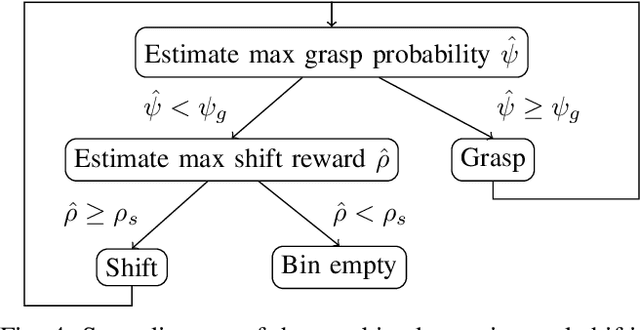
Robotic grasping in cluttered environments is often infeasible due to obstacles preventing possible grasps. Then, pre-grasping manipulation like shifting or pushing an object becomes necessary. We developed an algorithm that can learn, in addition to grasping, to shift objects in such a way that their grasp probability increases. Our research contribution is threefold: First, we present an algorithm for learning the optimal pose of manipulation primitives like clamping or shifting. Second, we learn non-prehensible actions that explicitly increase the grasping probability. Making one skill (shifting) directly dependent on another (grasping) removes the need of sparse rewards, leading to more data-efficient learning. Third, we apply a real-world solution to the industrial task of bin picking, resulting in the ability to empty bins completely. The system is trained in a self-supervised manner with around 25000 grasp and 2500 shift actions. Our robot is able to grasp and file objects with 274 picks per hour. Furthermore, we demonstrate the system's ability to generalize to novel objects.