 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Theoretic Trust Regions for Stochastic Gradient-Based Optimization
Oct 31, 2023



Stochastic gradient-based optimization is crucial to optimize neural networks. While popular approaches heuristically adapt the step size and direction by rescaling gradients, a more principled approach to improve optimizers requires second-order information. Such methods precondition the gradient using the objective's Hessian. Yet, computing the Hessian is usually expensive and effectively using second-order information in the stochastic gradient setting is non-trivial. We propose using Information-Theoretic Trust Region Optimization (arTuRO) for improved updates with uncertain second-order information. By modeling the network parameters as a Gaussian distribution and using a Kullback-Leibler divergence-based trust region, our approach takes bounded steps accounting for the objective's curvature and uncertainty in the parameters. Before each update, it solves the trust region problem for an optimal step size, resulting in a more stable and faster optimization process. We approximate the diagonal elements of the Hessian from stochastic gradients using a simple recursive least squares approach, constructing a model of the expected Hessian over time using only first-order information. We show that arTuRO combines the fast convergence of adaptive moment-based optimization with the generalization capabilities of SGD.
Deep Reinforcement Learning for Swarm Systems
Oct 15, 2018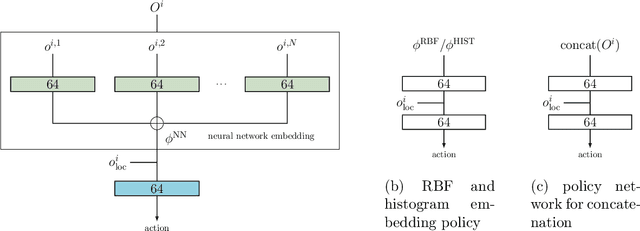
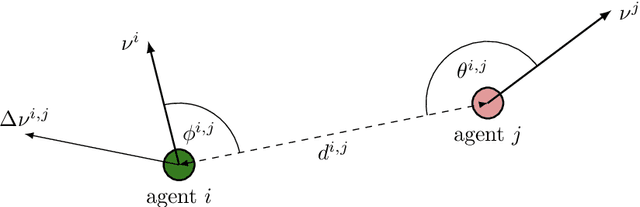
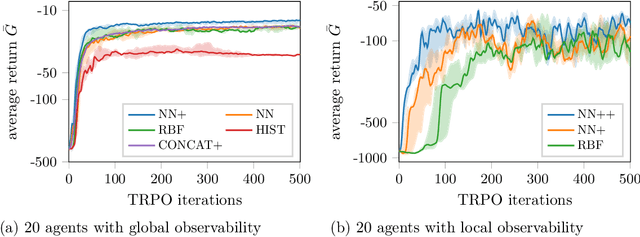
Recently, deep reinforcement learning (RL) methods have been applied successfully to multi-agent scenarios. Typically, these methods rely on a concatenation of agent states to represent the information content required for decentralized decision making. However, concatenation scales poorly to swarm systems with a large number of homogeneous agents as it does not exploit the fundamental properties inherent to these systems: (i) the agents in the swarm are interchangeable and (ii) the exact number of agents in the swarm is irrelevant. Therefore, we propose a new state representation for deep multi-agent RL based on mean embeddings of distributions. We treat the agents as samples of a distribution and use the empirical mean embedding as input for a decentralized policy. We define different feature spaces of the mean embedding using histograms, radial basis functions and a neural network learned end-to-end. We evaluate the representation on two well known problems from the swarm literature (rendezvous and pursuit evasion), in a globally and locally observable setup. For the local setup we furthermore introduce simple communication protocols. Of all approaches, the mean embedding representation using neural network features enables the richest information exchange between neighboring agents facilitating the development of more complex collective strategies.
