 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteelDS: A High-Resolution Video Dataset of E40 Steel Scrap for Object Detection and Instance Segmentation
May 26, 2026This dataset provides high-resolution, annotated video sequences of shredded E40-grade steel and copper scrap on a conveyor belt. Captured in a controlled laboratory environment, the data reflects the industrial post-magnetic sorting stage, where manual intervention is typically required to remove copper contaminants. The dataset comprises 24,297 labeled frames across five subsets, featuring 396 steel and 101 copper objects categorized by size. It supports the development of machine learning models for material classification, object detection, and instance segmentation. Variations in object spacing and density are included to simulate realistic industrial sorting conditions. Ground truth annotations include pixel-wise segmentation masks and material classes. This dataset serves as a benchmark for evaluating automated sorting algorithms aiming to identify copper impurities within complex, heterogeneous steel scrap streams.
PASTA: Vision Transformer Patch Aggregation for Weakly Supervised Target and Anomaly Segmentation
Apr 07, 2026Detecting unseen anomalies in unstructured environments presents a critical challenge for industrial and agricultural applications such as material recycling and weeding. Existing perception systems frequently fail to satisfy the strict operational requirements of these domains, specifically real-time processing, pixel-level segmentation precision, and robust accuracy, due to their reliance on exhaustively annotated datasets. To address these limitations, we propose a weakly supervised pipeline for object segmentation and classification using weak image-level supervision called 'Patch Aggregation for Segmentation of Targets and Anomalies' (PASTA). By comparing an observed scene with a nominal reference, PASTA identifies Target and Anomaly objects through distribution analysis in self-supervised Vision Transformer (ViT) feature spaces. Our pipeline utilizes semantic text-prompts via the Segment Anything Model 3 to guide zero-shot object segmentation. Evaluations on a custom steel scrap recycling dataset and a plant dataset demonstrate a 75.8% training time reduction of our approach to domain-specific baselines. While being domain-agnostic, our method achieves superior Target (up to 88.3% IoU) and Anomaly (up to 63.5% IoU) segmentation performance in the industrial and agricultural domain.
Beyond Master and Apprentice: Grounding Foundation Models for Symbiotic Interactive Learning in a Shared Latent Space
Nov 07, 2025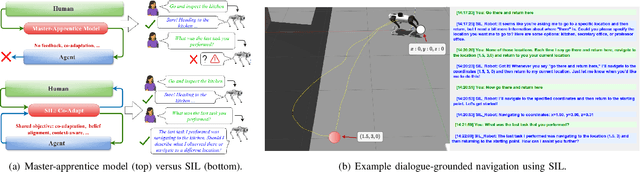
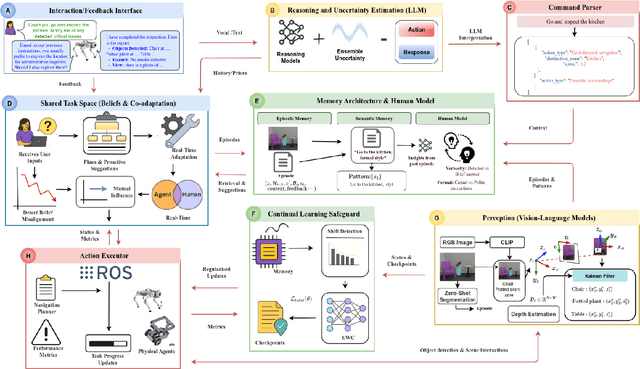
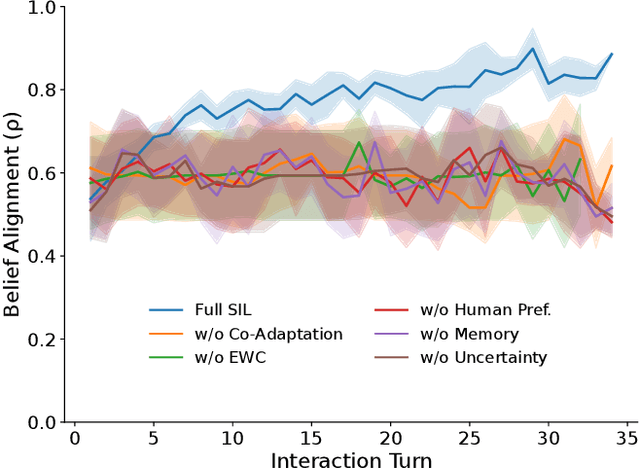
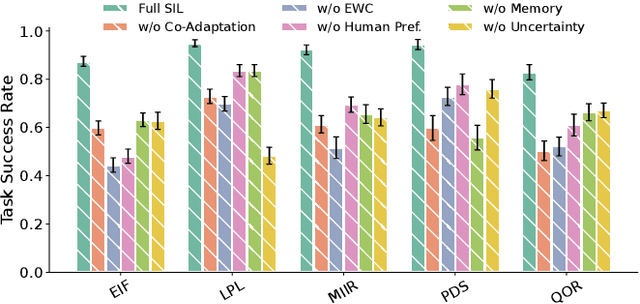
