 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelation Priors for Reinforcement Learning
Sep 11, 2019
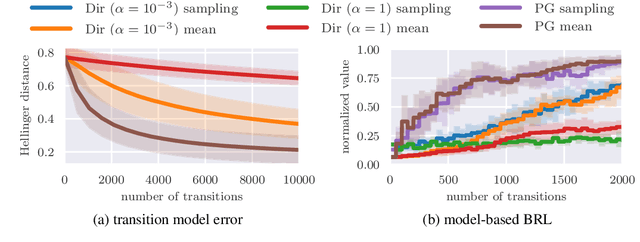
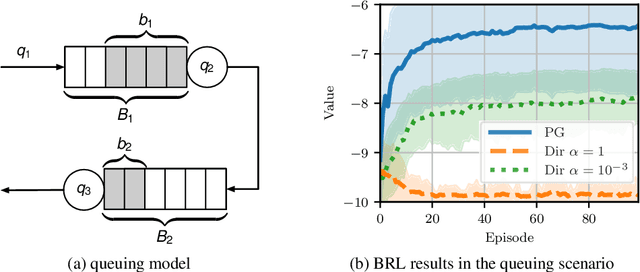
Many decision-making problems naturally exhibit pronounced structures inherited from the underlying characteristics of the environment. In a Markov decision process model, for example, two distinct states can have inherently related semantics or encode resembling physical state configurations, often implying locally correlated transition dynamics among the states. In order to complete a certain task, an agent acting in such environments needs to execute a series of temporally and spatially correlated actions. Though there exists a variety of approaches to account for correlations in continuous state-action domains, a principled solution for discrete environments is missing. In this work, we present a Bayesian learning framework based on P\'olya-Gamma augmentation that enables an analogous reasoning in such cases. We demonstrate the framework on a number of common decision-making related tasks, such as reinforcement learning, imitation learning and system identification. By explicitly modeling the underlying correlation structures, the proposed approach yields superior predictive performance compared to correlation-agnostic models, even when trained on data sets that are up to an order of magnitude smaller in size.
Inverse Reinforcement Learning via Nonparametric Spatio-Temporal Subgoal Modeling
Nov 30, 2018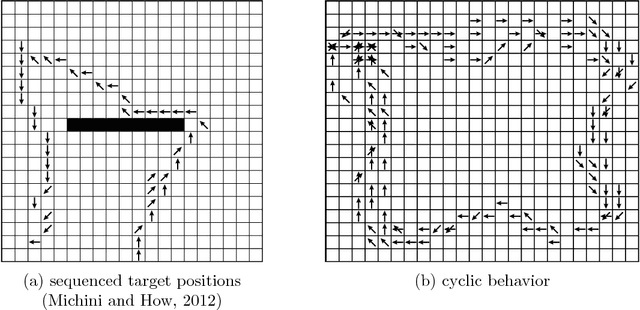


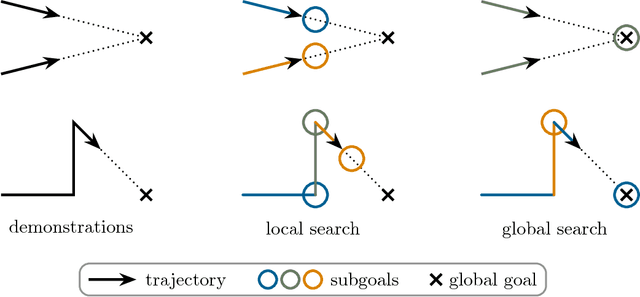
Advances in the field of inverse reinforcement learning (IRL) have led to sophisticated inference frameworks that relax the original modeling assumption of observing an agent behavior that reflects only a single intention. Instead of learning a global behavioral model, recent IRL methods divide the demonstration data into parts, to account for the fact that different trajectories may correspond to different intentions, e.g., because they were generated by different domain experts. In this work, we go one step further: using the intuitive concept of subgoals, we build upon the premise that even a single trajectory can be explained more efficiently locally within a certain context than globally, enabling a more compact representation of the observed behavior. Based on this assumption, we build an implicit intentional model of the agent's goals to forecast its behavior in unobserved situations. The result is an integrated Bayesian prediction framework that significantly outperforms existing IRL solutions and provides smooth policy estimates consistent with the expert's plan. Most notably, our framework naturally handles situations where the intentions of the agent change over time and classical IRL algorithms fail. In addition, due to its probabilistic nature, the model can be straightforwardly applied in active learning scenarios to guide the demonstration process of the expert.