Local Communication Protocols for Learning Complex Swarm Behaviors with Deep Reinforcement Learning
Jul 18, 2018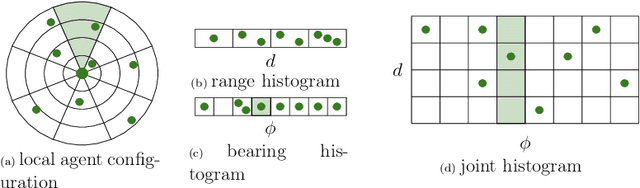
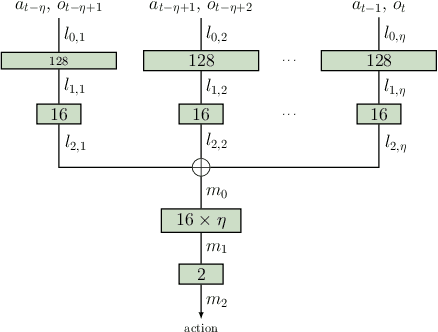
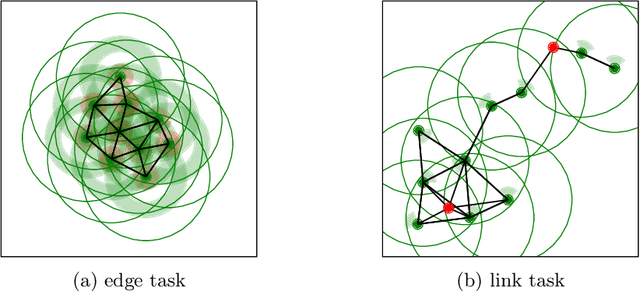
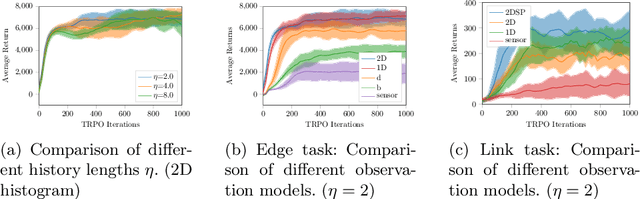
Swarm systems constitute a challenging problem for reinforcement learning (RL) as the algorithm needs to learn decentralized control policies that can cope with limited local sensing and communication abilities of the agents. While it is often difficult to directly define the behavior of the agents, simple communication protocols can be defined more easily using prior knowledge about the given task. In this paper, we propose a number of simple communication protocols that can be exploited by deep reinforcement learning to find decentralized control policies in a multi-robot swarm environment. The protocols are based on histograms that encode the local neighborhood relations of the agents and can also transmit task-specific information, such as the shortest distance and direction to a desired target. In our framework, we use an adaptation of Trust Region Policy Optimization to learn complex collaborative tasks, such as formation building and building a communication link. We evaluate our findings in a simulated 2D-physics environment, and compare the implications of different communication protocols.
Guided Deep Reinforcement Learning for Swarm Systems
Sep 18, 2017
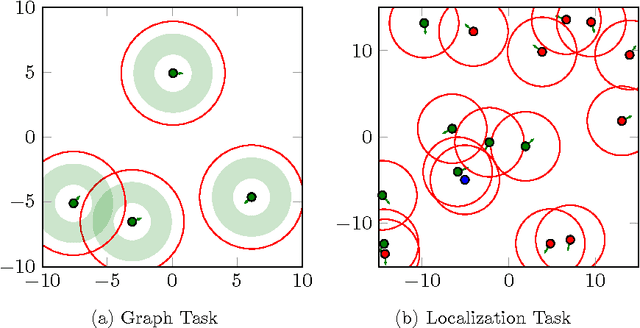
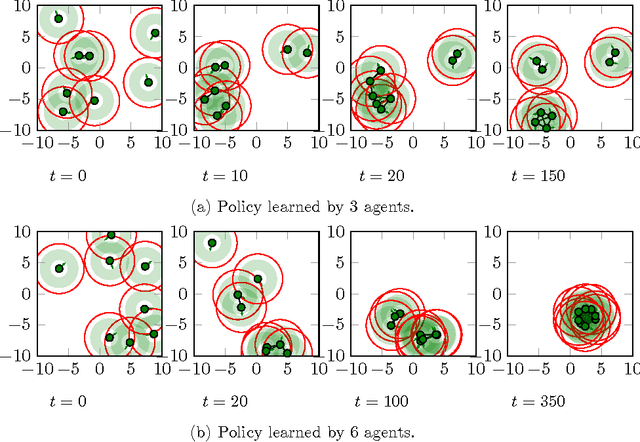
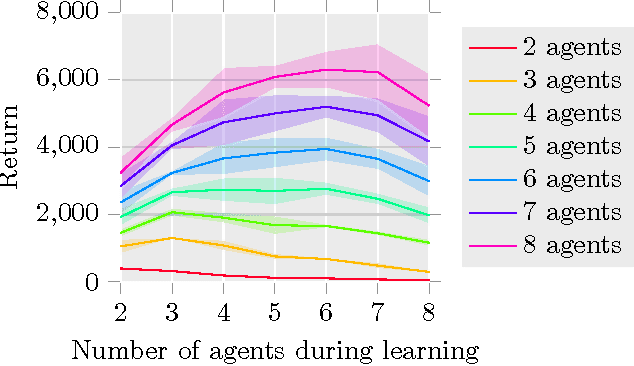
In this paper, we investigate how to learn to control a group of cooperative agents with limited sensing capabilities such as robot swarms. The agents have only very basic sensor capabilities, yet in a group they can accomplish sophisticated tasks, such as distributed assembly or search and rescue tasks. Learning a policy for a group of agents is difficult due to distributed partial observability of the state. Here, we follow a guided approach where a critic has central access to the global state during learning, which simplifies the policy evaluation problem from a reinforcement learning point of view. For example, we can get the positions of all robots of the swarm using a camera image of a scene. This camera image is only available to the critic and not to the control policies of the robots. We follow an actor-critic approach, where the actors base their decisions only on locally sensed information. In contrast, the critic is learned based on the true global state. Our algorithm uses deep reinforcement learning to approximate both the Q-function and the policy. The performance of the algorithm is evaluated on two tasks with simple simulated 2D agents: 1) finding and maintaining a certain distance to each others and 2) locating a target.