Today's autonomous agents can understand free-form natural language instructions and execute long-horizon tasks in a manner akin to human-level reasoning. These capabilities are mostly driven by large-scale pre-trained foundation models (FMs). However, the approaches with which these models are grounded for human-robot interaction (HRI) perpetuate a master-apprentice model, where the apprentice (embodied agent) passively receives and executes the master's (human's) commands without reciprocal learning. This reactive interaction approach does not capture the co-adaptive dynamics inherent in everyday multi-turn human-human interactions. To address this, we propose a Symbiotic Interactive Learning (SIL) approach that enables both the master and the apprentice to co-adapt through mutual, bidirectional interactions. We formalised SIL as a co-adaptation process within a shared latent task space, where the agent and human maintain joint belief states that evolve based on interaction history. This enables the agent to move beyond reactive execution to proactive clarification, adaptive suggestions, and shared plan refinement. To realise these novel behaviours, we leveraged pre-trained FMs for spatial perception and reasoning, alongside a lightweight latent encoder that grounds the models' outputs into task-specific representations. Furthermore, to ensure stability as the tasks evolve, we augment SIL with a memory architecture that prevents the forgetting of learned task-space representations. We validate SIL on both simulated and real-world embodied tasks, including instruction following, information retrieval, query-oriented reasoning, and interactive dialogues. Demos and resources are public at:~\href{https://linusnep.github.io/SIL/}{https://linusnep.github.io/SIL/}.
Real-Time 3D Vision-Language Embedding Mapping
Aug 08, 2025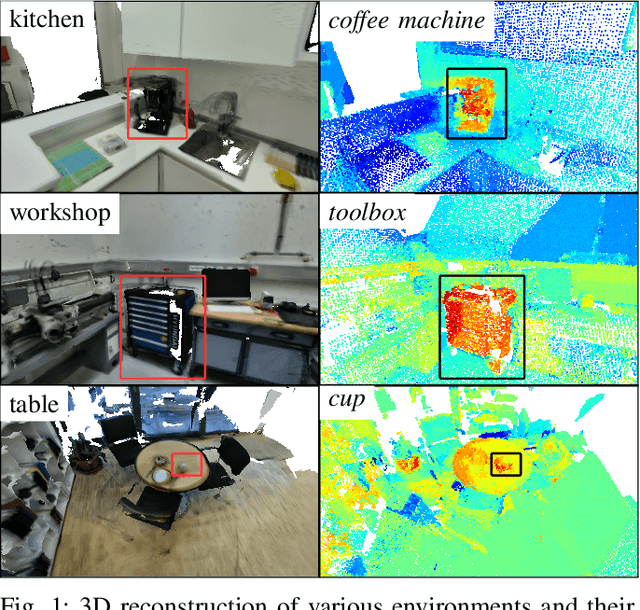
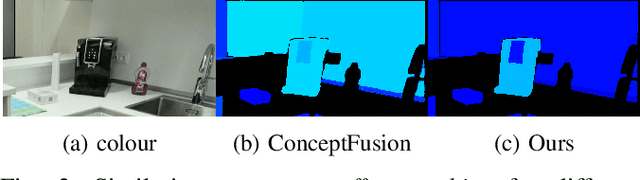


A metric-accurate semantic 3D representation is essential for many robotic tasks. This work proposes a simple, yet powerful, way to integrate the 2D embeddings of a Vision-Language Model in a metric-accurate 3D representation at real-time. We combine a local embedding masking strategy, for a more distinct embedding distribution, with a confidence-weighted 3D integration for more reliable 3D embeddings. The resulting metric-accurate embedding representation is task-agnostic and can represent semantic concepts on a global multi-room, as well as on a local object-level. This enables a variety of interactive robotic applications that require the localisation of objects-of-interest via natural language. We evaluate our approach on a variety of real-world sequences and demonstrate that these strategies achieve a more accurate object-of-interest localisation while improving the runtime performance in order to meet our real-time constraints. We further demonstrate the versatility of our approach in a variety of interactive handheld, mobile robotics and manipulation tasks, requiring only raw image data.
