 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Swarm Systems
Paper and Code
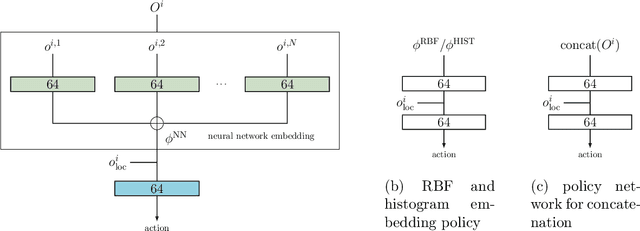
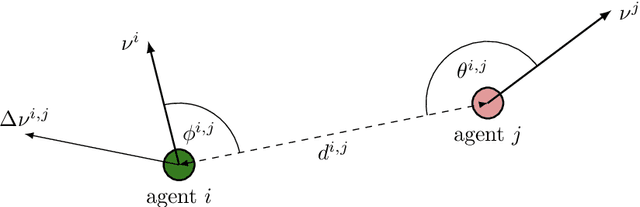
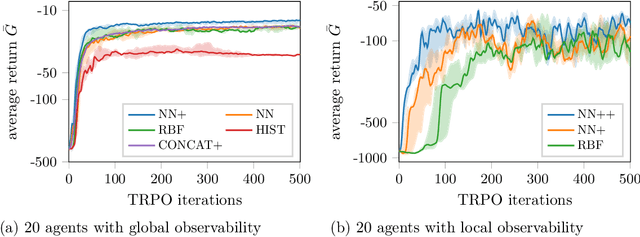
Recently, deep reinforcement learning (RL) methods have been applied successfully to multi-agent scenarios. Typically, these methods rely on a concatenation of agent states to represent the information content required for decentralized decision making. However, concatenation scales poorly to swarm systems with a large number of homogeneous agents as it does not exploit the fundamental properties inherent to these systems: (i) the agents in the swarm are interchangeable and (ii) the exact number of agents in the swarm is irrelevant. Therefore, we propose a new state representation for deep multi-agent RL based on mean embeddings of distributions. We treat the agents as samples of a distribution and use the empirical mean embedding as input for a decentralized policy. We define different feature spaces of the mean embedding using histograms, radial basis functions and a neural network learned end-to-end. We evaluate the representation on two well known problems from the swarm literature (rendezvous and pursuit evasion), in a globally and locally observable setup. For the local setup we furthermore introduce simple communication protocols. Of all approaches, the mean embedding representation using neural network features enables the richest information exchange between neighboring agents facilitating the development of more complex collective strategies.