 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sparse Adversarial Dictionaries For Multi-Class Audio Classification
Paper and Code
Dec 02, 2017

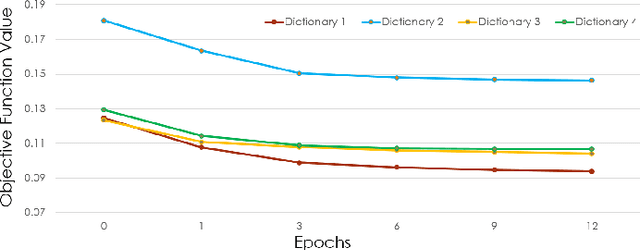

Audio events are quite often overlapping in nature, and more prone to noise than visual signals. There has been increasing evidence for the superior performance of representations learned using sparse dictionaries for applications like audio denoising and speech enhancement. This paper concentrates on modifying the traditional reconstructive dictionary learning algorithms, by incorporating a discriminative term into the objective function in order to learn class-specific adversarial dictionaries that are good at representing samples of their own class at the same time poor at representing samples belonging to any other class. We quantitatively demonstrate the effectiveness of our learned dictionaries as a stand-alone solution for both binary as well as multi-class audio classification problems.