Deep Reinforcement Learning for Swarm Systems
Oct 15, 2018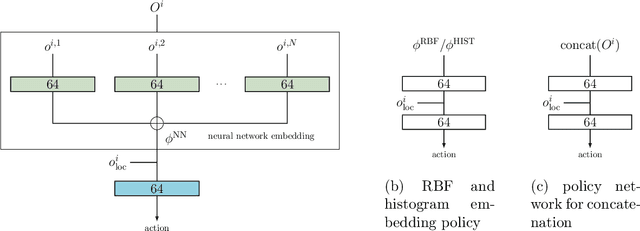
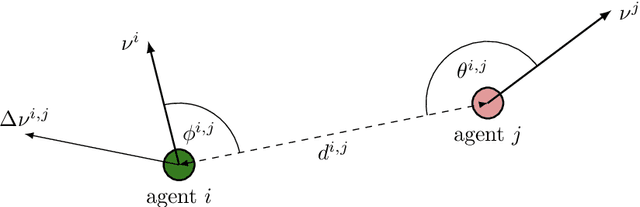
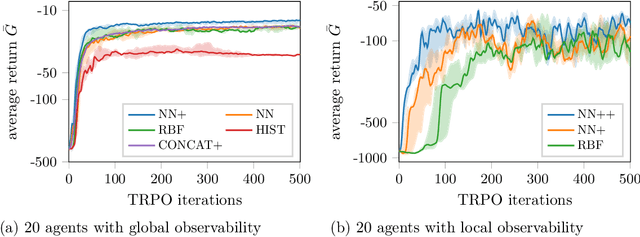
Recently, deep reinforcement learning (RL) methods have been applied successfully to multi-agent scenarios. Typically, these methods rely on a concatenation of agent states to represent the information content required for decentralized decision making. However, concatenation scales poorly to swarm systems with a large number of homogeneous agents as it does not exploit the fundamental properties inherent to these systems: (i) the agents in the swarm are interchangeable and (ii) the exact number of agents in the swarm is irrelevant. Therefore, we propose a new state representation for deep multi-agent RL based on mean embeddings of distributions. We treat the agents as samples of a distribution and use the empirical mean embedding as input for a decentralized policy. We define different feature spaces of the mean embedding using histograms, radial basis functions and a neural network learned end-to-end. We evaluate the representation on two well known problems from the swarm literature (rendezvous and pursuit evasion), in a globally and locally observable setup. For the local setup we furthermore introduce simple communication protocols. Of all approaches, the mean embedding representation using neural network features enables the richest information exchange between neighboring agents facilitating the development of more complex collective strategies.
Local Communication Protocols for Learning Complex Swarm Behaviors with Deep Reinforcement Learning
Jul 18, 2018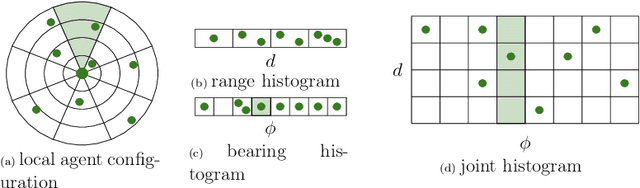
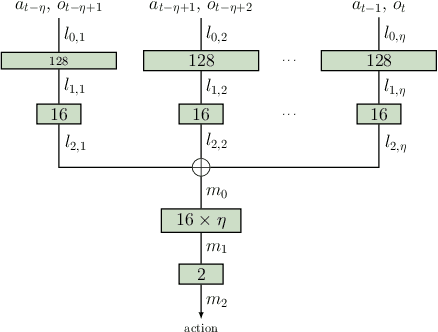
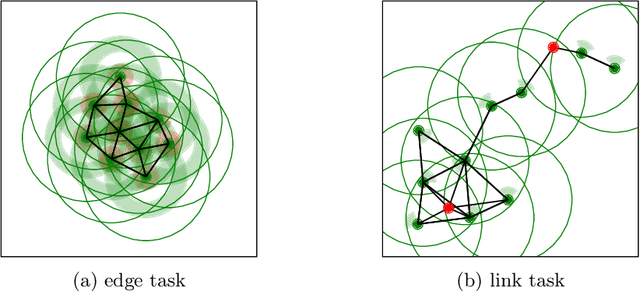
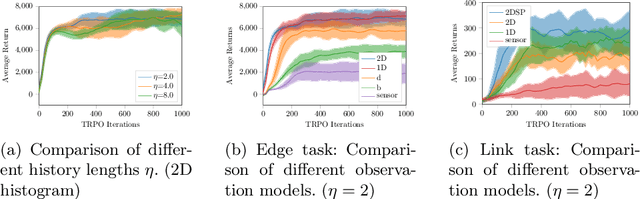
Swarm systems constitute a challenging problem for reinforcement learning (RL) as the algorithm needs to learn decentralized control policies that can cope with limited local sensing and communication abilities of the agents. While it is often difficult to directly define the behavior of the agents, simple communication protocols can be defined more easily using prior knowledge about the given task. In this paper, we propose a number of simple communication protocols that can be exploited by deep reinforcement learning to find decentralized control policies in a multi-robot swarm environment. The protocols are based on histograms that encode the local neighborhood relations of the agents and can also transmit task-specific information, such as the shortest distance and direction to a desired target. In our framework, we use an adaptation of Trust Region Policy Optimization to learn complex collaborative tasks, such as formation building and building a communication link. We evaluate our findings in a simulated 2D-physics environment, and compare the implications of different communication protocols.