Privacy-Aware Lifelong Learning
May 16, 2025

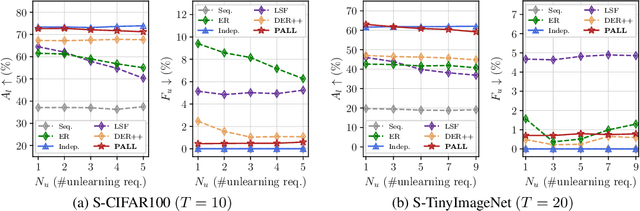

Lifelong learning algorithms enable models to incrementally acquire new knowledge without forgetting previously learned information. Contrarily, the field of machine unlearning focuses on explicitly forgetting certain previous knowledge from pretrained models when requested, in order to comply with data privacy regulations on the right-to-be-forgotten. Enabling efficient lifelong learning with the capability to selectively unlearn sensitive information from models presents a critical and largely unaddressed challenge with contradicting objectives. We address this problem from the perspective of simultaneously preventing catastrophic forgetting and allowing forward knowledge transfer during task-incremental learning, while ensuring exact task unlearning and minimizing memory requirements, based on a single neural network model to be adapted. Our proposed solution, privacy-aware lifelong learning (PALL), involves optimization of task-specific sparse subnetworks with parameter sharing within a single architecture. We additionally utilize an episodic memory rehearsal mechanism to facilitate exact unlearning without performance degradations. We empirically demonstrate the scalability of PALL across various architectures in image classification, and provide a state-of-the-art solution that uniquely integrates lifelong learning and privacy-aware unlearning mechanisms for responsible AI applications.
ReLI: A Language-Agnostic Approach to Human-Robot Interaction
May 03, 2025



Adapting autonomous agents to industrial, domestic, and other daily tasks is currently gaining momentum. However, in the global or cross-lingual application contexts, ensuring effective interaction with the environment and executing unrestricted human task-specified instructions in diverse languages remains an unsolved problem. To address this challenge, we propose ReLI, a language-agnostic framework designed to enable autonomous agents to converse naturally, semantically reason about the environment, and to perform downstream tasks, regardless of the task instruction's linguistic origin. First, we ground large-scale pre-trained foundation models and transform them into language-to-action models that can directly provide common-sense reasoning and high-level robot control through natural, free-flow human-robot conversational interactions. Further, we perform cross-lingual grounding of the models to ensure that ReLI generalises across the global languages. To demonstrate the ReLI's robustness, we conducted extensive simulated and real-world experiments on various short- and long-horizon tasks, including zero-shot and few-shot spatial navigation, scene information retrieval, and query-oriented tasks. We benchmarked the performance on 140 languages involving over 70K multi-turn conversations. On average, ReLI achieved over 90%$\pm$0.2 accuracy in cross-lingual instruction parsing and task execution success rates. These results demonstrate the ReLI's potential to enhance natural human-robot interaction in the real world while championing linguistic diversity. Demonstrations and resources will be publicly available at https://linusnep.github.io/ReLI/.
EnvoDat: A Large-Scale Multisensory Dataset for Robotic Spatial Awareness and Semantic Reasoning in Heterogeneous Environments
Oct 29, 2024
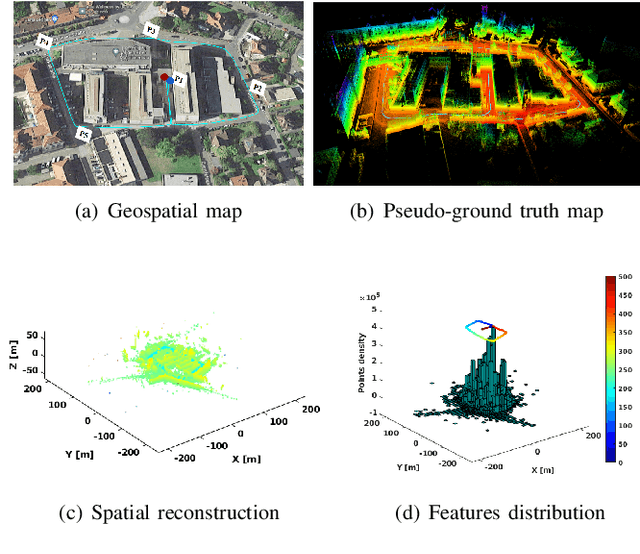
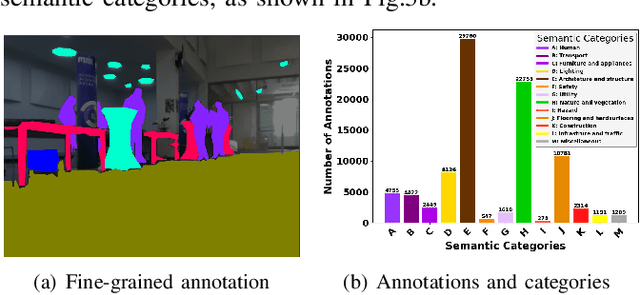
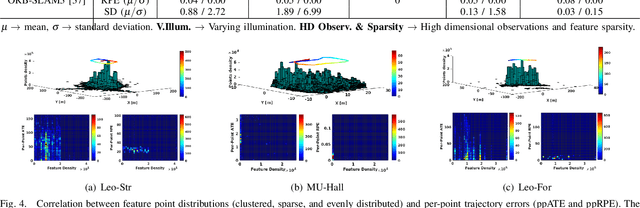
To ensure the efficiency of robot autonomy under diverse real-world conditions, a high-quality heterogeneous dataset is essential to benchmark the operating algorithms' performance and robustness. Current benchmarks predominantly focus on urban terrains, specifically for on-road autonomous driving, leaving multi-degraded, densely vegetated, dynamic and feature-sparse environments, such as underground tunnels, natural fields, and modern indoor spaces underrepresented. To fill this gap, we introduce EnvoDat, a large-scale, multi-modal dataset collected in diverse environments and conditions, including high illumination, fog, rain, and zero visibility at different times of the day. Overall, EnvoDat contains 26 sequences from 13 scenes, 10 sensing modalities, over 1.9TB of data, and over 89K fine-grained polygon-based annotations for more than 82 object and terrain classes. We post-processed EnvoDat in different formats that support benchmarking SLAM and supervised learning algorithms, and fine-tuning multimodal vision models. With EnvoDat, we contribute to environment-resilient robotic autonomy in areas where the conditions are extremely challenging. The datasets and other relevant resources can be accessed through https://linusnep.github.io/EnvoDat/.
