 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Visual-Tactile Representation Learning through Self-Supervised Contrastive Pre-Training
Paper and Code
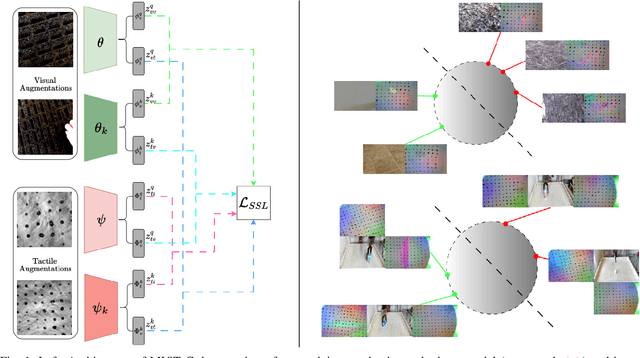
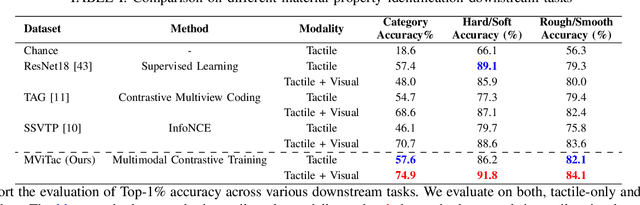

The rapidly evolving field of robotics necessitates methods that can facilitate the fusion of multiple modalities. Specifically, when it comes to interacting with tangible objects, effectively combining visual and tactile sensory data is key to understanding and navigating the complex dynamics of the physical world, enabling a more nuanced and adaptable response to changing environments. Nevertheless, much of the earlier work in merging these two sensory modalities has relied on supervised methods utilizing datasets labeled by humans.This paper introduces MViTac, a novel methodology that leverages contrastive learning to integrate vision and touch sensations in a self-supervised fashion. By availing both sensory inputs, MViTac leverages intra and inter-modality losses for learning representations, resulting in enhanced material property classification and more adept grasping prediction. Through a series of experiments, we showcase the effectiveness of our method and its superiority over existing state-of-the-art self-supervised and supervised techniques. In evaluating our methodology, we focus on two distinct tasks: material classification and grasping success prediction. Our results indicate that MViTac facilitates the development of improved modality encoders, yielding more robust representations as evidenced by linear probing assessments.