Guided Deep Reinforcement Learning for Swarm Systems
Sep 18, 2017
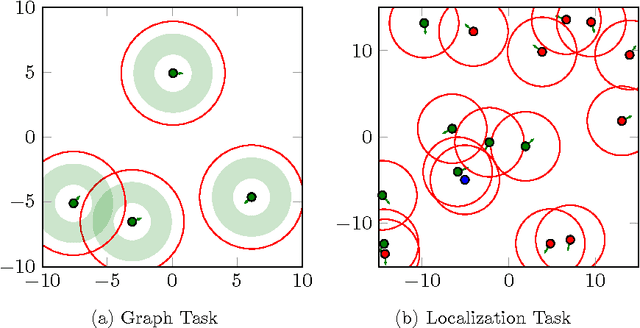
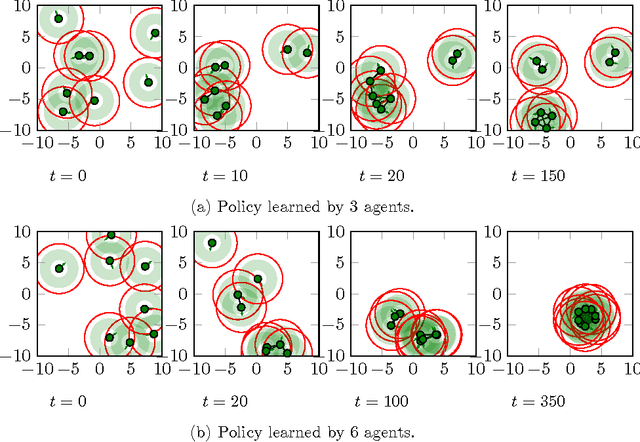
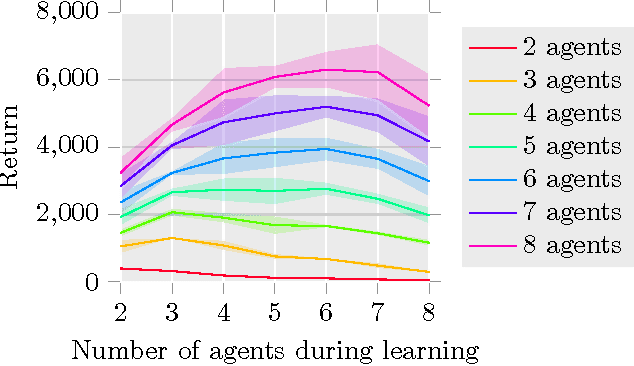
In this paper, we investigate how to learn to control a group of cooperative agents with limited sensing capabilities such as robot swarms. The agents have only very basic sensor capabilities, yet in a group they can accomplish sophisticated tasks, such as distributed assembly or search and rescue tasks. Learning a policy for a group of agents is difficult due to distributed partial observability of the state. Here, we follow a guided approach where a critic has central access to the global state during learning, which simplifies the policy evaluation problem from a reinforcement learning point of view. For example, we can get the positions of all robots of the swarm using a camera image of a scene. This camera image is only available to the critic and not to the control policies of the robots. We follow an actor-critic approach, where the actors base their decisions only on locally sensed information. In contrast, the critic is learned based on the true global state. Our algorithm uses deep reinforcement learning to approximate both the Q-function and the policy. The performance of the algorithm is evaluated on two tasks with simple simulated 2D agents: 1) finding and maintaining a certain distance to each others and 2) locating a target.