ED-VAE: Entropy Decomposition of ELBO in Variational Autoencoders
Jul 09, 2024


Traditional Variational Autoencoders (VAEs) are constrained by the limitations of the Evidence Lower Bound (ELBO) formulation, particularly when utilizing simplistic, non-analytic, or unknown prior distributions. These limitations inhibit the VAE's ability to generate high-quality samples and provide clear, interpretable latent representations. This work introduces the Entropy Decomposed Variational Autoencoder (ED-VAE), a novel re-formulation of the ELBO that explicitly includes entropy and cross-entropy components. This reformulation significantly enhances model flexibility, allowing for the integration of complex and non-standard priors. By providing more detailed control over the encoding and regularization of latent spaces, ED-VAE not only improves interpretability but also effectively captures the complex interactions between latent variables and observed data, thus leading to better generative performance.
Multimodal Human-Autonomous Agents Interaction Using Pre-Trained Language and Visual Foundation Models
Mar 18, 2024In this paper, we extended the method proposed in [17] to enable humans to interact naturally with autonomous agents through vocal and textual conversations. Our extended method exploits the inherent capabilities of pre-trained large language models (LLMs), multimodal visual language models (VLMs), and speech recognition (SR) models to decode the high-level natural language conversations and semantic understanding of the robot's task environment, and abstract them to the robot's actionable commands or queries. We performed a quantitative evaluation of our framework's natural vocal conversation understanding with participants from different racial backgrounds and English language accents. The participants interacted with the robot using both spoken and textual instructional commands. Based on the logged interaction data, our framework achieved 87.55% vocal commands decoding accuracy, 86.27% commands execution success, and an average latency of 0.89 seconds from receiving the participants' vocal chat commands to initiating the robot's actual physical action. The video demonstrations of this paper can be found at https://linusnep.github.io/MTCC-IRoNL/.
M2CURL: Sample-Efficient Multimodal Reinforcement Learning via Self-Supervised Representation Learning for Robotic Manipulation
Jan 30, 2024



One of the most critical aspects of multimodal Reinforcement Learning (RL) is the effective integration of different observation modalities. Having robust and accurate representations derived from these modalities is key to enhancing the robustness and sample efficiency of RL algorithms. However, learning representations in RL settings for visuotactile data poses significant challenges, particularly due to the high dimensionality of the data and the complexity involved in correlating visual and tactile inputs with the dynamic environment and task objectives. To address these challenges, we propose Multimodal Contrastive Unsupervised Reinforcement Learning (M2CURL). Our approach employs a novel multimodal self-supervised learning technique that learns efficient representations and contributes to faster convergence of RL algorithms. Our method is agnostic to the RL algorithm, thus enabling its integration with any available RL algorithm. We evaluate M2CURL on the Tactile Gym 2 simulator and we show that it significantly enhances the learning efficiency in different manipulation tasks. This is evidenced by faster convergence rates and higher cumulative rewards per episode, compared to standard RL algorithms without our representation learning approach.