A Bayesian Approach to Policy Recognition and State Representation Learning
Aug 04, 2017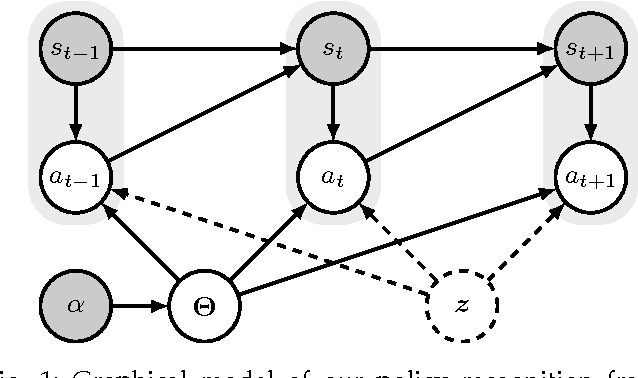

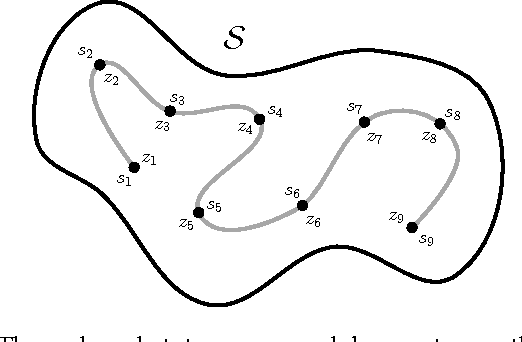
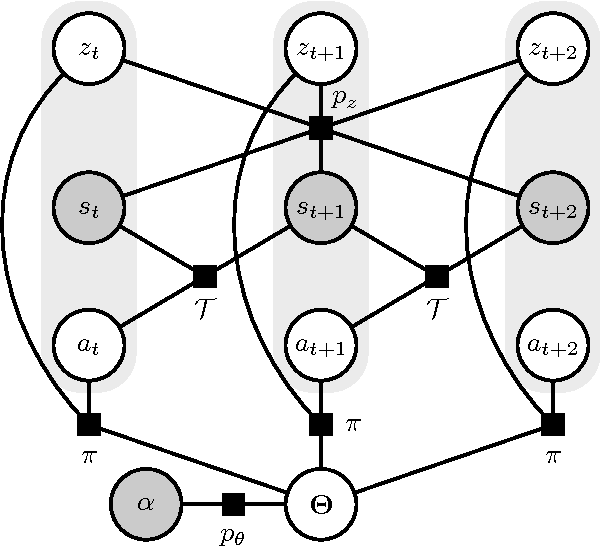
Learning from demonstration (LfD) is the process of building behavioral models of a task from demonstrations provided by an expert. These models can be used e.g. for system control by generalizing the expert demonstrations to previously unencountered situations. Most LfD methods, however, make strong assumptions about the expert behavior, e.g. they assume the existence of a deterministic optimal ground truth policy or require direct monitoring of the expert's controls, which limits their practical use as part of a general system identification framework. In this work, we consider the LfD problem in a more general setting where we allow for arbitrary stochastic expert policies, without reasoning about the optimality of the demonstrations. Following a Bayesian methodology, we model the full posterior distribution of possible expert controllers that explain the provided demonstration data. Moreover, we show that our methodology can be applied in a nonparametric context to infer the complexity of the state representation used by the expert, and to learn task-appropriate partitionings of the system state space.
Inverse Reinforcement Learning in Swarm Systems
Mar 24, 2017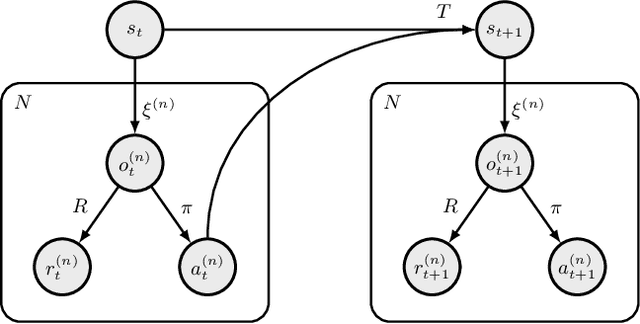


Inverse reinforcement learning (IRL) has become a useful tool for learning behavioral models from demonstration data. However, IRL remains mostly unexplored for multi-agent systems. In this paper, we show how the principle of IRL can be extended to homogeneous large-scale problems, inspired by the collective swarming behavior of natural systems. In particular, we make the following contributions to the field: 1) We introduce the swarMDP framework, a sub-class of decentralized partially observable Markov decision processes endowed with a swarm characterization. 2) Exploiting the inherent homogeneity of this framework, we reduce the resulting multi-agent IRL problem to a single-agent one by proving that the agent-specific value functions in this model coincide. 3) To solve the corresponding control problem, we propose a novel heterogeneous learning scheme that is particularly tailored to the swarm setting. Results on two example systems demonstrate that our framework is able to produce meaningful local reward models from which we can replicate the observed global system dynamics.